LLM大模型 - 从0认识RAG
在讨论RAG技术之前,我们先看在开发大语言模型(LLM)应用时会遇到的典型场景问题。比如,当设计一个 LLM 问答应用,当模型回答用户的特定领域问题时,尽管大模型再厉害,也没办法提供准确的答案,而且大模型的训练数据也不可能总是最新的,模型无法及时提供最新的答案,这种现象在 LLM 应用中较为常见。
除此之外,还有其他的诸多问题。总结为以下几个问题:
- 领域知识缺乏: 大模型的知识来源于训练数据,而训练数据来自于互联网上的爬虫获取到的内容,无法覆盖特定领域的高度专业化的内部知识。
- 信息过时: 模型的训练周期长、花费大,模型一旦完成训练,就难以获取和处理新信息。
- 幻觉问题: 模型都是基于概率生成文本,有时会输出看似合理但实际错误的答案。
- 数据安全性: 在关键领域,如保密单位,企业内部,需要保证数据的安全。
为了解决上述问题,RAG(Retrieval-Augmented Generation,检索增强生成)技术应运而生。通过将非参数化的外部知识库、文档与大模型相结合,RAG 使模型在生成内容之前先检索一遍相关信息。从而弥补模型在知识专业性和实效性的不足。
RAG 技术的定义
RAG 技术是一种结合检索与生成的自然语言处理(NLP)模型架构。旨在提升生成式模型在处理关键开放领域的回答,对话生成等复杂任务中的性能。RAG 通过引入外部知识库,利用检索模块(Retriever)从大量文档中提取相关信息,并将这些信息传递给生成模块(Generator),从而生成更准确且有用的回答。
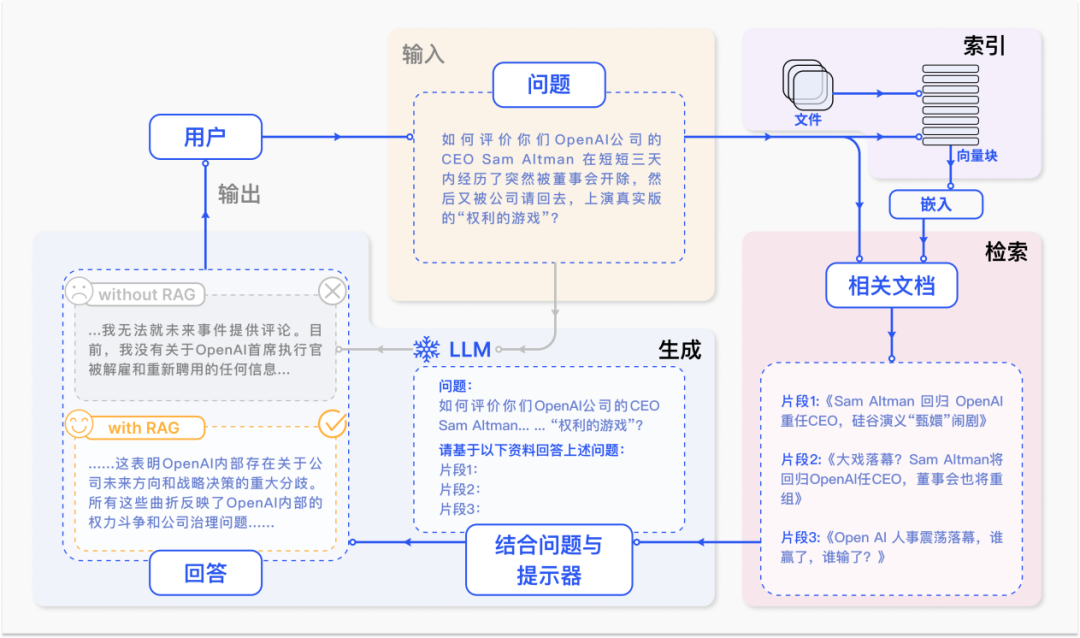
RAG 标准流程由 索引 (Indexing) 、检索 (Retriever) 和 生成(Generation)三个核心阶段组成。
LangChain:提供用于构建 LLM RAG 的应用程序框架。
索引阶段,通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)中。
检索阶段,用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量书库中检索出最相关的文本块。
生成阶段,检索到相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。
RAG索引 - 文档解析
RAG(检索增强生成)系统的首要步骤是索引(Indexing)流程中的文档解析。
RAG 系统的应用场景主要集中在专业领域和企业场景。这些场景中,除了关系型和非关系型数据库,更多的数据以 PDF、TXT、Word、PPT、Excel、CSV、Markdown、XML、HTML 等多种格式存储。尤其是 PDF 文件,凭借其统一的排版和多样化的结构形式,成为了最为常见的文档数据存储与交换格式。
LangChain 提供了一套功能强大的文档加载器(Document Loaders),帮助开发者轻松地将数据源中的内容加载为文档对象。LangChain 定义了 BaseLoader 类和 Document 类,其中 BaseLoader 类负责定义如何从不同数据源加载文档,而 Document 类则统一描述了不同文档类型的元数据。
RAG索引 - 分块策略
文档通常包含丰富的上下文信息和复杂的语义结构,通过将文档分块,模型可以更有效地提取关键信息,并减少不相关内容的干扰。分块的目标在于确保每个片段在保留核心语义的同时,具备相对独立的语义完整性,从而使模型在处理时不必依赖广泛的上下文信息,增强检索召回的准确性。
分块策略
最佳的分块策略取决于具体的应用场景,而非行业内的统一标准。根据场景中文档内容的特点和查询问题的需求,选择最合适该场景的分块策略,以确保 RAG 系统中大模型能够更精确地处理和检索数据。
多种分块策略从本质上来看,由以下三个关键组成部分构成:
- 大小:每个文档块所允许的最大字符数。
- 重叠:在相邻数据块之间,重叠字符的数量。
- 拆分:通过段落边界、分隔符、标记,或语义边界来确定块边界的位置。
上述三个组成部分共同决定了分块策略的特性及其适用场景。基于这些组成部分,常见的分块策略包括:固定大小分块(Fixed Size Chunking)、重叠分块(Overlap Chunking)、递归分块(Recursive Chunking)、文档特定分块(Document Specific Chunking)、语义分块(Semantic Chunking)、混合分块(Mix Chunking)。下面我将对这些策略逐一进行介绍。
下面是一个可视化的 chunk 分块的网站
固定大小分块(Fixed Size Chunking)
最基本的方法是将文档按固定大小进行分块,通常作为分块策略的基准线使用。

问题:
不考虑内容上下文,可能在句子或段落中断内容,导致无意义的文本块,例如上面图示中的“大模 / 型”“边际成 / 本”等词组被中断;
重叠分块(Overlap Chunking)
通过滑动窗口技术切分文本块,使新文本块与前一个块的内容部分重叠,从而保留块边界处的重要上下文信息,增强系统的语义相关性。虽然这种方法增加了存储需求和冗余信息,但它有效避免了在块之间丢失关键语义或句法结构。
递归分块(Recursive Chunking)
通过预定义的文本分隔符(如换行符\n\n、\n ,句号、逗号、感叹号、空格等)迭代地将文本分解为更小的块,以实现段大小的均匀性和语义完整性。此过程中,文本首先按较大的逻辑单元分割(如段落 \n\n),然后逐步递归到较小单元(如句子 \n 和单词),确保在分块大小限制内保留最强的语义片段。

这种方法适用于需要逐层分析的文本文档或需要分解成长片段、长段落的长文档,如研究报告、法律文档等。不过仍有可能在块边界处模糊语义,容易将完整的语义单元切分开。
文档特定分块(Document Specific Chunking)
根据文档的格式(如 Markdown、Latex、或编程语言如 Python 等)进行定制化分割的技术。此方法依据文档的特定格式和结构规则,例如 Markdown 的标题、列表项,或 Python 代码中的函数和类定义等,来确定分块边界。通过这种方式,确保分块能够准确反映文档的格式特点,优化保留这些语义完整的单元,提升后续的处理和分析效果。
语义分块(Semantic Chunking)
基于文本的自然语言边界(如句子、段落或主题中断)进行分段的技术,需要使用 NLP 技术根据语义分词分句,旨在确保每个分块都包含语义连贯的信息单元。语义分块保留了较高的上下文保留,并确保每个块都包含连贯的信息,但需要更多的计算资源。常用的分块策略有 spaCy 和 NLTK 的 NLP 库,spaCy 适用于需要高效、精准语义切分的大规模文本处理,NLTK 更适合教学、研究和需要灵活自定义的语义切分任务。
混合分块(Mix Chunking)
混合分块是一种结合多种分块方法的技术,通过综合利用不同分块技术的优势,提高分块的精准性和效率。例如,在初始阶段使用固定长度分块快速整理大量文档,而在后续阶段使用语义分块进行更精细的分类和主题提取。根据实际业务场景,设计多种分块策略的混合,能够灵活适应各种需求,提供更强大的分块方案。
在 Go 中,https://github.com/tmc/langchaingo/tree/main/textsplitter 继承了各种分块代码-
在 Python 中,
嵌入模型(Embedding Model)
在 RAG(检索增强生成)系统中,嵌入模型(Embedding Model) 是一个至关重要的组件,它在整个流程中扮演着“文本理解与转换”的核心角色。

嵌入模型是什么?
嵌入模型是一种特殊的深度学习模型,它的主要功能是将文本(无论是单词、句子、段落还是整个文档)转换成一个高维度的、连续的数字向量(Vector)。这个数字向量被称为嵌入(Embedding)。
你可以把这个向量理解为文本的一种“数值表示”或“数字指纹”。
核心功能
嵌入模型的核心功能可以概括为:将语义信息编码为数值,实现文本的“计算机可读”表示,并在此基础上进行高效的语义检索。
具体来说,它实现以下核心功能:
语义编码:
将非结构化文本转化为结构化数据: 文本对于计算机来说是难以直接处理的非结构化数据。嵌入模型将这些文本转化为计算机能够理解和计算的、具有数学属性的向量。
捕捉语义相似性: 这是最关键的一点。经过训练的嵌入模型能够学习到词语、句子、甚至段落之间的语义关系。这意味着在向量空间中,语义上相似的文本(例如,“猫”和“小猫”,“汽车”和“车辆”)它们的向量在几何距离上会更接近。而语义不相关的文本(例如,“猫”和“宇宙飞船”)它们的向量距离会很远。
支持高效语义检索(向量搜索):
- 一旦文本被转化为向量,我们就可以利用高效的向量数据库技术(如 Faiss、Annoy、qdrant、HNSWlib 等)进行相似度搜索。
- 当用户提出查询时,这个查询也会被同一个嵌入模型转化为向量。然后,通过计算查询向量与知识库中所有文档向量之间的相似度(通常是余弦相似度),就可以快速找到语义最相关的文档片段。
具体作用
在 RAG 系统的不同阶段,嵌入模型发挥着具体的作用:
- 知识库构建阶段(离线):
- 你需要将大量的非结构化知识数据(例如,公司的内部文档、网页内容、书籍、文章等)进行预处理,通常会切分成较小的、有意义的文本块(Chunk)。
- 然后,使用嵌入模型对每一个文本块生成对应的嵌入向量。
- 这些文本块及其对应的嵌入向量会被存储到一个专门的 向量数据库(Vector Database) 中。这个数据库是 RAG 系统进行知识检索的基础。
- 用户查询处理阶段(在线):
- 当用户向 RAG 系统提出一个问题或查询时,这个查询文本也会被相同的嵌入模型进行处理,生成一个查询嵌入向量。
- 初步检索(召回)阶段:
- 将用户查询的嵌入向量提交给向量数据库。
- 向量数据库会通过计算向量之间的相似度,快速从海量的知识库中找出与查询向量最相似的Top-K个文档嵌入(以及它们对应的原始文本块)。这个过程被称为初步检索或召回(Retrieval/Recall)。这些被召回的文档片段是提供给 LLM 的候选知识来源。
混合检索(Hybrid Retrieval)
RAG(Retrieval-Augmented Generation,检索增强生成)中的 混合检索(Hybrid Retrieval) 是指结合多种不同的信息检索技术或策略,以更全面、准确地找到与用户查询相关的外部知识或文档,从而提高大型语言模型(LLM)生成回答的质量和相关性。
简单来说,就是“取长补短,强强联合”。
为什么需要混合检索?
