什么是 NUMA
最近再看虚拟化相关内容的时候注意到 KVM 支持 SMP 和 NUMA 多 CPU 架构的主机和客户机。注意到CPU的模型概念。
之前其实有听到过 CPU 模型对高性能计算的影响。但是又不清楚其中的原理。高性能云服务可能会引入 numad 守护进程来优化 NUMA 的资源分配。
Linux man手册中对numad的定义为A user-level daemon that provides placement advice and process management for efficient use of CPUs and memory on systems with NUMA topology.(为高效利用CPU和内存提供布局建议和进程管理功能的用户态守护进程。)
本文将介绍一下什么是 numa ,以及到底有什么用。

什么是 NUMA
过去,处理器被设计为 对称多处理 (Symmetrical Multi-Processing, SMP) 或 统一内存架构 (Uniform Memory Access, UMA) 架构。这意味所有的处理器通过一个总线共享对系统中所有可用内存的访问。所有的内存组成一整块统一地址空间,软件无论运行在哪一个 CPU 上,只要按照唯一的内存地址就能访问到相同的内存,所有的 CPU 访问所有的内存单元耗时是相同的。
但是现在,随着需要大量的数据计算的应用程序的出现,内存的访问速度越来越高。而在这种 UMA 机器上,由于多个 CPU在单个总线上访问内存,共享总线上的负载更大,并且由于总线带宽有限,多个 CPU 之间存在延迟和冲突等挑战。
在这个以数据为中心的处理时代,对 CPU 和 内存之间的要求速度很高,催生了一种名为 非统一内存访问 (NUMA) 或者准确的说是 缓存一致性 Numa (ccNUMA) 的新架构。在这种新架构中,每个处理器都有一个本地内存库,他可以更近的访问(更低的延迟)。这意味着,我们将完整可用的内存分配给每个单独的 CPU,这成为它们自己的本地内存,如果任何CPU想要更多的内存,它们仍可以从其他 CPU 访问内存,但延迟会稍微高一些。
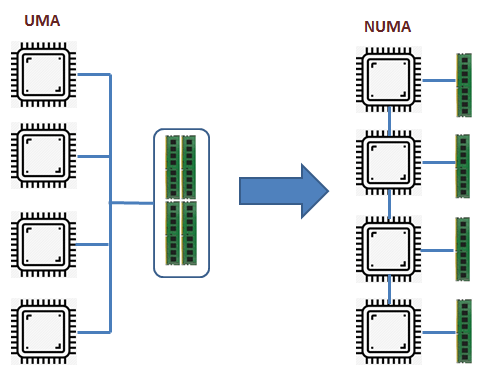
今天,处理器是如此之快,以至于他们通常需要将内存直接连接到它们所在的插槽上,因此,与远程内存访问相比,从单个处理器到本地内存的内存访问不仅具有更低的延迟,而且不会导致互连和远程内存控制器的争抢。
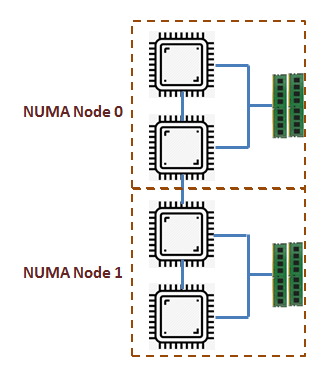
有一部分 CPU 一起访问他们自己的本地内存,所以可有几个这样的 CPU 和 内存组,被称为 NUMA 节点。
numa 相关命令
numactl(英文全拼:NUMA Control)命令用于查看当前服务器的 NUMA 节点配置和运行状态,可通过该工具将进程绑定到指定 CPU core,由指定 CPU core 来运行对应进程。
numactl 通常不会预先安装,但可在大多数 Linux 发行版的默认仓库中找到。例如,在 Debian/Ubuntu 系统上可以使用如下命令进行安装。(安装完成后会有两个命令:numactl 和 numastat)
sudo apt install numactl示例
- 查看当前的 NUMA 运行状态
$ numastat
node0
numa_hit 324518346
numa_miss 0
numa_foreign 0
interleave_hit 3429
local_node 324518346
other_node 0字段说明:
numa_hit表示节点内 CPU 核访问本地内存的次数。numa_miss表示节点内核访问其他节点内存的次数。跨节点的内存访问会存在高延迟从而降低性能,因此 numa_miss 的值应当越低越好,如果过高,则应当考虑绑核。
- 查看当前服务器的 NUMA 配置
$ numactl -H
available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7
node 0 size: 15726 MB
node 0 free: 799 MB
node distances:
node 0
0: 10- 将应用程序 test 绑定到 0~7 核运行
$ numactl -C 0-7 ./test参考: