Redis基础
Redis 是一种基于 key-value 的NoSQL数据库。Redis的全称是 Remote Dictionary Server。是一个基于内存的存储系统,可以用作缓存和消息中间件。支持多种类型的数据结构,如字符串(string)、哈希(hash)、列表(list)、集合(set)、有序集合(sorted set),在其基础之上还有一些扩展的数据结构,如位图(bitmap)、HyperLogLog、GEO 等数据结构。其内置了复制(replication)、事务(transaction)和磁盘持久化策略(persistence),并通过 Redis 哨兵(Sentinel)和自动分区(Cluster)提供高可用性。
简介
速度快
正常情况下,Redis 执行命令的速度非常快,官方给出的数字是读写性能可达10万/s,这是因为Redis的内部实现
- Redis 是一个内存数据库,相较于传统的硬盘存储的数据库具有较高的读写性能。
- 底层为 C 语言实现,针对不同的数据结构做了专门的设计和优化
- 使用单线程结构+IO多路复用技术(Redis6.0使用多线程处理网络IO和命令执行)不需要频繁的进行线程间切换,且无需考虑加锁的问题,不存在死锁导致的消耗。https://redis.io/docs/getting-started/faq/ 是官方做出的解释。
功能丰富
相较于其他的内存数据库(Memcached),Redis 提供丰富的数据结构,和一系列的额外功能。
- 键过期功能,可以用来实现缓存
- 发布订阅功能,可以用来实现基本消息队列
- 提供了简单的事务功能(不支持回滚),能在一定程度上保证事务的特性。
- 支持 Lua 脚本功能,可以利用Lua创造出新的原子命令,处理复杂的业务逻辑。
- 提供了流水线(PipeLine)功能,能将一批命令一次性传到 Redis,减少网络的开销。
持久化
一般来说不应该将重要数据放到内存中,应考虑发生断电或者机器故障导致的数据丢失。目前 Redis 提供两种可持久化方案:RDB 和 AOF ,可以用这两种策略将内存的数据保存到硬盘中,这就保证了数据的可知就化
Redis4.0 之后的版本还提供了 RDB-AOF 混合持久化格式,结合了两种持久化存储的优点。
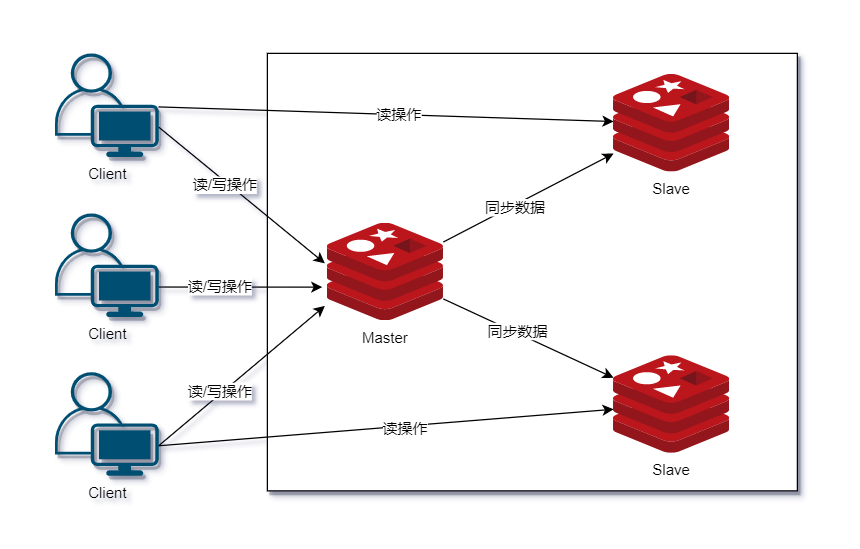
主从复制
Redis 提供了主从复制的功能(Memcache不支持复制功能),实现了多个相同数据的Redis副本,复制功能是分布式 Redis的基础
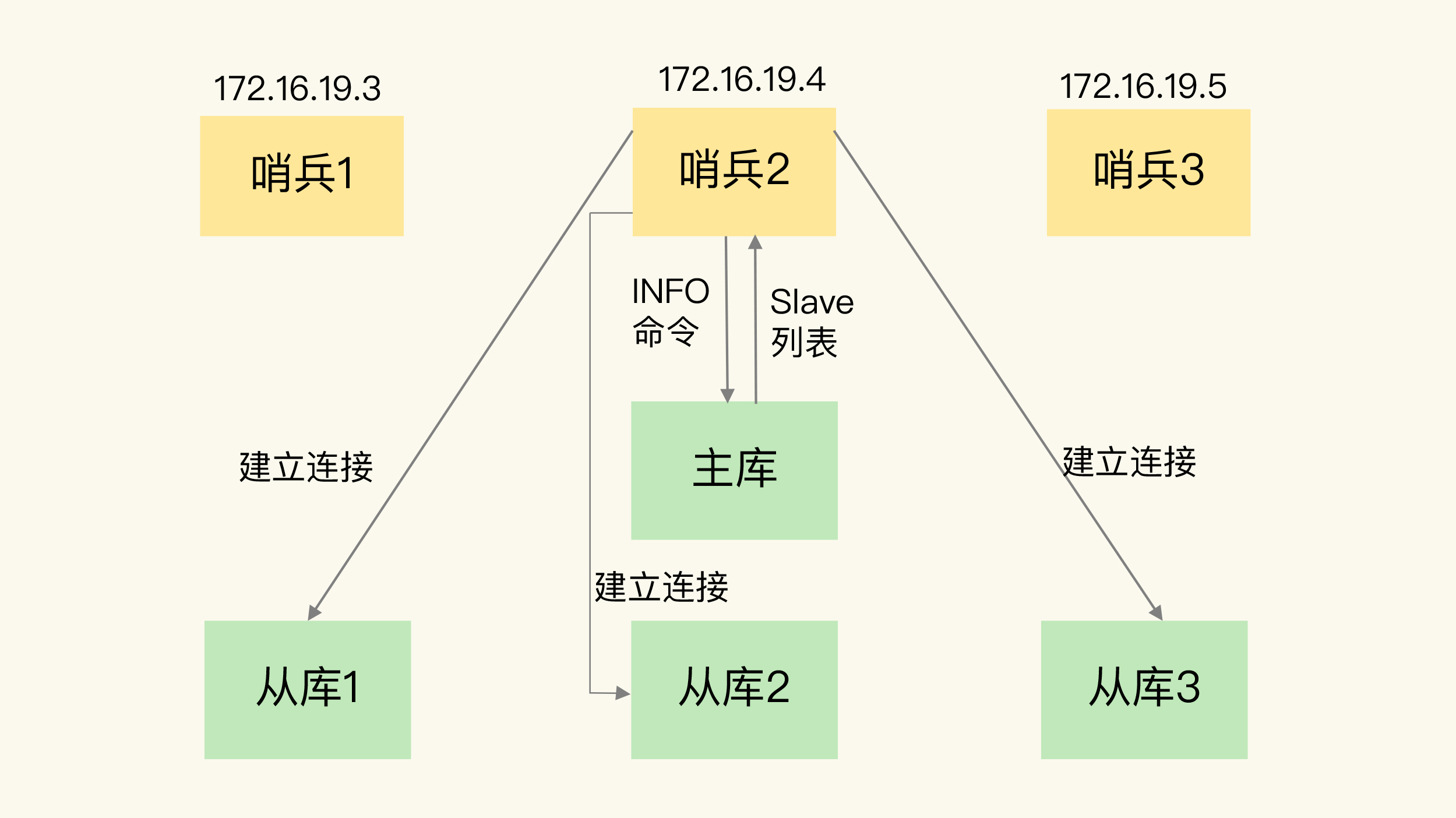
高可用及分布式
Redis从2.8版本开始正式提供了高可用实现的 Redis Sentinel,能够保证 Redis 节点的故障发现和故障自动转移。
Redis 从 3.0版本正式提供了分布式实现Redis Cluster,它是Redis真正的分布式实现,提供了高可用性、读写和容量的扩展。
使用
安装及启动
- 包管理工具
# ubuntu/debian
sudo apt-get install redis-server
# macos
brew install redis
# 指定版本
brew install redis@x.x- 编译安装
# 最新稳定版本redis-6.2.6
wget https://download.redis.io/releases/redis-6.2.6.tar.gz
tar xzf redis-6.2.6.tar.gz
cd redis-6.2.6
make
make install- 启动
# 指定参数
redis-server --configKey1 configValue1 --configKey2 configValue2
# 指定端口
redis-server --port 6380
# 以守护进程运行
redis-server --daemonize yes
# 指定log文件
redis-server --logfile $(LOG_FILE)
# 设置密码
redis-server --requirepass xxx常用命令
字符串
Redis 字符串数据类型的相关命令用于管理 redis 字符串值
redis 127.0.0.1:6379> SET runoobkey redis
OK
redis 127.0.0.1:6379> GET runoobkey
"redis"https://www.runoob.com/redis/redis-strings.html
哈希
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
127.0.0.1:6379> HMSET runoobkey name "redis tutorial" description "redis basic commands for caching" likes 20 visitors 23000
OK
127.0.0.1:6379> HGETALL runoobkey
1) "name"
2) "redis tutorial"
3) "description"
4) "redis basic commands for caching"
5) "likes"
6) "20"
7) "visitors"
8) "23000"https://www.runoob.com/redis/redis-hashes.html
列表
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
redis 127.0.0.1:6379> LPUSH runoobkey redis
(integer) 1
redis 127.0.0.1:6379> LPUSH runoobkey mongodb
(integer) 2
redis 127.0.0.1:6379> LPUSH runoobkey mysql
(integer) 3
redis 127.0.0.1:6379> LRANGE runoobkey 0 10
1) "mysql"
2) "mongodb"
3) "redis"https://www.runoob.com/redis/redis-lists.html
集合
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