传统的检索方法通常分为两类:
- 稀疏检索(Sparse Retrieval)/ 关键字检索:
- 原理: 依赖于精确的关键字匹配,例如TF-IDF、BM25算法。它会在文档中查找与查询词完全相同或高度相关的词语。
- 优点: 对于查找包含特定名称、代码、日期等精确信息非常有效,速度快,计算成本相对较低。
- 缺点: 无法理解语义上的相似性。例如,如果你搜索“最好的跑步鞋”,它可能找不到包含“马拉松训练鞋”的文档,即使它们是语义相关的。它对同义词、语序变化、多义词等不敏感。
- 稠密检索(Dense Retrieval)/ 语义检索:
- 原理: 将查询和文档都转换为高维向量(称为嵌入或Embeddings),然后通过计算这些向量之间的相似度(如余弦相似度)来查找语义上最相关的文档。
- 优点: 能够理解查询的深层含义和上下文,即使文档中没有完全匹配的关键词,也能找到语义相关的结果。例如,“最好的跑步鞋”可以匹配到“马拉松训练鞋”。
- 缺点: 对特定、精确的关键词匹配可能不如稀疏检索有效,有时会返回一些语义相关但实际信息密度不高的结果。向量数据库的查询通常比关键词检索更耗计算资源。
单独使用其中一种方法都有其局限性。混合检索正是为了克服这些局限性。
混合检索的工作原理
混合检索通常会并行执行至少两种不同类型的检索(最常见的是稀疏检索和稠密检索),然后将它们的结果进行智能融合,最终提供给 LLM 作为上下文。
它的工作流程大致如下:
查询处理: 用户提出一个问题或查询。
并行检索:
- 使用稀疏检索器(如BM25)在知识库中查找包含关键词的文档块。
- 同时,将用户查询通过Embedding 模型转换为向量,然后使用稠密检索器在向量数据库中查找语义相似的文档块。
结果融合(Fusion):
将两种检索方法得到的结果进行合并和排序。常见的融合算法包括:
- 倒数排名融合(Reciprocal Rank Fusion, RRF): 这是一种常用的融合算法,它不依赖于检索分数本身,而是根据每个文档在不同检索结果列表中的排名来计算其最终排名。即使不同检索方法的得分尺度不同,RRF 也能有效地融合结果。
- 加权融合: 为不同检索方法的结果分配权重,然后将它们的得分相加进行排名。
- 瀑布式/级联式: 先用一种方法进行粗召,再用另一种方法进行精排。
去重与上下文整合: 对融合后的文档进行去重,并选取最相关的(通常是Top-K个)文档块,将其内容整合起来,作为 LLM 生成回答的上下文。
LLM 生成: 将用户的原始查询和整合后的上下文信息一同输入给 LLM,LLM 基于这些信息生成最终的回答。
重排模型(Rerank Model)
在 RAG(检索增强生成)系统中,重排模型(Rerank Model)是一个独立的深度学习模型,它的核心任务是对初步检索(Initial Retrieval/Recall)阶段返回的候选文档进行二次评估和排序,以确保最相关、最高质量的少数文档被提供给大型语言模型(LLM)作为生成答案的上下文。
简单来说,如果初步检索是“大海捞针”,那重排模型就是从“捞上来的这一堆”中“精挑细选”出最闪亮的几根针。
重排模型的含义
Rerank 模型 (Reranker Model) 是指在 RAG(检索增强生成)系统中专门用于执行“重排序”任务的机器学习模型。它的核心功能是评估给定查询(Query)和候选文档/段落(Document/Passage)之间的相关性,并输出一个量化的分数,从而对这些候选文档进行新的、更精确的排序。
通常,这个 Rerank 模型是一个预训练的、基于 Transformer 架构的小型深度学习模型,并且往往是交叉编码器 (Cross-Encoder) 结构。
Rerank 模型的工作原理:
- 输入: 它接收一对输入:用户查询文本 + 某个待评估的文档文本。
- 编码与交互: 模型内部会同时处理这两段文本。最关键的是,它会允许查询和文档的词语之间进行相互作用和交叉注意力计算。这意味着模型不仅独立理解查询和文档,更重要的是,它能理解它们两者结合在一起时产生的语义关联。
- 输出: 经过编码和处理后,模型通常会输出一个标量值,代表这两段文本的相关性分数。分数越高,表示查询和文档越相关。
举例: 假设用户查询是:“欧洲二战爆发的原因”。 检索器可能返回了:
- 文档A:“1939年9月1日,德国入侵波兰,标志着二战的全面爆发。”
- 文档B:“第一次世界大战的赔款和凡尔赛条约对德国经济造成巨大打击,民族主义抬头,希特勒上台。”
- 文档C:“关于宇宙大爆炸理论的最新研究。”
Rerank 模型会分别评估 (Query, 文档A)、(Query, 文档B)、(Query, 文档C) 之间的相关性。
- 它可能会给 (Query, 文档A) 较高的分,因为它提到了“二战爆发”,但可能不是最高,因为重点是“爆发”而非“原因”。
- 它会给 (Query, 文档B) 更高的分,因为它提到了“赔款”、“条约”、“民族主义”、“希特勒上台”等与“原因”强相关的背景信息。
- 它会给 (Query, 文档C) 非常低的分,因为完全不相关。
最终,Rerank 模型会根据这些分数对文档进行重新排序,将文档 B 排在最前面,其次是文档 A。
为什么需要 rerank 重排模型?
