Based on Redis
- Redis
- Elasticsearch
- MySQL
- MySQL 其他类型题目链接
Redis
Redis 基础
Redis 底层有哪些数据结构
Redis 的底层的数据结构有 6 种,简单动态字符串、双向链表、整数数组、压缩列表、哈希表、跳表。
详见:redis 为什么这么快
rehash 的过程
首先因为大量的数据写入会造成 哈希冲突,所以需要增大哈希桶,进行 rehash 过程。
rehash 的时机:当写入元素过多达到一定比例,同时,Redis 目前没有执行 RDB 或者 AOF 操作时。
Redis 采取的是 渐进式 rehash 。
Redis 有两个全局 hash 表,当其中一个需要扩容时,将另一个哈希表扩大为当前需扩容哈希表的一倍。
在处理请求时会顺带进行数据迁移,后台也会启动周期性的任务进行迁移。
Redis 为什么是一个单线程的模型
这里的单线程是指 Redis 的网络 I/O 是由一个线程来完成的,这即是 Redis 对外提供键值存储服务的主要流程。其余的功能,如持久化、异步删除、集群同步都是额外的线程执行
主要原因也是因为多线程会存在加锁问题,多线程并发访问问题。
但是 Redis 采用了 I/O 多路复用技术,epoll 基于事件回调机制,针对不同的场景的发生调用相应的处理函数。这样Redis就不需要一直轮询时间的发生。
Redis 6.0 其实也支持了多线程模型,但 Redis 的多线程模型只用来处理网络读写请求,对于 Redis 的读写命令,依然是单线程处理。 详见: Redis 6.0 新特性:带你 100% 掌握多线程模型
zset 的底层实现
zset 是有序字典,自动去重的集合数据类型,其底层的实现为字典(dict)+ 跳表(skiplist)。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
Redis 的 key 过期机制和淘汰原理
Key 过期策略:
- 惰性删除:在取出键时才对键进行过期检查,如果发现过期了就会被删除
- 定期删除:定期每隔一段时间执行一次删除过期键的操作。
内存淘汰机制:
- volatile-lru:从已设置过期时间的数据集中挑选最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的进行数据淘汰
- volatile-random:从已设置过期时间的数据集中任意选择数据淘汰
- valatile-lfu:从已设置过期时间的数据集挑选使用频率最低的数据淘汰
- allkeys-lru:从数据(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-lfu:从数据(server.db[i].dict)中挑选使用频率最低的数据淘汰
- allkeys-random:从数据(server.db[i].dict)中随意淘汰
- no-enviction(驱逐):禁止驱逐数据,这也是默认策略。意思是当内存不足以容纳新入数据时,新写入操作就会报错,请求可以继续进行,线上任务也不能持续进行,采用no-enviction策略可以保证数据不被丢失。
详见:https://www.cnblogs.com/pinxiong/p/13288087.html
Redis的持久化机制
AOF :通过靠保存 Redis 服务器所执行命令日志的方式
- 优点:故障时,丢的数据量小。
- 缺点:体积大,恢复慢
RDB:通过内存快照的机制把内存中的数据集写入磁盘,也就是 Snapshot 快照(数据库中所有键值对数据)
- 优点:快照文件,数据紧凑,体积小,恢复时速度快。
- 缺点:服务器故障时,因为不能实时保存内存。所以有可能要丢失一段时间的数据。
详见:https://kiosk007.top/post/redis%E6%8C%81%E4%B9%85%E5%8C%96%E6%9C%BA%E5%88%B6/
https://cloud.tencent.com/developer/news/307359
Redis 如何实现高可用
Redis 实现高可用有三种部署模式:主从模式,哨兵模式,集群模式。
- 主从模式:Redis部署了多台机器,有主节点,负责读写操作,有从节点,只负责读操作。从节点的数据来自主节点,实现原理就是主从复制机制
- 哨兵模式:主从模式中,一旦主节点由于故障不能提供服务,需要人工将从节点晋升为主节点,同时还要通知应用方更新主节点地址。而哨兵模式就是为了解决该问题。
- 集群模式:哨兵模式基于主从模式,实现读写分离,它还可以自动切换,系统可用性更高。但是它每个节点存储的数据是一样的,浪费内存,并且不好在线扩容。因此,Cluster集群应运而生,它在Redis3.0加入的,实现了Redis的分布式存储。对数据进行分片,也就是说每台Redis节点上存储不同的内容,来解决在线扩容的问题。并且,它也提供复制和故障转移的功能。