集合对象的编码可以是 intset 或者 hashtable。
redis 127.0.0.1:6379> SADD runoobkey redis
(integer) 1
redis 127.0.0.1:6379> SADD runoobkey mongodb
(integer) 1
redis 127.0.0.1:6379> SADD runoobkey mysql
(integer) 1
redis 127.0.0.1:6379> SADD runoobkey mysql
(integer) 0
redis 127.0.0.1:6379> SMEMBERS runoobkey
1) "mysql"
2) "mongodb"
3) "redis"https://www.runoob.com/redis/redis-sets.html
有序集合
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
redis 127.0.0.1:6379> ZADD runoobkey 1 redis
(integer) 1
redis 127.0.0.1:6379> ZADD runoobkey 2 mongodb
(integer) 1
redis 127.0.0.1:6379> ZADD runoobkey 3 mysql
(integer) 1
redis 127.0.0.1:6379> ZADD runoobkey 3 mysql
(integer) 0
redis 127.0.0.1:6379> ZADD runoobkey 4 mysql
(integer) 0
redis 127.0.0.1:6379> ZRANGE runoobkey 0 10 WITHSCORES
1) "redis"
2) "1"
3) "mongodb"
4) "2"
5) "mysql"
6) "4"https://www.runoob.com/redis/redis-sorted-sets.html
HyperLogLog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
redis 127.0.0.1:6379> PFADD runoobkey "redis"
1) (integer) 1
redis 127.0.0.1:6379> PFADD runoobkey "mongodb"
1) (integer) 1
redis 127.0.0.1:6379> PFADD runoobkey "mysql"
1) (integer) 1
redis 127.0.0.1:6379> PFCOUNT runoobkey
(integer) 3https://www.runoob.com/redis/redis-hyperloglog.html
发布/订阅
Redis支持简单的消息机制,可以使用pub/sub命令实现
# 发布消息
PUBLISH channel message
# 订阅频道
SUBCRIBE channel1 [channel2 ...]