RAG 系统中的“检索”阶段通常依赖于向量数据库和嵌入模型进行相似性搜索。这被称为 “双塔模型”(Two-Tower Model) 或 “召回模型”(Retriever Model)。
双塔模型的原理:
- 查询(Query)经过一个编码器生成查询向量。
- 知识库中的每个文档(Document)经过另一个(或相同的)编码器生成文档向量。
- 通过计算查询向量和文档向量之间的向量相似度(如余弦相似度)来找到最相似的文档。
双塔模型的优点:
- 高效性: 文档向量可以离线预计算并存储在向量数据库中。查询时只需计算一个查询向量,然后进行快速的近似最近邻搜索,速度非常快。
- 可伸缩性: 适用于大规模知识库的检索。
双塔模型的局限性(这也是 Rerank 模型出现的原因):
- 语义交互不足: 双塔模型是分别编码查询和文档的。它们在向量空间中的相似性是基于独立的语义表示。这意味着它们无法捕捉查询和文档之间细粒度的、上下文敏感的交叉语义交互。例如,它们可能无法很好地区分“A 影响 B”和“B 影响 A”这种细微差别,或者无法理解查询中的某个词在特定文档上下文中的具体含义。
- “相关性”与“召回”的权衡: 双塔模型在设计时,为了提高召回率(即尽可能多地找回潜在相关的文档),有时会牺牲一定的排序精确性。它可能召回大量看似相关但实际上并非最佳回答的文档。
- 长尾问题和复杂查询: 对于非常具体、复杂或涉及推理的查询,简单的向量相似度可能无法找到最精确的答案源。
重排模型之所以在 RAG 系统中不可或缺,主要是为了解决初步检索的固有局限性,并优化 LLM 的输入质量和效率:
弥补初步检索的局限性:
语义相似度 ≠ 精确相关性: 初步检索(通常基于嵌入模型,如双编码器)通过计算查询和文档向量的距离来判断相似性。这种方法能高效地召回大量语义上“可能相关”的文档。但是,“语义相似”不等于“精确相关”。例如,查询“最新款手机的电池续航”,初步检索可能召回关于“手机评测”、“电池技术”等多个方面但并非直接回答续航的文档。
缺乏深度上下文理解: 大多数用于初步检索的嵌入模型是 双编码器(Dual Encoder) 架构,它们独立编码查询和文档,然后计算它们的相似度。这种架构在处理大规模数据时效率很高,但无法实现查询和文档词语之间的深层次 交互理解 。它们无法捕捉到复杂的语义依赖、逻辑关系或意图匹配。
提升信息检索的精准度(Precision):
- 重排模型能够对初步召回的结果进行更细粒度的相关性判断。它能识别出那些在初步检索中排名靠前,但实际上与查询意图相关性较低的“噪音”文档,并将其排名靠后。同时,也能提升那些与查询高度相关但可能在初步检索中得分不高的文档的排名。
- 这大大提高了最终提供给 LLM 的上下文的质量和纯净度,确保了信息的高相关性。
优化 LLM 的上下文窗口和效率:
LLM 上下文窗口限制: 大多数 LLM 都有一个最大输入长度(上下文窗口)的限制。初步检索通常会召回几十到几百个文档片段,将所有这些都输入给 LLM 是不切实际的,要么会超出限制,要么会导致极高的推理成本和延迟。
降低噪音和幻觉: 将大量无关或低质量的信息塞给 LLM,会“稀释”真正有用的信息,增加 LLM 产生“幻觉”(即编造事实)的可能性,因为它可能会从不相关的上下文中错误地提取或推断信息。
节省成本和计算资源: 通过重排模型,我们只需要将少数(例如 Top 3-5 个)最相关的文档片段传递给 LLM。这显著减少了 LLM 处理的 token 数量,从而降低了 API 调用成本和推理时间,提升了整个 RAG 系统的响应速度。
RAG 技术应用
如下是从 0 到 1 快速搭建 RAG 应用。目前 Python 在人工智能领域还是称王称霸的存在,golang 在这方面是可望不可即的,比如 langchain ,langchaingo 更新频率非常低,而且对bug的处理速度也偏慢,社区也有人吐槽为什么 Langchaingo 的为什么当前是 25年的5月份 而最新一个版本是 25年2月份-Why not release a new release? The latest release is still in February #1301
而 python 版本的 langchain 保持着高强度的更新,及时解决 开发者提出的 bug。
我个人遇到的一个问题,对一些 paper 上的 PDF,经常使用 golang 自带的 PDF 解开全是乱码,而Python 版本的就没有丝毫问题。
如下是对应的技术框架
- RAG 技术框架:LangChain
