ollama 本地AI大模型
自 OpenAI 公司于 2022 年 11 月 30 日发布 ChatGPT 以来,经过 23 年一整年的发展之后,大语言模型的概念已逐渐普及,各种基于大语言模型的周边产品,以及集成层出不穷,可以说已经玩出花来了。
在这个过程中,也有不少本地化的模型应用方案冒了出来,针对一些企业知识库问答的场景中,模型本地化是第一优先考虑的问题,因此如何在本地把模型调教的更加智能,就是一个非常重要的技能了。
什么是 ollama?
Ollama 是一个用于构建大型语言模型应用的工具,它提供了一个简洁易用的命令行界面和服务器,让你能够轻松下载、运行和管理各种开源 LLM。
- 项目地址:ollama(opens new window)
- 官网地址: https://ollama.com/(opens new window)
- 模型仓库: https://ollama.com/library(opens new window)
- 此文撰写时项目最新版本:v0.3.6(opens new window)
- 官方 logo 是一只可爱的羊驼

Ollama 是一个基于 Go 语言开发的简单易用的本地大语言模型运行框架。可以将其类比为 docker(同基于 cobra (opens new window)包实现命令行交互中的 list,pull,push,run 等命令),事实上它也的确制定了类 docker 的一种模型应用标准。如 ollama pull xxx、ollama run xxx 等等。
在管理模型的同时,它还基于 Go 语言中的 Web 框架 gin (opens new window)提供了一些 Api 接口,让你能够像跟 OpenAI 提供的接口那样进行交互。
官方还为此专门发布了一篇官方博客: https://ollama.com/blog/openai-compatibility (opens new window),并配了如下一个可爱的图。

同时:官方还提供了类似 GitHub,DockerHub 一般的,可类比理解为 ModelHub,用于存放大语言模型的仓库(有 llama 2,mistral,qwen 等模型,同时你也可以自定义模型上传到仓库里来给别人使用)。
ollama 探索
Linux 安装 ollama
curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
>>> Downloading Linux amd64 CLI
######################################################################## 100.0%#=#=-# # ######################################################################## 100.0%
>>> Making ollama accessible in the PATH in /usr/local/bin
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.虽然 AMD 已将
amdgpu驱动程序上游贡献给官方 Linux 内核源代码,但该版本较旧,可能不支持所有 ROCm 功能。建议从 AMD 官网 安装最新驱动程序,以获得对您 Radeon GPU 的最佳支持。不幸的是,我的GPU是 intel 的,所以只能是 CPU-only mode,所以有以下提示:
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.
我这里个人使用的是 Linux Ubuntu (8C 16G),直接下载安装包,安装即可,安装之后,运行软件。
运行之后,项目默认监听 11434 端口,在终端执行如下命令可验证是否正常运行:
✗ curl 127.0.0.1:11434
Ollama is running%此时只是相当于把一个架子,一个舞台搭好了, 就相当安装好了 Docker,要想要真正体验大模型,还需要拉下来一个模型。
模型管理
ollama 安装之后,其同时还是一个命令,与模型交互就是通过命令来进行的。
ollama list:显示模型列表。ollama show:显示模型的信息ollama pull:拉取模型ollama push:推送模型ollama cp:拷贝一个模型ollama rm:删除一个模型ollama run:运行一个模型
官方提供了一个模型仓库,https://ollama.com/library (opens new window),在这里你可以找到你想要运行的模型。
官方建议:应该至少有 8 GB 可用 RAM 来运行 7 B 型号,16 GB 来运行 13 B 型号,32 GB 来运行 33 B 型号。
鉴于我的是 8C 16G ,所以我运行一个4 B的型号吧。
以下是一些可下载的示例模型:
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 3 | 8B | 4.7GB | ollama run llama3 |
| Llama 3 | 70B | 40GB | ollama run llama3:70b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | ollama run phi |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
| Solar | 10.7B | 6.1GB | ollama run solar |
- 拉取模型
ollama pull llama3此命令也可以用于更新本地模型。只会拉取差异部分。
ps: 模型的拉取速度能达到 11MB/s ,可见官方的支持力度是非常足的。带宽是下了血本了。
- 删除模型
ollama rm llama3- 复制模型
ollama cp llama3 my-model- 多模态模型
>>> What's in this image? /Users/jmorgan/Desktop/smile.png
The image features a yellow smiley face, which is likely the central focus of the picture.- 作为参数传递提示
$ ollama run llama3 "Summarize this file: $(cat README.md)"
Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications.简单交互
执行 ollama run llama3 可以直接运行 llama 大模型。
终端交互

REST API
Ollama 有一个用于运行和管理模型的 REST API。
生成响应
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt":"Why is the sky blue?"
}'与模型聊天
curl http://localhost:11434/api/chat -d '{
"model": "llama3",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'查看 API 文档了解所有端点。
Web 和桌面端
这里基于颜值,我选择 webui-lite, 还有很多的 web 桌面端的开源选择,具体参考:链接
注意需要 node >= 16。
git clone https://github.com/ollama-webui/ollama-webui-lite.git
cd ollama-webui-lite
yarn
yarn dev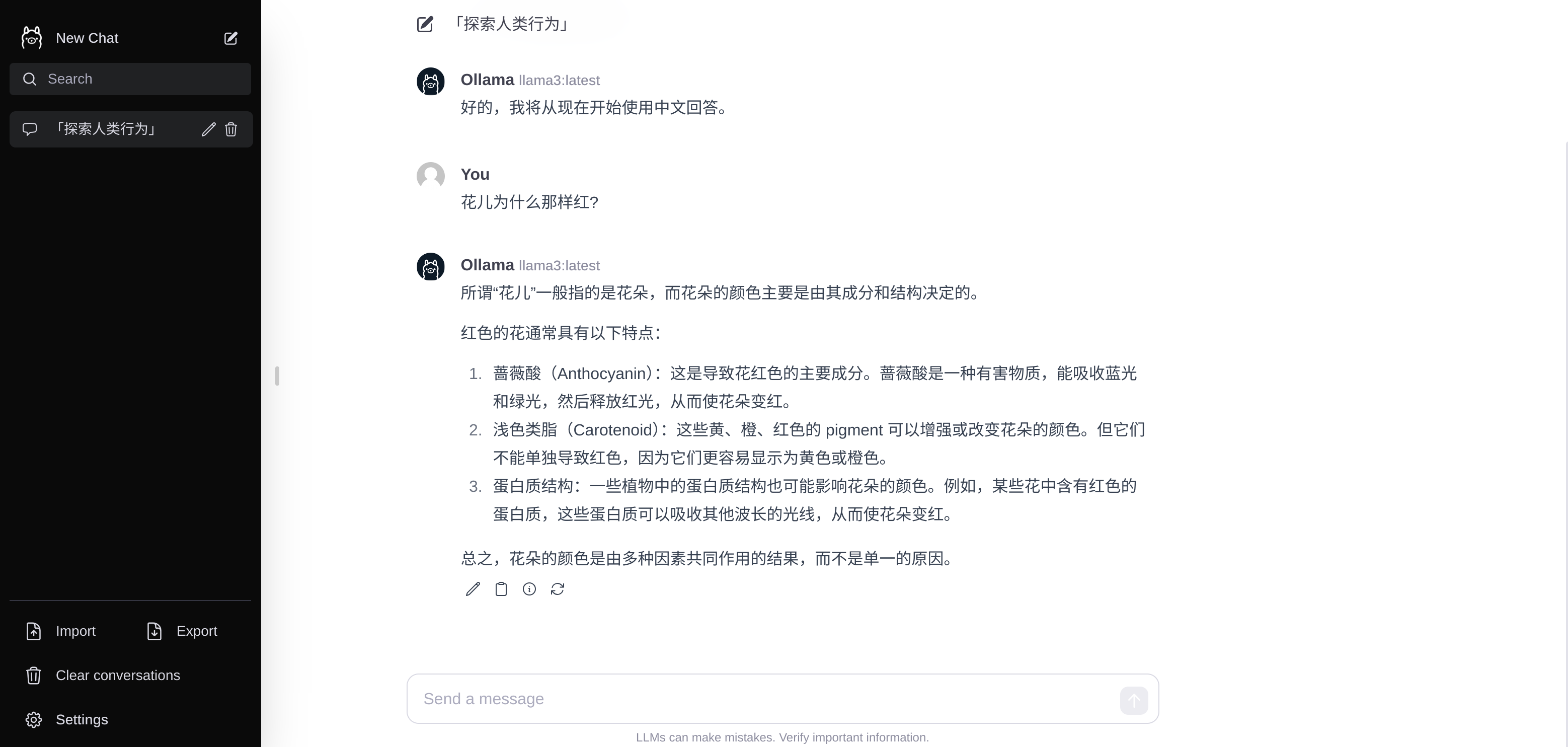
RAG 进阶
了解了 ollama ,搭建了一个基础 llama ,那么怎么样才能让自己的本地大模型区分于 chatGPT 或者 doubao 之类的模型成为真正的钢铁侠中的 Jarvis呢?