redis 分布式锁
和单机模式上的锁机制类似,分布式锁同样可以用一个变量来实现。但是有两个要求,要求一:需要实现分布式的原子性。要求二:共享存储系统的可靠性。
假设一个变量 redis_lock,初始值是0。A来加锁,由0变1,此时B再来持锁,就持锁失败了。因为变量 redis_lock 已经是1了。再由于redis是一个单线程模型,redis会串行处理他们的请求。
使用 SETNS 和 DEL 两个命令实现加锁和释放锁。(SETNX 命令,它用于设置键值对的值。具体来说,就是这个命令在执行时会判断键值对是否存在,如果不存在,就设置键值对的值,如果存在,就不做任何设置)
| |
附加:
- 可以给变量加个过期时间。当客户端异常没有主动解锁时,可以自动删除锁。
- 为了保证锁不被其他客户端误释放,可以加一个 unique_value 。只有unique_value相同才可以操作。
| |
Redis如何应对并发访问
首先加锁可以解决并发访问问题,其次 Redis 提供两种原子操作的方法来实现并发控制,分别是单命令操作和Lua脚本。
其本质是将多个操作放到 Lua 脚本中原子执行
redis AOF 日志文件太大怎么办
AOF 重写。根据数据库的现状重新创建一个新的 AOF 文件,对每个键值对只记录最新的最终状态。
Redis 使用
Redis 有什么操作会导致其变慢
Redis 处理变慢主要原因有两个。
Redis 本身的值的读写是单线程,任意一个请求阻塞都会导致 Redis 请求变慢
并发量特别大时,单线程读写客户端 I/O 数据存在瓶颈。
可能导致慢的实际操作:
- 大 Key 操作,写入删除一个大Key会消耗更多的时间;
- HGETALL 等 O(N) 操作:
- 大量的 key 集中过期:
- 数据持久化,如 AOF 的 always 机制,主从全量同步生成 RDB 等。
针对问题1,除了需要开发人员从代码角度尽量避免大key,另一方面 Redis 在 4.0 推出 lazy-free 机制,将 大key 的释放内存的耗时操作都放到了异步线程中执行,避免对主线程的影响。
针对问题2,由于单个实例可能会造成在持久化时压力过大,可以考虑多实例。
Redis 在时间序场景的应用
场景:已有大量的pcap格式的网络数据包,当计算出网络数据流的重传数据包,则表示当前网络中出现了重传,并且可能出现了丢包。需要计算在时间序中哪个时间段出现的丢包较为频繁。丢包是否是单独某条连接的问题。
使用 zset 和 hash 表。
zset 可以获取一个时间范围的丢包信息。而hash表可以获取到某个具体时间的丢包信息。
| |
另外也可以基于 RedisTimeSeries 模块保存时间序列数据
详情:https://time.geekbang.org/column/article/282478
Redis缓存失效
直接参考: Redis基础-缓存设计
redis大key问题
直接参考:20道redis经典面试题
cluster
slot
我们都知道在集群模式下key是需要进行路由的,那就需要有路由策略,Redis Cluster并没有使用一致性hash的方案,而是使用分配slot的方式进行key路由。
其使用 crc16 做hash的方案。 没有采用 一致性 hash 的主要原因是防止 宕机雪崩。
Elasticsearch
什么是倒排索引
倒排索引包含两个部分:单词词典和倒排表。
- 单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系(单词词典一般比较大,通过 B+ 树或哈希拉链法实现,以满足高性能的插入与查询)
- 倒排表(Posting List):记录了单词对应的文档结合,由倒排索引组成。
- 文档ID
- 词频 TF - 该单词在文档中分词的位置。用于语句搜索
- 位置(Position)- 单词在文档中分词的位置,用于语句搜索
- 偏移(Offset)- 记录单词的开始结束位置,实现高亮显示。
详见:https://kiosk007.top/post/elasticsearch/
文档索引步骤顺序
- 客户端向某节点1 发送新建、索引、或者删除请求
- 节点1 根据文档 _id 判断文档所属分片0,而分片0 在节点2上,请求被转发至Node2。
- Node2 执行请求,成功后,请求并行同步到Node1 和 Node3 的副本分片。一旦所有的副本分片都报告成功,Node2 回复 协调节点,协调节点向客户端报告成功。
MySQL
myisam 和 innodb 的区别?
myisam 不支持事务、行级锁还有外键,所以一般用于有大量查询少量插入的场景。
innodb 是基于聚簇索引建立的,innodb 支持 事务还有外键。
MySQL 的索引有哪些?
