Kubernetes 调度对象
在容器的世界中,Namespace 做隔离,Cgroups 做限制,rootfs 做文件系统,而如果仅仅是这样的化,容器是没有价值的,因为这样很难实现线上生产环境迁移到容器集群中,线上环境复杂多变,多个服务需要通过本地socket通信或者通过文件交互内容,所以在 k8s 中,pod才是最小的调度单元。
Pod是Kubernetes创建或部署的最小/最简单的基本单位,一个Pod代表集群上正在运行的一组进程。Pod 在 k8s 中扮演着重要的角色:容器的设计模式。
Docker是Kubernetes Pod中最常见的runtime ,Pods也支持其他容器runtimes。
Pod
实现原理
首先要了解的一个事实是 Pod 只是一个逻辑概念,简单的理解是一组超亲密关系的容器
这些容器共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。
在Docker中就有诸如 $ docker run --net=B --volumes-from=B -name =A ... 这样的命令可以让多个容器共享一个Namespace。
没错既然需要共享,那么就需要有容器的启动顺序,先启动一个基础容器,再将后启动的容器共享该基础容器的Namespace。
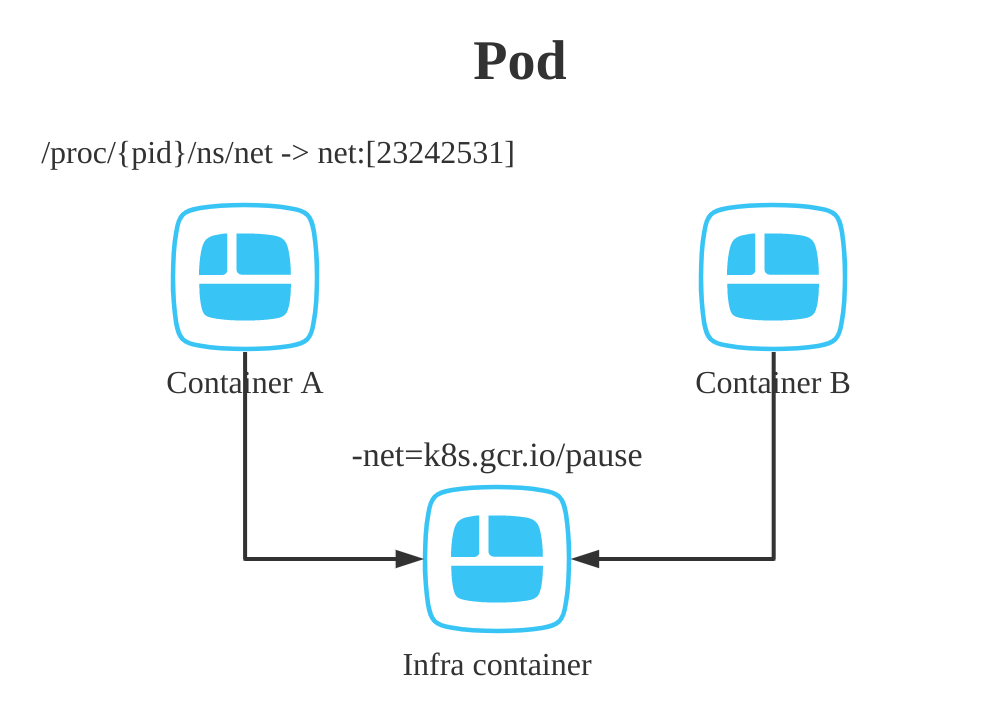
pod)正如上图所示,在其他容器启动之前会先启动一个infra容器,infra容器一定只占用很少的资源,这个容器叫做‘k8s.gcr.io/pause’。这个镜像使用汇编编写,永远处于“暂停”状态,而infra容器提供基础的Namespace环境供该Pod里的其他容器共享。
所以,对于同一个Pod的里的所有容器来讲,他们的进出流量可以认为是通过 infra 容器完成的。之后如果要给k8s开发一个网络插件,应该考虑配置该Pod的Network Namesapce,Infra容器的rootfs里几乎什么东西都没有
Pod 只是 k8s 里面的一个概念,提供的是一个编排思想,而不是具体的技术方案,比如 Mirantis 公司的 virtlet , 可以实现一个带有 systemd 进程的容器,来模拟传统的操作系统。
Pod 配置文件
Pod的创建时基于k8s 的配置文件 – yaml 文件创建的,这样的好处是可以记录每一个Pod的基础信息,凡是调度、网络、存储、安全相关的属性,基本上都是Pod级别的
下面是Pod中的几个重要字段的含义和用法。具体更多的用法可以参考 $GOPATH/src/k8s.io/kubernetes/vendor/k8s.io/api/core/v1/types.go,
apiVersion: v1 # 版本号
kind: Pod # Pod
metadata: # 元数据
name: nginx # Pod名称
namespace: string # Pod所属的命名空间
labels: # 自定义标签
- name: string # 自定义标签名字
annotations: # 自定义注释列表
- name: string
spec: # Pod中容器的详细定义
hostNetwork: true # 共享宿主机网络
hostIPC: true # 共享宿主机IPC
hostPID: true # 共享宿主机PID
shareProcessNamespace: true # Pod间共享PID
nodeSelector: # 设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
disktype: ssd
hostAliases: # 设置 /etc/hosts
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
restartPolicy: [Always | Never | OnFailure] # Pod的重启策略
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
stdin: true
tty: true- spec
nodeSeletor 是一个供用户将 Pod 与 Node 进行绑定的字段 这样的配置意味着该Pod只能运行在携带了“disktype:ssd”标签(Label)的节点上;否则会调度失败。
hostAliases 定义了Pod中的 hosts 文件(比如 /etc/hosts)里的内容 在k8s中如果想要设置hosts文件的内容一定要通过这种方式,否则,Pod被删除重建后,kubelet会自动覆盖掉修改过的内容。
restartPolicy ,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod。
Pod在恢复过程中,永远是发生在当前的Node节点上,而不会去别的节点。如果想要Pod出现在其他可用节点,就需要使用 Deployment 这样的调度器来管理Pod,
- Namespace共享
凡是和Namespace相关的内容那么也一定是Pod级别的,Pod的设计就是要让Pod里的容器共享Namesapce,shareProcessNamespace: true 这条指令就可以实现Pod内的容器共享PID Namespace。
创建Pod之后可以通过
kubectl attach -it nginx -c shell后就可以通过ps 命令查看该Pod中的所有进程。
同样添加 hostNetwork、hostIPC、hostPID 即可共享宿主机资源。
- 容器 && 镜像
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers: # Pod中容器列表
- name: demo # 容器名
image: nginx:1.19.2
command: [string] # 容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] # 容器的启动命令参数列表
workingDir: string # 容器的工作目录
imagePullPolicy: [Always | Never | IfNotPresent] # 容器拉取策略
nodeSelector: obeject # 设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
lifecycle: # 容器生命周期
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存请求,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:falseImagePullPolicy 定义了镜像拉取的策略,是一个Container级别的属性,默认值是Always,即每次创建Pod都重新拉取一次镜像,如果被定义为Never或者 ifNotPresent 时,则意味着Pod永远不会主动拉取这个镜像,或者只有宿主机不存在这个镜像时才会拉取。
Lifecycle 定义了容器生命周期的一些钩子,可以执行容器启动前启动后的一些命令,
- Projected Volume
在 k8s 中有一种特殊的Volume,叫做Projected Volume,存在的意义不是为了存放容器内的数据,也不是用来做数据交换,而是提供预先准备好的数据,所以从容器的角度来看就仿佛是被 k8s “投射”(Project)进入容器的,这正是Projected Volume 的含义。
到目前为止,k8s共支持4种 Projected Volume.