什么是 RAG
rag,即 Retrieval Augmented Generation ,意为检索增强生成。这是一种应用于知识内容检索领域的概念,有别于传统的基于关系型数据库构建的问答体系,rag 主要是基于向量数据库结合当下火热的大语言模型(LLM)来实现的智能问答的一种技术体系。
是的,围绕 rag 的核心是三个部分,原始文本内容,向量数据库,和大语言模型,其他的技术实现,以及细节调优基本都是在这几者之间的延伸。
以客服这个实际场景来举例:
- 每个公司最早一批的客服,肯定也都是摸着石头过河,很多问题都是新产生的,并没有可参见的案例或话术。
- 随着时间推移,客服工作人员的经验积累,话术慢慢沉淀,形成本公司业务专有的客服知识库,这个知识库可能会借助一些已有的 wiki 工具存放,那么后来的客服人员,遇到自己不会的问题,就可以通过查询 wiki 就能获取到他想要的答案。(局限:这里的问题是,这种查询一定是依赖于关键字匹配的,尽管能全文匹配,但一些时候,可能并不理想)
- 再往后,一些公司可能会基于成熟的客服话术,开发自己的智能客服机器人,而这种方案,虽然比上边的人工查询要进了一步,但局限是雷同的(还是依赖于技术型交互语言,而非自然语言交互)。
- 当大语言模型出现之后,人们最先想到的就是如何能将自己的知识库投喂给大语言模型,从而能够通过自然语言获取到想要的答案,自此念头开始,文本向量化,langchain 框架,本地大语言模型等技术应场景而生,渐渐进化为可完全基于本地构建的智能问答体系,从而解放客服的生产力。
RAG模型结合了语言模型和信息检索技术。具体来说,当模型需要生成文本或者回答问题时,它会先从一个庞大的文档集合中检索出相关的信息,然后利用这些检索到的信息来指导文本的生成,从而提高预测的质量和准确性。其中,“检索”、“利用”、“生成”是RAG的关键部分。
RAG 的架构
通过一些架构图来理解是最简单直观的。
来自项目:Langchain-Chatchat
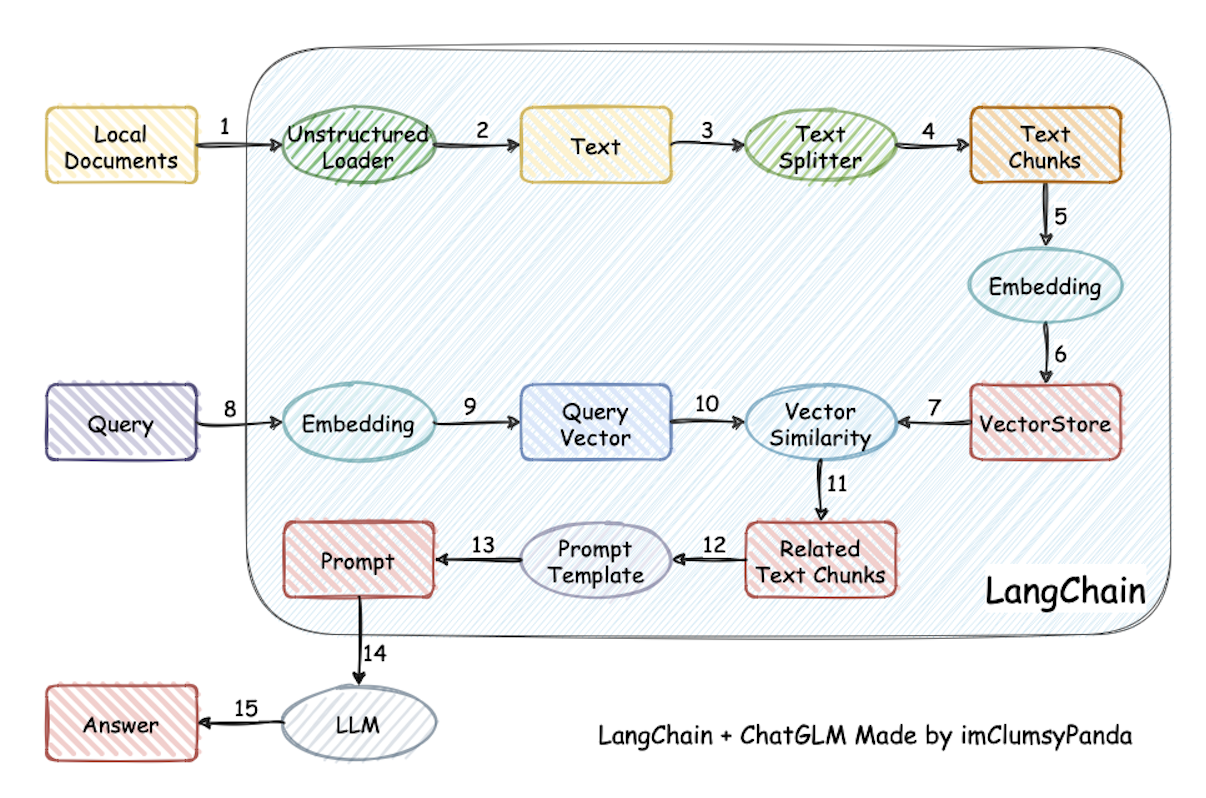
RAG 处理流程
实现原理如上图图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
从文档处理角度来看,实现流程如下:
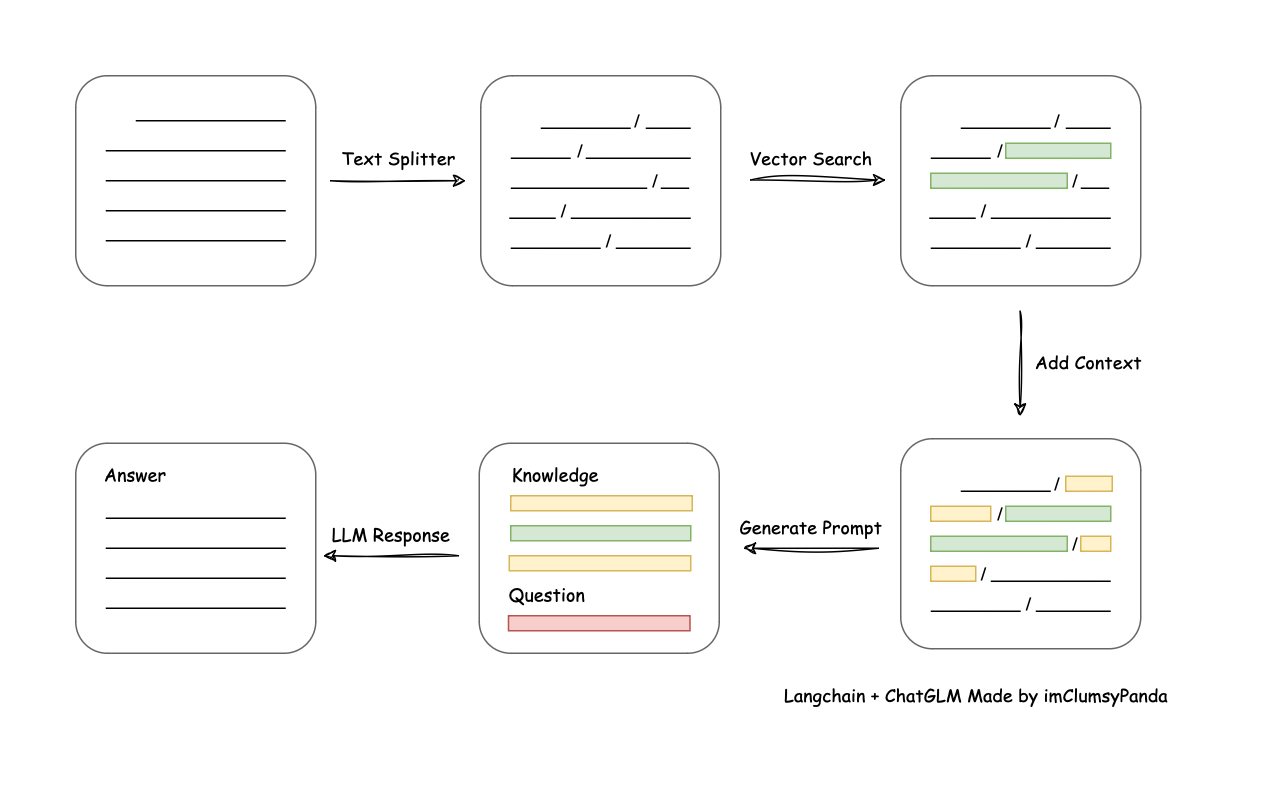
文档处理流程
个人简约理解如下:
- 先将知识库内容切分,类似NLP中的文本拆分,如jieba等。
- 再把切分后的内容向量化存入向量数据库。
- 用户提问之后,先将问题在向量库中进行相似性检索,找出匹配度高的答案。
- 然后把查询出来的结果,包装好 Prompt。
- 最后调用大语言模型,让大语言模型基于上一步的结果进行分析并形成最终的答案,返回给用户。
开源社区中很火的 langchain 则是针对如上步骤提供了整套封装的一个框架,langchain 就是能够让你完成从文本处理,到转换向量与向量数据库的交互,再到承接用户提问的交互,再到与大语言模型的交互,所以如果你要构建一套 rag,那么基于 langchain 就可以做到,事实上,当下 GitHub 上很火的 rag 项目,大多也都是基于 langchain 来做的。
RAG 领域开源项目