按照数据结构来说,索引包含 B+树索引 和 Hash索引
MySQL的锁的类型有哪些呢?
mysql锁分为共享锁和排他锁,也叫做读锁和写锁。
读锁是共享的,可以通过lock in share mode实现,这时候只能读不能写。
写锁是排他的,它会阻塞其他的写锁和读锁。从颗粒度来区分,可以分为表锁和行锁两种。
表锁会锁定整张表并且阻塞其他用户对该表的所有读写操作,比如alter修改表结构的时候会锁表。
行锁又可以分为乐观锁和悲观锁,悲观锁可以通过for update实现,乐观锁则通过版本号实现。
事务的基本特性和隔离级别
事务基本特性ACID分别是:
原子性(atomicity):一个事务中的操作要么全部成功,要么全部失败
一致性(consistency):数据库总是从一个一致性的状态转换到另一个一致性的状态。(比如A给B转帐100元,sql 执行失败,A不会损失100,B也不会多出100)
隔离性(isolation):一个事务的修改在最终提交之前,对其他事务不可见
持久性(durability):事务一旦提交,所做的修改就会永久的保存到数据库中。
隔离性有4个隔离级别,分别是:
- read uncommit 读未提交,可能会读到其他事务未提交的数据,也叫做脏读。
- read commit 读已提交,同一次事务中两次读取结果不一致,叫做不可重复读。
- repeatable read 可重复读,MySQL的默认级别,就是每次读取结果都一样,但是会产生幻读。
- serializable 串行,一般不会使用,他会给每一行读数据加锁,会导致大量超时问题。
MySQL 主从同步是如何实现的
主从同步原理:
- master 提交完事务后,写入 binlog
- master 创建dump线程,推送binglog 到 slave
- slave 再开启一个IO线程读取同步过来的master的binlog,记录到relay log 中继日志中
- slave 再开启一个 SQL 线程读取 relay log 事件并在 slave 执行,完成同步
- slave 记录自己的binlog
由于mysql默认的复制方式是异步的,主库把日志发送给从库后不关心从库是否已经处理,这样会产生一个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,日志就丢失了。由此产生两个概念。
全同步复制
主库写入binlog后强制同步日志到从库,所有的从库都执行完成后才返回给客户端,但是很显然这个方式的话性能会受到严重影响。
半同步复制
和全同步不同的是,半同步复制的逻辑是这样,从库写入日志成功后返回ACK确认给主库,主库收到至少一个从库的确认就认为写操作完成。
MySQL事务中什么是幻读
幻读是指事务A执行过程中由于事务B并发插入了一条新的数据记录。事务A两次读数据的内容不一样,出现了“虚幻”的新记录。
MySQL 的 InnoDB 引擎在RR级别下可以防止幻读的发生
- 在快照读(snapshot read)的情况下,MySQL 通过 MVCC(多版本并发控制)来避免幻读
快照读,读取的是记录的可见版本 (有可能是历史版本),不用加锁。主要应用于无需加锁的普通查询(select)操作。
- 在当前读(current read)的情况下,MySQL 通过next-key lock 来避免幻读