- Secret (例如加载数据库密码等)
- ConfigMap (例如加载配置文件等)
- Downward API (暴露Pod的meta信息给容器)
- ServiceAccountToken (保存授权信息)
以Secret为例,其存在的意义其实就是将一些重要的数据投射进容器,比如数据库密码。
apiVersion: v1
kind: Pod
metadata:
name: test-projected-volume
spec:
containers:
- name: test-secret-volume
image: busybox
args:
- sleep
- "86400"
volumeMounts:
- name: mysql-cred
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: mysql-cred
projected:
sources:
- secret:
name: user
- secret:
name: pass数据库的用户名和密码,正是以Secret对象交付给 k8s 保存的
$ cat ./username.txt
admin
$ cat ./password.txt
c1oudc0w!
$ kubectl create secret generic user --from-file=./username.txt
$ kubectl create secret generic pass --from-file=./password.txt
$ kubectl get secrets
NAME TYPE DATA AGE
user Opaque 1 51s
pass Opaque 1 51s也可以通过yaml文件的格式创建Secret对象
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
user: YWRtaW4=
pass: MWYyZDFlMmU2N2RmDeployment
Pod 看似复杂的API对象,实际上是容器的进一步抽象和封装。而控制器(Deployment)则是控制Pod的抽象。有了控制器,我们可以定义需要2个pod,当pod个数不够时,自动创建pod直到pod个数满足配置文件 replicas 里 定义的个数。
在 k8s 架构中,有一个叫做 kube-controller-manager 的组件,这个组件负责了k8s集群中的集群属性。使用Deployment控制的pod在生产环境才有意义。
功能
- 定义Deployment来创建Pod和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续Deployment
Deployment 本质也是从Etcd中获取到所有携带了“app:nginx” 标签的Pod,统计其数量,并根据 ReplicaSet 字段进行调整。
配置文件
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: string # Deployment名称
spec:
replicas: 3 # 目标副本数量
revisonHistoryLimit: 0 # 控制历史版本个数,0的话就没办法再进行回滚操作
strategy:
rollingUpdate: # 滚动更新
maxSurge: 1 # 滚动升级时最大同时升级1个pod
maxUnavailable: 1 # 滚动升级时最大允许不可用的pod个数
template:
metadata:
labels:
app: string # 模板名称
sepc: # 定义容器模板,该模板可以包含多个容器
containers:
- name: string
image: string
ports:
- name: http
containerPort: 8080 # 对service暴露端口template Deployment里的template 字段和一个标准的Pod对象的API定义丝毫不差,而所有被这个Deployment管理的Pod实例就是根据这个template创建出来的。
ReplicaSet 对象
Deployment 看似简单,但实际上,他是实现 Kubernetes 项目一个非常重要的功能:Pod的"水平扩展/收缩"。这个功能是平台级别项目必须具备的编排能力。
而这种能力就是 ReplicaSet。
滚动更新不仅仅是 Deployment 中的一个字段,而是可以单独作为一个 k8s 中的重要的 API 对象。一个 ReplicaSet 对象,其实就是由副本数目的定义和一个Pod模板的组成。其实ReplicaSet是Deployment的一个子集。
滚动更新的过程可以通过 kubectl rollout status xxx(deployment)指令查看。或者 kubectl describe deployment xxx(deployment) 查看
,当修改了Pod 模板之后,Deployment Controller 会使用这个修改过的Pod模板,创建一个新的 ReplicaSet (hash=173242546624),这个新的 ReplicaSet 的初始化Pod的副本数是 0 。然后会扩展出一个新的Pod集群。
- 想要查看replicaSet 对象
kubectl get rs - 想要查看滚动升级历史
kubectl rollout history xxx(deployment) - 想要回滚升级至历史版本2
kubectl rollout undo xxx(deployment) --revision=2 - 暂停更新和恢复
kubectl rolllout pause xxxx和kubectl roolout resume xxxx - 扩缩容