伴随着大语言模型的火爆,除去一开始火爆的那批套壳应用之外,后来者居上的,并且保持了持久热度的,恐怕就是 rag 领域的开源项目了,这里罗列一下我个人知道的 rag 领域相关的开源项目。
- dify (opens new window):一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流程、RAG 管道、代理功能、模型管理、可观察性功能等,让您可以快速从原型到生产。
- FastGPT (opens new window):一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
- anything-llm (opens new window):一个全栈应用程序,使您能够将任何文档、资源或内容片段转换为任何法学硕士可以在聊天期间用作参考的上下文。该应用程序允许您选择要使用的法学硕士或矢量数据库,并支持多用户管理和权限。
- ragflow (opens new window):一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
- MaxKB (opens new window):基于 LLM 大语言模型的知识库问答系统。开箱即用,支持快速嵌入到第三方业务系统。
- QAnything (opens new window):是致力于支持任意格式文件或数据库的本地知识库问答系统,可断网安装使用。您的任何格式的本地文件都可以往里扔,即可获得准确、快速、靠谱的问答体验。目前已支持格式: PDF(pdf),Word(docx),PPT(pptx),XLS(xlsx),Markdown(md),电子邮件(eml),TXT(txt),图片(jpg,jpeg,png),CSV(csv),网页链接(html)
基于langchaingo实现知识库对接本地模型
前面2节把理论,以及流程都介绍完了,接下来世纪操作一下。因此,这篇就是通过一个简单的示例,结合 langchaingo 来实现一下自己开发 rag 应用的整个流程。
项目地址:
前文说到,rag 的核心流程大概有如下几步:
- 先将知识库内容切分
- 再把切分后的内容向量化存入向量数据库
- 用户提问之后,先将问题在向量库中进行相似性检索,找出匹配度高的答案。
- 然后把查询出来的结果,包装好 Prompt。
- 最后调用大语言模型,让大语言模型基于上一步的结果进行分析并形成最终的答案,返回给用户。
接下来我就通过代码,来按照上边的流程,做下实践。
代码仓库地址:https://github.com/kiosk404/langchaingo-ollama-rag
前置准备
安装一个向量数据库。这里向量数据库使用的是 qdrant,使用 docker 快速安装。
docker pull qdrant/qdrant
docker run -itd --name qdrant -p 6333:6333 qdrant/qdrant使用如下命令创建一个 集合:
curl -X PUT http://localhost:6333/collections/langchaingo-ollama-rag \
-H 'Content-Type: application/json' \
--data-raw '{