- 索引\检索 流程 - 向量化模型:本地 ollama 运行 nomic-embed-text:latest
Nomic AI是世界上第一家信息制图公司 ,旗下的 Nomic-embed 也是超强的开源嵌入模型。
混合检索:
- 稀疏检索:BM-25 基于词频
- 稠密检索:Dense (Langchain 自带 similarity_search)
重排模型 - 向量化模型:huggingface BAAI/bge-reranker-v2-m3
索引\检索 流程 - 向量库:Faiss
LLM 大模型:通义千问-Turbo (阿里云百炼大模型新手可以有100W免费Token)
进阶:RAG 的进阶 KAG
“KAG” 是一个在 LLM 领域逐渐获得关注的概念,它通常指的是 Knowledge-Augmented Generation(知识增强生成)。
虽然 RAG 已经非常强大,但 KAG 旨在进一步提升 LLM 在特定领域、需要深度推理和结构化知识时的表现。你可以把 KAG 看作是 RAG 的一种演进或补充,尤其是在处理复杂、多跳(multi-hop)的专业领域查询时。

KAG (Knowledge-Augmented Generation) 是什么?
KAG 的核心理念是将结构化的领域知识(通常是知识图谱 - Knowledge Graphs, KGs)更紧密、更深入地集成到 LLM 的生成过程中,而不仅仅是像 RAG 那样检索文本片段。
与 RAG 主要依赖非结构化文档(如文本、网页)的向量相似性检索不同,KAG 更加强调利用结构化数据的强大推理能力和明确的语义关系。
KAG 与 RAG 的主要区别和联系
| 特征 | RAG (Retrieval-Augmented Generation) | KAG (Knowledge-Augmented Generation) |
|---|---|---|
| 知识来源 | 主要基于非结构化文本(文档、网页、文章等) | 主要基于结构化知识(知识图谱、数据库等) |
| 检索方式 | 向量相似性检索(语义匹配)和/或关键词匹配(稀疏检索) | 除了向量检索,更强调基于知识图谱的推理和路径查找 |
| 核心优势 | 快速适应新信息、处理开放域问题、减少幻觉 | 深度推理能力、处理复杂多跳问题、确保事实一致性、提高领域专业度 |
| 应用场景 | 问答系统、内容生成、摘要等,适用于动态、多样化的信息 | 垂直领域专业问答(如医疗、金融、法律)、复杂逻辑推理、数据分析 |
| 实现复杂性 | 相对较低,主要涉及文档切块、嵌入和向量存储 | 较高,需要构建和维护高质量的知识图谱,并设计复杂的推理和图谱交互机制 |
| 对LLM的影响 | 补充上下文信息,让LLM基于提供的文本进行生成 | 引导LLM进行逻辑推理,使其能够“理解”和“利用”知识间的关系进行生成 |
实现一个文档检索
相关的代码我放到了 github 仓库中 - https://github.com/kiosk404/llm-rag-project
技术框架与选型
😐 RAG 技术框架:Langchain
LangChain 是专为开发基于大型语言模型(LLM)应用而设计的全面框架,其核心目标是简化开发者的构建流程,使其能够高效创建 LLM 驱动的应用。
def create_qa_chain(self, vector_store: FAISS, retrieval_mode: str = 'dense', corpus: list = None) -> RetrievalQA:
"""
创建问答链,支持混合检索
参数:
vector_store: FAISS 向量库实例
retrieval_mode: 检索模式(dense/sparse/hybrid)
corpus: 稀疏检索语料
返回:
RetrievalQA: 创建的问答链
"""
if self.qa_chain is None:
try:
llm = self.load_llm()
retriever = self.create_retriever(vector_store, retrieval_mode, corpus)
# 包装 retriever,支持 rerank
if self.use_rerank and self.reranker is not None:
orig_get_relevant_documents = retriever._get_relevant_documents
def rerank_wrapper(query):