当前读,读取的是记录的最新版本,并且会对当前记录加锁,防止其他事务发修改这条记录。加行共享锁(SELECT … LOCK IN SHARE MODE )、加行排他锁(SELECT … FOR UPDATE / INSERT / UPDATE / DELETE)的操作都会用到当前度。
InnoDB支持三种行锁定的方式。
- 行锁(Record Lock):锁直接加在索引记录上面(无索引项时蜕变成表锁)
- 间隙锁(Gap Lock):锁定索引记录间隙,确保索引记录的间隙不变,间隙锁是针对事务隔离级别为可重复读或以上级别。
- Next-Key Lock:行锁和间隙锁组合起来就是 Next-Key Lock
参考: https://www.jianshu.com/p/d5c2613cbb81
什么是Next-Key Lock
InnoDB采用Next-Key Lock解决幻读问题。 Next-Key Lock 是行锁和间隙锁组合起来。
Next-Key Lock 的规则:
- 原则1:加锁的基本单位是 next-key lock, next-key lock 是前开后闭的区间。
- 原则2:只有访问到的对象才会加锁
优化
- 优化1:命中唯一索引时,退化为行锁。命中普通索引时,左右两边的GAP Lock 和 行锁。
- 优化2:索引上的等值查询时,向右遍历时且最后一个值不满足等值条件的时候, 退化为GAP锁。
参考: MySQL实战45-为什么只改一行的语句,锁这么多、Next-Key Lock 的规则
MySQL的日志 undo log \ redo log \ binlog
- undo log除了实现MVCC外,还用于事务的回滚。
- binlog,是mysql服务层产生的日志,常用来进行数据恢复、数据库复制
- redo log记录了数据操作在物理层面的修改,mysql中使用了大量缓存,缓存存在于内存中,修改操作时会直接修改内存,而不是立刻修改磁盘,当内存和磁盘的数据不一致时,称内存中的数据为脏页(dirty page)。为了保证数据的安全性,事务进行中时会不断的产生redo log,在事务提交时进行一次flush操作,保存到磁盘中, redo log是按照顺序写入的,磁盘的顺序读写的速度远大于随机读写。当数据库或主机失效重启时,会根据redo log进行数据的恢复,如果redo log中有事务提交,则进行事务提交修改数据。这样实现了事务的原子性、一致性和持久性。
什么是 MVCC
MVCC 多版本控制,其是为了提高并发,读写之间不冲突,就是读取数据时通过一种类似快照的方式将数据保存下来,这样读锁就和写锁不冲突了,不同的事务session会看到自己特定版本的数据。 只在 READ COMMITTED 和 REPEATABLE READ 两个级别下工作。
- 实现原理 InnoDB中通过undo log实现了数据的多版本,而并发控制通过锁来实现。每新增一个事务就增加一个trx_id,即在版本链上增加了一个undo log. ReadView中主要就是有个列表来存储我们系统中当前活跃着的读写事务,也就是begin了还未提交的事务。通过这个列表来判断记录的某个版本是否对当前事务可见 MySQL 的 MVCC 通过版本链,实现多版本,可并发读-写,写-读。通过ReadView生成策略的不同实现不同的隔离级别。
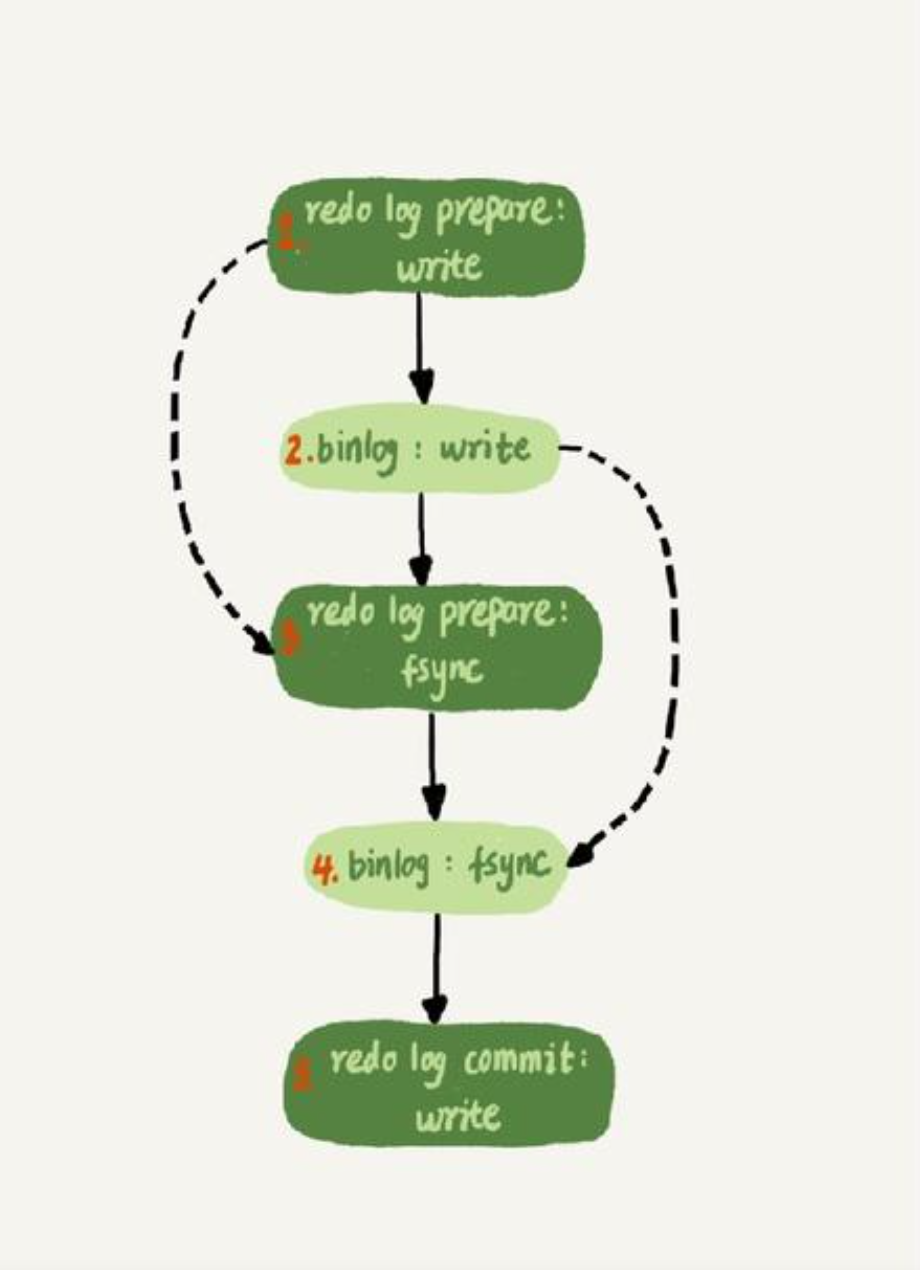
什么是 MySQL 的两段式提交,为什么必须要“两段式”提交?