"vectors": {
"size": 768,
"distance": "Dot"
}
}'使用如下命令可删除该集合:
curl --location --request DELETE 'http://localhost:6333/collections/langchaingo-ollama-rag'切分文档
文档我准备的内容是一片 acm 上的关于 低延迟视频传输网络 LiveNet 的设计架构。
文章链接:LiveNet: A Low-Latency Video Transport Network For Large Scale Live Streaming
PS: 这里我一定要吐槽一下,golang 对 PDF 的识别三方库真的是很糟糕,正如 langchaingo 中的这个 issue 所吐槽的,所以我不能直接用 他的接口 NewPDF,我得 PDF 转 TXT。
主要代码如下:
// TextToChunks 函数将文本文件转换为文档块
func TextToChunks(dirFile string, chunkSize, chunkOverlap int) ([]schema.Document, error) {
file, err := os.Open(dirFile)
if err != nil {
return nil, err
}
// 创建一个新的文本文档加载器
docLoaded := documentloaders.NewText(file)
// 创建一个新的递归字符文本分割器
split := textsplitter.NewRecursiveCharacter()
// 设置块大小
split.ChunkSize = chunkSize
// 设置块重叠大小
split.ChunkOverlap = chunkOverlap
// 加载并分割文档
docs, err := docLoaded.LoadAndSplit(context.Background(), split)
if err != nil {
return nil, err
}
return docs, nil
}这里将 chunkSize 和 chunkOverlap 两个变量参数化,也是为了能够更加清晰地看到参数所代表的含义,以及对于整个流程的影响。
执行结果如下:
➜ langchaingo-ollama-rag go run *.go filetochunks -f livenet.txt
INFO [2024-08-25 22:06:04]main.init.func1:80 转换文件为块成功,块数量: 458
🗂 块儿内容==> LiveNet: A Low-Latency Video Transport Network for
Large-Scale Live Streaming
Jinyang Li† § ‡ , Zhenyu Li† ‡, Ri Lu§, Kai Xiao§, Songlin Li§, Jufeng Chen§, Jingyu Yang§,
🗂 块儿内容==> Chunli Zong§, Aiyun Chen§, Qinghua Wu† ‡, Chen Sun§, Gareth Tyson∗, Hongqiang Harry Liu§