# 取消订阅
UNSUBSCRIBE channel1 [channel2 ...]
# glob风格的模型订阅模式,可以实现广播
PSUBCRIBE pattern1 [pattern2 ...]
# 取消模式订阅
PUNSUBCRIBE pattern1 [pattern2 ...]应用
缓存
缓存设计

收益:数据存在内存中,读速快,同时降低了后端访问的负担。
成本:数据不一致,缓存层会存在数据不一致的问题。为了解决这个问题代码逻辑需要变得更复杂。
缓存更新策略
- 依赖淘汰策略剔除数据
当内存超过预先设定 maxmemroy 配置的值时,Redis 会使用自身的 LRU/LFU 算法剔除数据。无法控制数据什么时候删除。
- 依赖过期策略剔除数据
对每个数据都设置超时时间,到期后Redis会自动删除数据,虽然在一定的时间窗口内会存在数据不一致的问题,但可以保证最终一致性。如果业务不要求强一致性,就可以采用这种策略。
- 主动更新
- 先写缓存,再写数据库(不建议使用)
写缓存成功,写数据库失败,客户端会读到脏数据。
- 先写数据库,再写缓存(不是特别建议)
比如如下的场景。
| 客户A | 客户B |
|---|---|
| 客户A更新数据库 | |
| 客户B更新数据库 | |
| 客户B更新缓存 | |
| 客户A更新缓存 |
客户B更新数据更晚,但是从缓存中取到的是客户A更新的数据。
缓存穿透、缓存击穿、缓存雪崩
- 缓存穿透
使用 Redis 大部分情况是通过 Key 查询对应的值,加入发送的请求传进来的Key不存在Redis中,那么就查不到缓存,查不到就会去数据库查,如果数据库也不存在的话,大量的请求就会打到数据库上,这种现象叫做缓存穿透,这种现象一般是由于程序逻辑错误或者恶意请求导致的。
解决方案:缓存空值、使用布隆过滤器
- 缓存击穿
缓存击穿是一个热点的 Key,有大并发集中对其进行访问,但是突然这个Key失效了,导致大并发打在数据库上,导致数据库压力剧增。这种现象叫做缓存击穿。
解决方案:
- 不设置失效时间
- 使用分布式锁,保证对于一个Key同时只有一个线程去查询后端的服务。如果是非分布式场景,或使用 singleflight
- 缓存雪崩
当某个时刻出现大规模的缓存失效的情况,会导致大量的请求直接打在数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。即便重启了数据库,新的流量还是会把数据库打死
解决方案:
- 过期时间加一个随机值,避免大量的key同时失效
- 使用 Redis 集群,增加系统可用性
分布式锁
redis上运行的多线程程序来说,锁本身可以使用一个变量表示。变量为0便是没有线程获取到锁,变量变为1时,表示有线程获取到锁。
使用 SETNX 命令,他用于设置键值对的值,具体来说就是在执行命令时判断键值对是否存在,如果不存在,就设置键值对的值,如果存在,就不做任何操作设置。
// 加锁
SETNX lock_key 1
// 业务逻辑
DO THINGS
// 释放锁
DEL lock_key不过这有一个问题,一个具体的场景,如果客户端A执行了SETNX命令加锁后,客户端B执行了DEL命令释放锁。此时,客户端A加的锁就被误释放了。
所以需要value能标识是哪个客户端此时持有锁。
// 加锁, unique_value作为客户端唯一性的标识
SET lock_key unique_value NX PX 10000unique_value 是客户端的唯一标识,可以用一个随机生成的字符串来表示,PX 10000 标识 lock_key 会在 10s 后过期,以免客户端在此期间发生异常而无法正常释放锁。