kubectl scale deployment nginx-deployment --replicase=4
ReplicaSet 的结构非常简单, 如下所示:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-set
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9Deployment 实际上是一个两层控制器。首先,通过 ReplicaSet的个数来描述应用的版本,然后通过 ReplicaSet 的属性(如relicaset的值)来保证 Pod 的副本数量。
Deployment 控制 ReplicaSet(版本),ReplicaSet 控制 Pod(副本数)。
StatefulSet
正如其名,他是有状态的一种集合,普通的 Deployment 认为一个应用的所有Pod是完全一样的,所以他们之间没有顺序也无所谓运行在哪台宿主机上。但是实际场景中,并不是所有的应用都可以满足这样的要求。
尤其是分布式应用,它的多个实例之间往往有依赖关系,比如:主从关系、主备关系。
StatefulSet 的设计就是为了解决这种场景,
- 拓扑状态。这种情况意味着多个实例之间不是完全对等的关系,比如A是主,B是从,A必须要先于B启动。
- 存储状态。这种情况意味着,应用的多分实例分别绑定了不同的存储数据,Pod A 第一次读到的数据,和隔了1小时之后再次读到的数据应该是同一份,哪怕在此期间 Pod A 被重新创建过
所以,StatefulSet 的核心功能,就是通过某种方式记录这些状态,然后在Pod被重新创建时,能够为新的Pod恢复这些状态
如这样的一个 yaml 配置文件, 由于有了 StatefulSet 的限制,serviceName 定义下的Nginx,使用 DNS 访问时 pod0 提供的服务一定是 web-0, pod1 提供的服务是 web-1
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
name: web通过这种严格对应的规则,StatefulSet 就保证了Pod 网络标识的稳定性。
同样的,这种状态不仅体现在网络,还有存储等。
那么一句话总结就是,StatefulSet 就是 Pod 创建时严格按照编号顺序逐一完成工作,Pod 有了编号后,StatefulSet 就使用了 Kubernetes 里的两个标准功能:Headless Service 和 PV/PVC ,实现了对 Pod 拓扑状态和存储状态的维护。
StatefulSet 本身也是Kubernetes 中最复杂的编排对象,不是一句两句能说得清楚的。
DaemonSet
DaemonSet 的主要作用是在 Kubernetes 集群中运行一个 Daemon Pod。所以,这个Pod有如下三个特征:
- 这个Pod运行在 Kubernetes 集群里的每一个节点(Node)上;
- 每个节点只有一个这样的实例Pod;
- 当有新的节点加入 Kubernetes 集群后,该Pod会自动地在新节点上被创建出来;
这样的机制很简单,也有非常重要的意义。
比如,1. 各种网络插件的 Agent 组件,需要运行在每一个节点上,用来处理这个节点上的容器网络;2. 各种存储插件的Agent组件,用来处理这个节点的挂载远程存储目录,操作容器的 Volume 目录;3. 各种监控组件和日志组件,也是必须运行在每一个节点上,负责这个节点上的监控信息和日志收集。
如下这个日志收集组件,管理的是一个 fluented-elasticsearch 的镜像Pod。这个镜像的功能十分实用,通过 fluentd 将 Docker 容器里的日志转发到 ElasticSearch 中。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: k8s.gcr.io/fluentd-elasticsearch:1.20
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers很显然,这个容器挂载了两个hostPath 类型的 Volume,分别对应宿主机的 /var/log 和 /var/lib/docker/containers 目录。
显然,fluentd 启动之后,他会从这个两个目录去收集日志,并将日志转发给 ElasticSearch 保存。
相比于 Deployment ,DaemonSet 只管理Pod 对象,然后通过 nodeAffinity 和 Toleration 这两个调度器的小功能保证每个节点只有一个Pod。
Job 与 CronJob
很显然,我们在Linux 中听过 CronJob 这个概念,离线业务、定时任务。比如,一个仅仅是用来计算 1+1 等于几的Job,运行完即退出。
比如下面这个:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: resouer/ubuntu-bc
command: ["sh", "-c", "echo 'scale=10000; 4*a(1)' | bc -l "]
restartPolicy: Never
backoffLimit: 4计算结果可以通过 kubectl logs <podname> 去查看。
另一种就是 CronJob 了,就是定时任务。比如
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailureJob 这个离线任务的编排很简单,如果需要深入,需要了解 completions 和 parallelism 这两个字段。