docs = orig_get_relevant_documents(query)
return self.reranker.rerank(query, docs)
retriever._get_relevant_documents = rerank_wrapper
self.qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
)
except Exception as e:
raise ServiceError(
f"创建问答链失败:{e}\n"
f"请检查模型配置和向量库状态。"
)
return self.qa_chain⏭️ 索引流程 - 文档解析模块\分块模块:
这里提供 固定大小、重叠等多种分块策略,由 langchain 的 text_splitter 模块提供相关实现。
详细可参考:https://python.langchain.com/docs/concepts/text_splitters/
class FixedSizeChunking(ChunkingStrategy):
"""固定大小分块策略"""
def split_documents(self, documents: List[Document], **kwargs) -> List[Document]:
chunk_size = kwargs.get('chunk_size', 500)
chunk_overlap = kwargs.get('chunk_overlap', 0)
text_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separator="\n"
)
return text_splitter.split_documents(documents)
def get_description(self) -> str:
return "固定大小分块:按照指定的字符数进行简单分割,不考虑语义边界"
...🤔 索引/检索流程 - 向量化模型:nomic-embed-text
这里使用 ollama 为底座:
可先安装 ollama https://ollama.com/download
然后拉取 nomic 模型 ollama pull nomic-embed-text
def load_embedding_model(self) -> OllamaEmbeddings:
"""
加载嵌入模型
返回:
OllamaEmbeddings: 加载的嵌入模型实例
"""
if self.embedding_model is None:
try:
print(f"正在从 Ollama 加载嵌入模型: {EMBEDDING_MODEL_NAME}")
self.embedding_model = OllamaEmbeddings(
model=EMBEDDING_MODEL_NAME,
base_url=OLLAMA_BASE_URL
)
# 测试嵌入模型
test_embedding = self.embedding_model.embed_query("测试")
except Exception as e:
raise ServiceError(
f"加载嵌入模型失败:{e}\n"
f"请确保 Ollama 服务正在运行,"
f"并且模型 {EMBEDDING_MODEL_NAME} 已安装。"
)
return self.embedding_model💬 索引 / 检索流程 - 向量库:Faiss
向量数据库Faiss是Facebook AI研究院开发的一种高效的相似性搜索和聚类的库。它能够快速处理大规模数据,并且支持在高维空间中进行相似性搜索。
FAISS并不能直接存储数据,它只是一个索引和搜索向量的工具,这个工具可以根据emdebbing的后生成的向量,从文本中匹配跟问题相关的内容出来。FAISS的存储数据只是把向量化后的一系列数据存在本地文件,之后需要的时候再从本地文件进行加载进去。
ef create_and_save_vector_store(chunks: List[Document], embeddings: Embeddings) -> FAISS:
"""
从文档块创建 FAISS 向量库并保存到磁盘。
参数:
chunks (List[Document]): 文档块列表。
embeddings (Embeddings): 使用的嵌入模型实例。
返回:
FAISS: 创建的 FAISS 向量库实例。
"""
print("正在创建并保存向量库...")
vector_store = FAISS.from_documents(chunks, embeddings)
vector_store.save_local(FAISS_INDEX_PATH)
print(f"向量库已保存到 {FAISS_INDEX_PATH}")
return vector_store
def load_vector_store(embeddings: Embeddings) -> Optional[FAISS]:
"""
从磁盘加载 FAISS 向量库。
参数:
embeddings (Embeddings): 使用的嵌入模型实例。
返回:
Optional[FAISS]: 加载的 FAISS 向量库实例,如果未找到则为 None。
"""
if os.path.exists(FAISS_INDEX_PATH):
print(f"正在从 {FAISS_INDEX_PATH} 加载向量库")
return FAISS.load_local(
FAISS_INDEX_PATH,
embeddings,
allow_dangerous_deserialization=True
)
else:
print("未找到向量库。")
return None🤗 生成流程 - 大语言模型:Qwen
参考 https://zhuanlan.zhihu.com/p/18806936905 ,新人用户有免费额度,我个人用于测试,充值了2块钱,足够个人联系测试用了。
验证检索
本人测试的 PDF 是一篇 Alibaba 的一篇关于 低延迟视频传输 FCDN 网络的技术架构的 parper
运行前准备工作
git clone https://github.com/kiosk404/llm-rag-project.git
bash install_dependencies.sh
source .venv/bin/activate
# 将要解析的 pdf 移到 docs 目录
mv ~/livenet docs- 对文档进行 解析和分块
(.venv) ➜ llm-rag-project git:(master) ✗ python main.py ingest
? 请选择文本分割策略: 语义分块(spaCy) - 语义分块:使用spaCy进行语义分析,按句子和语义边界分割
? 请输入文本块大小: 256
? 请输入文本块重叠大小: 32
正在加载文档...
正在使用 语义分块(spaCy) 分割文档...
已创建 366 个文本块。
正在加载嵌入模型...
正在从 Ollama 加载嵌入模型: nomic-embed-text:latest
正在创建并保存向量库...
正在创建并保存向量库...
向量库已保存到 /home/weijiaxiang/PycharmProjects/llm-rag-project/vector_store/faiss_index
数据摄入完成!- 问题提问
(.venv) ➜ llm-rag-project git:(master) ✗ python main.py query
正在加载嵌入模型...
正在从 Ollama 加载嵌入模型: nomic-embed-text:latest
正在加载向量库...
正在从 /home/weijiaxiang/PycharmProjects/llm-rag-project/vector_store/faiss_index 加载向量库
? 请选择检索模式: 混合检索(Hybrid,融合两者)
? 是否启用重排序(Rerank)以提升答案相关性? Yes
已选择检索模式: hybrid
重排序功能: 已启用
正在加载大语言模型...
正在加载 通义千问 模型...
正在创建问答链...
正在加载 通义千问 模型...
✅ 已准备好回答您的问题!
💡 提示:输入 'exit' 退出,输入 'help' 查看帮助
? 请输入您的问题: LiveNet 如何实现的全网节点高效、低延迟 请求的?
🤔 正在思考...
💡 答案:
LiveNet 实现全网节点高效、低延迟请求主要依赖以下几个关键设计:
1. **扁平化覆盖网络结构**:
LiveNet 采用了一种扁平化的覆盖网络模型,而不是传统的分层结构(如 Hier)。这种扁平化的设计减少了数据传输的中间层级,从而降低了端到端的延迟。
2. **高效的路径决策机制 (Streaming Brain)**:
- Streaming Brain 的响应时间非常短,中位数仅为 30 毫秒,25 百分位约为 5 毫秒。
- 这使得路径请求能够快速得到响应,从而加快了整体请求处理速度。
3. **路径缓存与预取机制**:
- 每个节点都缓存了路径信息(Stream FIB),当路径请求命中本地缓存时,称为“本地命中”。
- 在高负载时段(如晚上 8 点至 11 点),本地命中率可达约 70%,显著减少了对中心化路径决策模块的依赖,提高了效率。
- 同时,系统通过基于预测的路径预取机制,提前加载可能被请求的路径,进一步减少延迟。
4. **GoP 缓存优化**:
- CDN 节点中的 GoP 缓存可以提升快速启动比例(fast startup ratio),即使在流媒体延迟超过 1 秒的情况下,仍能保持较高的快速启动比例(如 95%)。
这些技术共同作用,使得 LiveNet 在大规模直播场景下实现了高效的全网节点协作和低延迟的视频传输。
📚 来源文档:
1. 来源: /home/weijiaxiang/PycharmProjects/llm-rag-project/docs/livenet.pdf, 页码: 8
2. 来源: /home/weijiaxiang/PycharmProjects/llm-rag-project/docs/livenet.pdf, 页码: 2
3. 来源: /home/weijiaxiang/PycharmProjects/llm-rag-project/docs/livenet.pdf, 页码: 0
4. 来源: /home/weijiaxiang/PycharmProjects/llm-rag-project/docs/livenet.pdf, 页码: 6
5. 来源: /home/weijiaxiang/PycharmProjects/llm-rag-project/docs/livenet.pdf, 页码: 7
--------------------------------------------------