†Institute of Computing Technology, Chinese Academy of Sciences §Alibaba Group
🗂 块儿内容==> ‡University of Chinese Academy of Sciences ∗Hong Kong University of Science and Technology (GZ)
ABSTRACT
Low-latency live streaming has imposed stringent latency require-
🗂 块儿内容==> ments on video transport networks. In this paper, we report on the
design and operation of the Alibaba low-latency video transport
network, LiveNet. LiveNet builds on a flat CDN overlay with a
🗂 块儿内容==> centralized controller for global optimization. As part of this, we
present our design of the global routing computation and path as-
signment, as well as our fast data transmission architecture with
🗂 块儿内容==> fine-grained control of video frames. The performance results ob-通过上边切分之后,可以看出,单个 chunkSize 将决定单个块儿的内容大小,chunkOverlap 将决定有多少向前重复的内容。同理,当我调试时把块儿调大,那么最终块儿的数量就会减少:
块文本向量化
这一步本质上是将切好的数据存入到向量数据库中。并支持查询
// storeDocs 将文档存储到向量数据库
func storeDocs(docs []schema.Document, store *qdrant.Store) error {
// 如果文档数组长度大于0
if len(docs) > 0 {
// 添加文档到存储
_, err := store.AddDocuments(context.Background(), docs)
if err != nil {
return err
}
}
return nil
}
// useRetriaver 函数使用检索器
func useRetriaver(store *qdrant.Store, prompt string, topk int) ([]schema.Document, error) {
// 设置选项向量
optionsVector := []vectorstores.Option{
vectorstores.WithScoreThreshold(0.80), // 设置分数阈值
}
// 创建检索器
retriever := vectorstores.ToRetriever(store, topk, optionsVector...)