- 什么是两段式提交
当有数据修改时,会先将修改 redo log cache 和 binlog cache 然后再刷入到磁盘形成 redo log file,当 redo log file 全部刷入磁盘时(prepare 状态)和提交成功后才能将 binlog cache刷入磁盘。当 binlog 全部刷新到磁盘后会形成一个 xid,然后redo log file上打上 commit 标志(commit 阶段)
- 为什么要两段式提交
在没有两段式提交的情况下。
如果先写redo log,后 binlog,在 redo log 写完,binlog 还没写完时数据库崩溃,当恢复后,主数据库被修改了,但是 binlog 并没有该语句,因此从库会丢失该更新导致主从不一致。
如果先写 binlog,后写 redolog,在 binlog 写完,redo log 还没写完时崩溃,恢复后从库比主库多了一条更新,导致主从不一致。
有了两段式提交。
redo 写入时崩溃,因为此时 binlog 还没有写入,恢复数据不受影响
redo 写好后,binlog 写入时崩溃,这时的redo 是 prepare 状态,还没有提交,恢复时事务会回滚,binlog没有记录,不影响。
redo 写好,binlog 也写好了,但是没有commit时崩溃了,这时判断对应事务的binlog是否存在并完整
- 如果存在并完整则提交
- 如果binlog 不存在或者不完整,会恢复事务提交之前的状态。
redo 已经有了commit 标识,则直接提交事务,同时因为binlog有记录,则恢复数据不受影响。
MySQL 索引为什么用B+树
首先二叉树必须是平衡的才有比较高的查询效率,如果不平衡最差会退化成链表。
B树是多叉树又名平衡多路查找树(查找路径不止两个), 相对平衡二叉树在节点空间的利用率上进行了改进,B树在每个节点保存了更多的数据,减少了树的高度从而提升了查找的性能,使用B树的数据库,一般节点大小是16K,这是考虑到磁盘数据存储是采用块的形式存储,每个块大小为16K,每次对磁盘进行 IO 数据读取时,一个磁盘IO可以读取B树的一个节点。
B+树是对B树的一个改进。主要是查询的稳定性和数据排序方面更友好。
B+树的非叶子节点不保存具体数据,之保存关键字的索引,而所有的数据最终会保存到叶子节点。
其关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针,因为叶子节点都是有序排列的,所以B+树对数据的排序支持有着更好的支持。
参考:https://zhuanlan.zhihu.com/p/27700617 (里面有图,更助于理解)
另外关于树的高度,一般来说一个千万量级数据的B+树树高就3-5 左右。(https://www.cnblogs.com/songpingyi/p/10730156.html) B+ 树的深度比 AVL、红黑树低,所以对磁盘IO比较友好。
树数据结构模拟: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
MySQL索引为什么会有最左前缀匹配原则
由于联合索引构建存储的方式是根据第一个索引列“单调递增”排序,如果第一列相等再根据第二列单调递增排序,以此类推。。。 也就是说,对于(b,c,d)联合索引来说,相当于创建了(b)、(b,c)、(b,c,d) 三个索引。