// 搜索
docRetrieved, err := retriever.GetRelevantDocuments(context.Background(), prompt)
if err != nil {
return nil, fmt.Errorf("检索文档失败: %v", err)
}
// 返回检索到的文档
return docRetrieved, nil
}使用如下命令,将切分好的块扔进向量数据库。
$ go run *.go embedding
INFO [2024-08-25 22:57:28]main.init.func3:101 转换块为向量成功
$ go run *.go retriever -t 3
请输入你的问题: CDN
🗂 根据输入的内容检索出的块内容==> mapped to CDN servers via DNS redirection. The CDN node that a broadcaster connects to is called a producer node, and the CDN node that a viewer connects to is called a consumer node. A broad-
🗂 根据输入的内容检索出的块内容==> Dec. 10 Dec. 11-12 Dec. 13 CDN path delay (ms) 188 192 180 CDN path length 2 2 2 Streaming delay (ms) 954 988 944 0-stall ratio (%) 97 97 97 Fast startup ratio (%) 94 94 95
🗂 根据输入的内容检索出的块内容==> Network control algorithms; KEYWORDS CDN; Low latency transmission; Live streaming ACM Reference Format: Jinyang Li† § ‡ , Zhenyu Li† ‡, Ri Lu§, Kai Xiao§, Songlin Li§, Jufeng Chen§,如果出现以下错误,执行 ollama pull nomic-embed-text:latest

将检索到的内容,交给大语言模型处理
// GetAnswer 获取答案
func GetAnswer(ctx context.Context, llm llms.Model, docRetrieved []schema.Document, prompt string) (string, error) {
// 创建一个新的聊天消息历史记录
history := memory.NewChatMessageHistory()
// 将检索到的文档添加到历史记录中
for _, doc := range docRetrieved {
history.AddAIMessage(ctx, doc.PageContent)
}
// 使用历史记录创建一个新的对话缓冲区
conversation := memory.NewConversationBuffer(memory.WithChatHistory(history))
executor := agents.NewExecutor(
agents.NewConversationalAgent(llm, nil),
nil,
agents.WithMemory(conversation),
)
// 设置链调用选项
options := []chains.ChainCallOption{
chains.WithTemperature(0.8),
}
// 运行链
res, err := chains.Run(ctx, executor, prompt, options...)
if err != nil {
return "", err
}
return res, nil
}为了将回答转成中文,这里拉下来一个翻译的 AI,让AI把答案翻译一下再回答。所以再需要拉一个翻译的 大模型。
ollama run llama2-chinese对应翻译代码如下:
// Translate 将文本翻译为中文
func Translate(llm llms.Model, text string) (string, error) {
completion, err := llms.GenerateFromSinglePrompt(
context.TODO(),
llm,
"将如下这句话翻译为中文,只需要回复翻译后的内容,而不需要回复其他任何内容。需要翻译的英文内容是: \n"+text,
llms.WithTemperature(0.8))
if err != nil {
return "", err
}
return completion, nil
}…… 见证奇迹的时刻诞生,但是我这块看起来在胡说八道,回答的完全不贴边,我还需要再好好查一下原因….
go run *.go getanswer
请输入你的问题: 导入的文章主要讲了什么?
🗂 原始回答==> The article appears to be discussing the main topic of what the imported article is about.
🗂 翻译后的回答==> 这句话翻译为中文:关于引进报道主题的文章。未完待续…
参考文章: