kube-schedule 调度实现
kubernetest 中有很多核心的组件,其中一个非常重要的组件是 kube-scheduler。 kube-scheduler 负责将新创建的 Pod 调度到合适的节点上运行。
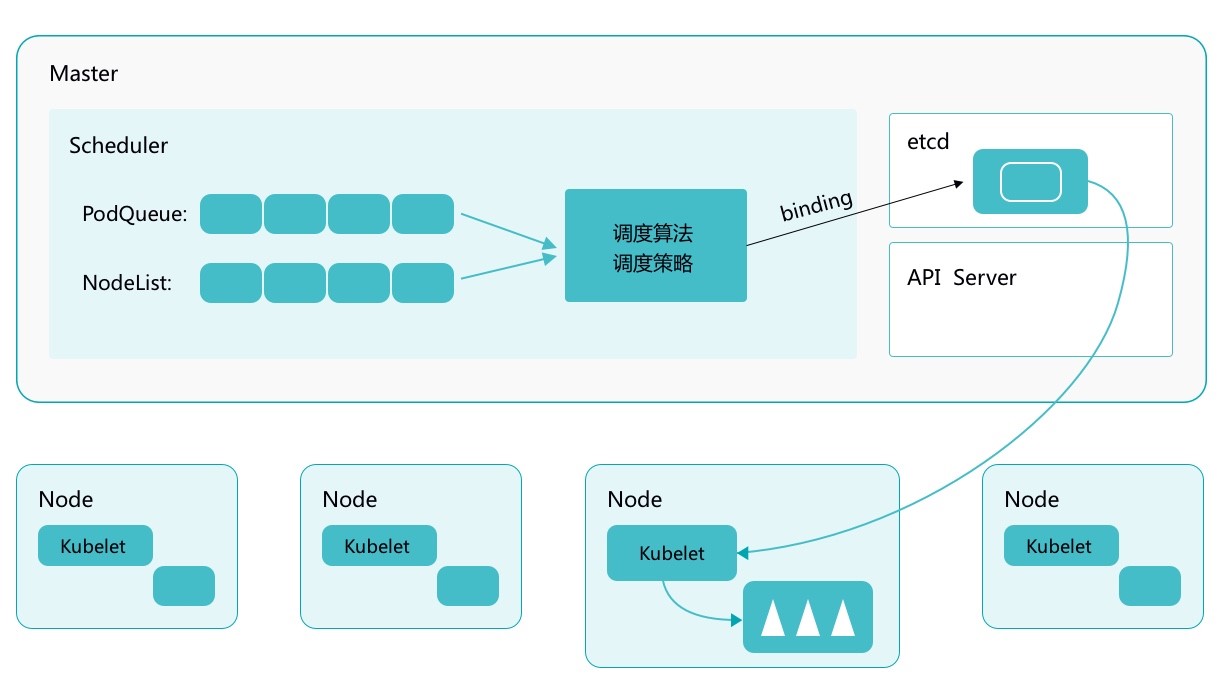
kube-scheduler 的设计
scheduler 在整个系统中承担了 “承上启下” 的重要功能,“承上” 是指负责接受 “Controller Manager” 创建的新 Pod, 为其安排 Node;“启下” 是指安置工作完成后,目标Node 上的 kubelet 服务进程接管后续的绑定创建工作,Pod 是 Kubernetes 中的最小调度单元。
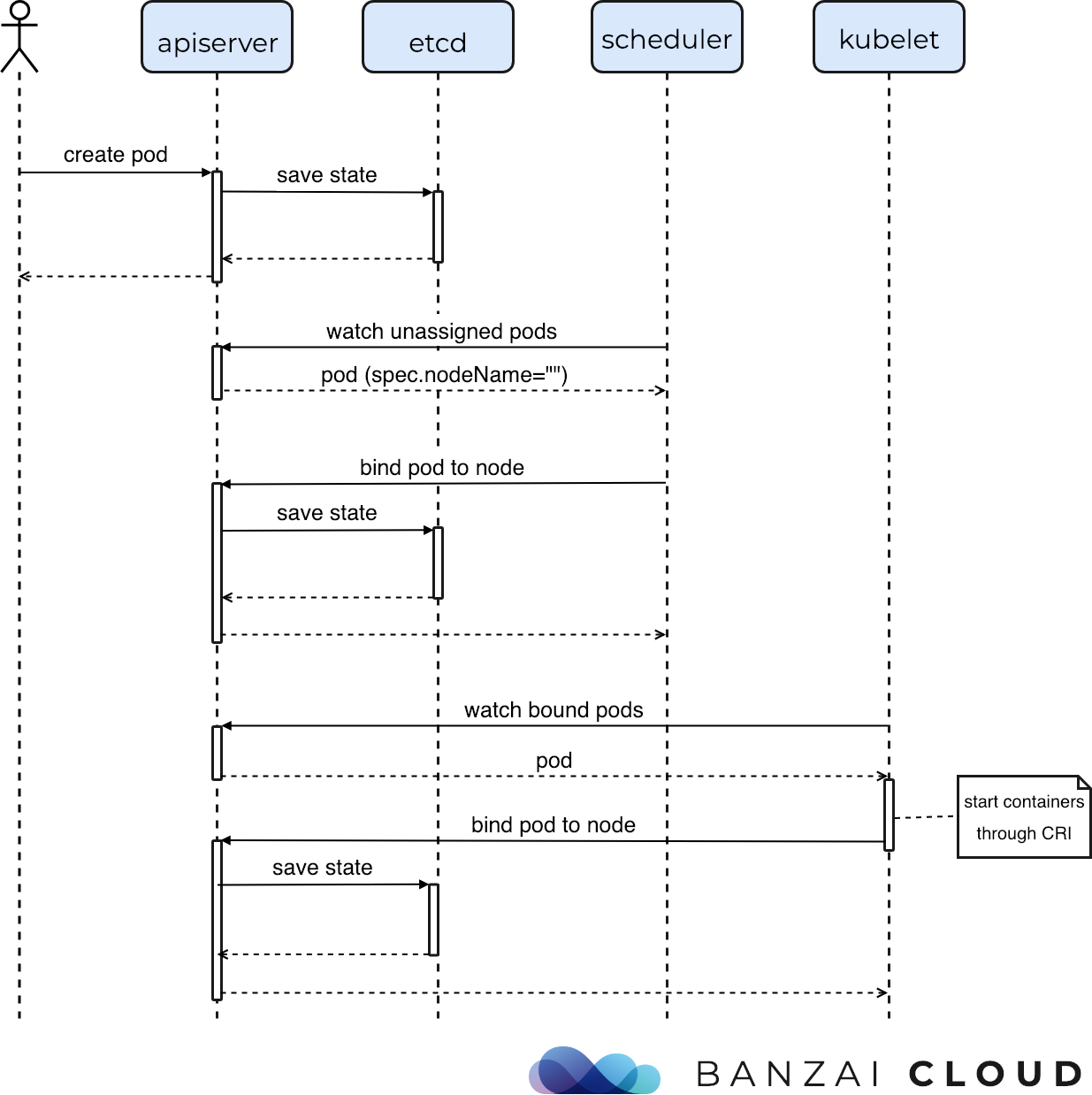
在上图的调度流程中:
第一步 通过 apiserver 的 REST API 创建一个 Pod
然后 apiserver 接收到数据后,将数据写入到 etcd 中。
由于 kube-scheduler 通过 apiserver watch API 一直在监听资源的变化,发现有一个新的 Pod ,但是这个 Pod 还没有和任何的 Node 节点进行绑定,所以就会加入到 调度队列中,kube-scheduler 就会进行调度,选择出一个合适的 Node 节点,将该 Pod 和该目标 Node 进行绑定,绑定后再更新消息到 etcd 中。
目标节点上的 kubelet 通过 apiserver watch API 检测到有一个新的 Pod 调度过来了,他就将该 Pod 的数据传递给后面的容器运行时(container runtime),比如 Docker,让他们去运行该 Pod。
而且 kubelet 还会通过 container runtime 获取 Pod 的状态,然后更新到 apiserver 中,当然最后也是写入到 etcd 中的。
这个过程最重要的就是 apiserver watch API 和 kube-scheduler 的调度策略。
总之,kube-scheduler 的功能就是根据 预选策略(Predicates)和优选 (Priorities)两个步骤。
- 预选(Predicates):kube-scheduler 根据预选策略过滤掉不满足策略的 Node 节点。(比如磁盘不足,CPU 不足等)
- 优选(Priorities):优选会根据优选策略为通过 预选的 Nodes 进行打分排名,选择得分最高的Node,例如,资源越丰富,负载越小等插件plugins 来选出评分最高的 Node。
kube-scheduler 应用源码
以下源码均以 1.20.1 版本为例
调度器设置
服务在调用 Setup(ctx, opts, registryOptions...) 函数来进行调度器的设置工作。
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
if errs := opts.Validate(); len(errs) > 0 {
return nil, nil, utilerrors.NewAggregate(errs)
}
c, err := opts.Config()
if err != nil {
return nil, nil, err
}
// Get the completed config (获取完整的配置)
cc := c.Complete()
// 初始化外部的调度器插件
outOfTreeRegistry := make(runtime.Registry)
for _, option := range outOfTreeRegistryOptions {
if err := option(outOfTreeRegistry); err != nil {
return nil, nil, err
}
}
// 获取事件记录的工厂
recorderFactory := getRecorderFactory(&cc)
completedProfiles := make([]kubeschedulerconfig.KubeSchedulerProfile, 0)
// Create the scheduler. (创建调度器实例)
sched, err := scheduler.New(cc.Client,
cc.InformerFactory,
recorderFactory,
ctx.Done(),
// 调度器的设置
scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
scheduler.WithAlgorithmSource(cc.ComponentConfig.AlgorithmSource),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
scheduler.WithParallelism(cc.ComponentConfig.Parallelism),
scheduler.WithBuildFrameworkCapturer(func(profile kubeschedulerconfig.KubeSchedulerProfile) {
// Profiles are processed during Framework instantiation to set default plugins and configurations. Capturing them for logging
completedProfiles = append(completedProfiles, profile)
}),
)
if err != nil {
return nil, nil, err
}
// 打印或者记录调度器的配置项
if err := options.LogOrWriteConfig(opts.WriteConfigTo, &cc.ComponentConfig, completedProfiles); err != nil {
return nil, nil, err
}
return &cc, sched, nil
}上述代码,创建了一个可用的 *schedulerserverconfig.CompletedConfig 类型的应用配置,后续的 调度服务都会以此配置为基础创建调度器。
其返回了一个 *scheduler.Scheduler 类型的 sched 变量,sched 变量提供的 Run 方法,可以启动 kube-scheduler 的核心逻辑。
runCommand 函数最终调用 Run 函数来启动 kube-scheduler 服务,其内容很多。其中包含
启动事件广播器
等待选主成功
启动 Informer (存储各种元数据,比如节点信息, PVC 等等,详细参考 kubernetes 中 informer 的使用), 并等待缓存同步完成。
kube-scheduler会启动2类 Informer:InformerFactory:用于创建动态 SharedInformer,可以监视任何 Kubernetes 资源对象,不需要提前生成对应的 clientset。
DynInformerFactory:用于创建针对特定 API 组的 SharedInformer,需要提供对应 API 组的 clientset。
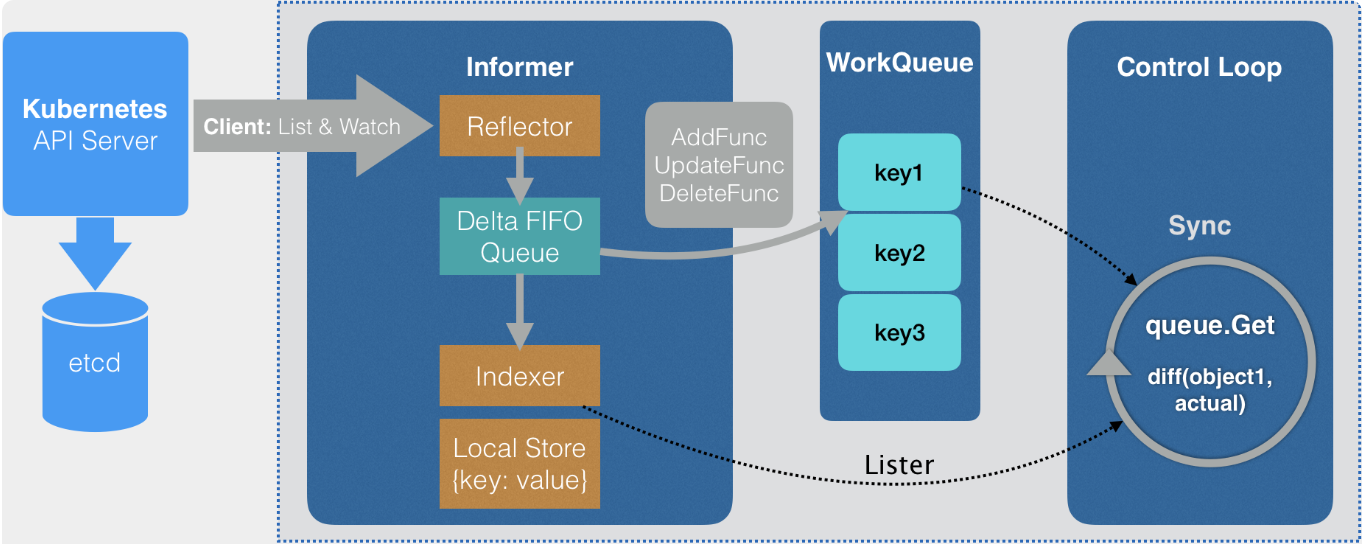
// Start all informers.
cc.InformerFactory.Start(ctx.Done())
// DynInformerFactory can be nil in tests.
if cc.DynInformerFactory != nil {
cc.DynInformerFactory.Start(ctx.Done())
}
// Wait for all caches to sync before scheduling.
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// DynInformerFactory can be nil in tests.
if cc.DynInformerFactory != nil {
cc.DynInformerFactory.WaitForCacheSync(ctx.Done())
}可以看到 Run 中 会启动 Informer,并等待 Informer 的缓存全部完成。
- 运行调度器,最后调用
sched.Run(ctx)运行调度器,调度器在运行期间,kube-scheduler主进程会一直阻塞在sched.Run(ctx)函数的调用处。
kube-scheduler 调度原理
整个 kube-scheduler 核心的调度逻辑是通过 sched.Run(ctx) 来启动,代码如下
// Run begins watching and scheduling. It starts scheduling and blocked until the context is done.
func (sched *Scheduler) Run(ctx context.Context) {
// 启动调度队列,调度队列会 Watch kube-apiserver , 并存储 待调度的 Pod
sched.SchedulingQueue.Run()
// We need to start scheduleOne loop in a dedicated goroutine,
// because scheduleOne function hangs on getting the next item
// from the SchedulingQueue.
// If there are no new pods to schedule, it will be hanging there
// and if done in this goroutine it will be blocking closing
// SchedulingQueue, in effect causing a deadlock on shutdown.
// 不断的轮询,执行 sched.scheduleOne 函数,sched.scheduleOne 函数会消费调度队列中待调度的 Pod // 执行调度流程,完成 Pod 的调度
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
<-ctx.Done()
// 清理并释放资源
sched.SchedulingQueue.Close()
}kube-scheduler 调度模型
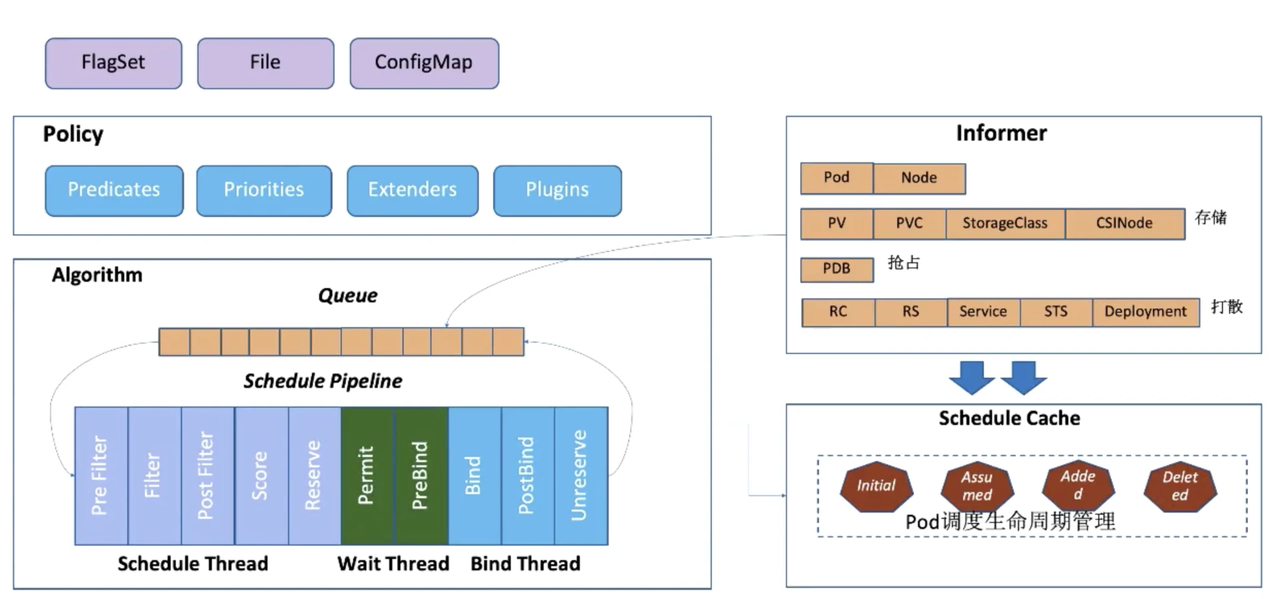
kube-scheduler 的调度原理如上图所示,主要分为 3 大部分:
- Policy:Scheduler 的调度策略启动配置目前支持三种方式,配置文件 / 命令行参数 / ConfigMap。 调度策略可以配置指定的调度主流程要用哪些 过滤器 (Predicates)、打分器(Priorities)、外部扩展的调度器(Extenders),以及最新支持的 SchedulerFramework 的自定义扩展点(Plugins)
- Informer:Scheduler 在启动的时候,以 List + Watch 的从 kube-apiserver 获取调度需要的数据,例如Pods、 Nodes、Persistant Volume(PV),Persistant Volume Claim (PVC) 等等,并将这些数据做一定的预处理,作为调度器的 Cache
- 调度流水线:通过 Informer 将需要调度的 Pod 插入 Queue 中,Pipeline 会循环从 Queue Pop 等待调度的 Pod 放入 Pipeline 执行。调度流水线(Schedule Pipeline) 主要有三个阶段:Scheduler Thread, Wait Thread, Bind Thread 。
- Scheduler Thread 阶段: 从如上的架构图可以看到 Scheduler Thread 会经历 Pre Filter -> Filter -> Post Filter -> Score -> Reserve ,可以简单理解为 Filter -> Score -> Reserve 。
- Filter 阶段用于选择符合 Pod Spec 描述的 Nodes
- Score 阶段用于从 Filter 过后的 Nodes 进行打分和 排序
- Reserve 阶段将 Pod 跟排序后最优 Node 的 NodeCache 中,表示这个 Pod 已经分配到这个 Node 上,让下一个等待调度的 Pod 对这个 Node 进行 Filter 和 Score 的时候能看到刚才分配的 Pod
- Wait Thread 阶段:这个阶段可以用来等待 Pod 关联的资源的 Ready 等待,例如等待 PVC 的 PV 创建成功。
- Bind Thread 阶段: 用于将 Pod 和 Node 的关联持久化 Kube APIServer
- Scheduler Thread 阶段: 从如上的架构图可以看到 Scheduler Thread 会经历 Pre Filter -> Filter -> Post Filter -> Score -> Reserve ,可以简单理解为 Filter -> Score -> Reserve 。
整个 调度流水线只有在 Scheduler Thread 阶段是串行的一个 Pod 一个 Pod 的进行调度,在 Wait 和 Bind 阶段Pod 都是异步并行执行。
Scheduling Framework 调度框架
kube-scheduler 从 v1.15 版本开始,引入了一种非常灵活的调度框架。
调度框架是面向 Kubernetes 调度器的一种插件架构,它由一组直接编译到调度程序中的“插件”API 组成。这些 API 允许大多数调度功能以插件的形式实现,同时使调度 “核心” 保持简单且可维护。每个插件支持不同的调度扩展点,一个插件可以在多个扩展点注册,以执行更复杂或有状态的任务。
每次调度一个 Pod 的尝试分为 两个阶段,即 调度周期 和 绑定周期 。调度周期为 Pod 选择一个节点,绑定周期将一个Pod绑定到一个Node上。调度周期和绑定周期一起被称为 “调度上下文” 。 调度周期是串行运行的,而调度周期可能是同时运行的。如果确定 Pod 不可调度或者存在内部错误,则可以终止调度周期或者绑定周期,Pod 将返回队列并重试。
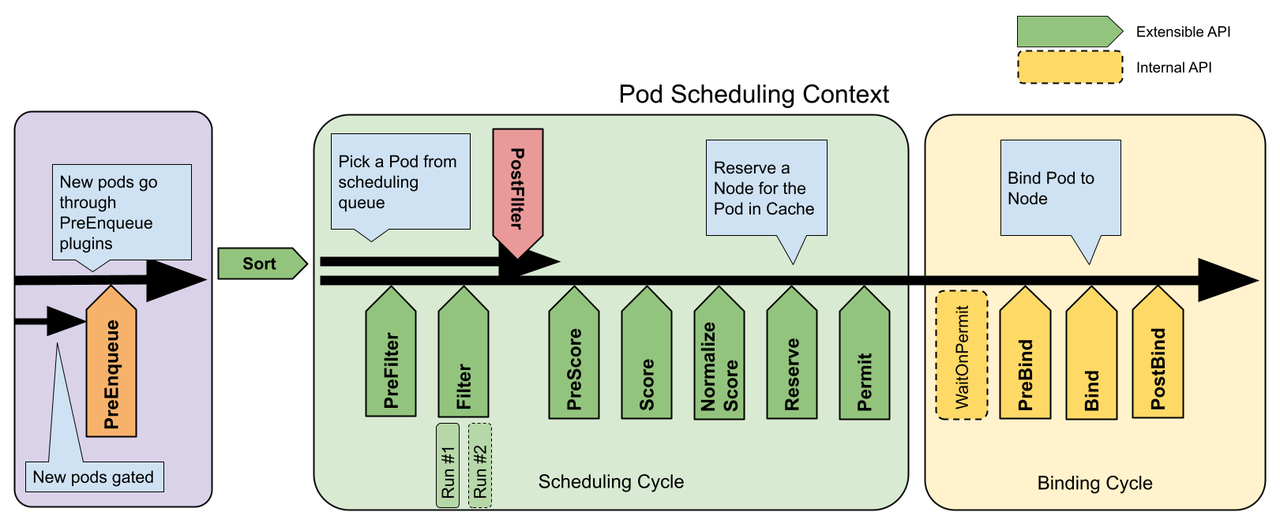
调度扩展点功能描述如下:
| 调度扩展点 | 描述 |
|---|---|
| QueueSort | Sort 扩展用于对 Pod 的待调度队列进行排序,以决定先调度哪个 Pod,Sort 扩展本质上只需要一个 方法 Less(Pod1,Pod2 谁更优先得到调度) |
| PreFilter | PreFilter 扩展用于对 Pod 的信息进行预处理,或者检查一些集群或 Pod 必须满足的前提条件,然后将其存入缓存中等待 Filter 扩展用 |
| Filter | Filter 扩展用于排除那些不能运行该 Pod 的节点,对于每个节点,调度器将按顺序执行 filter 扩展 |
| PostFilter | PostFilter 扩展会对 Score 扩展点的数据做一些预处理操作,然后将其存入缓存中,等待 Score 扩展点执行的时候使用 |
| PreScore | PreScore 扩展会对 Score 扩展点的数据做一些预处理操作,然后将其存入缓存中等待 Score 扩展点执行的时候使用 |
| Score | Score 扩展用于为所有的节点进行打分,调度器将针对每一个节点调用 Score 扩展,最终调度器会把每个 Score 打分器对具体某个节点的评分结果和该扩展的权重合并起来,作为最终的评分结果 |
| NormalizeScore | Normalize score 扩展在调度器对节点进行最终排序之前修改每个节点的评分结果,注册到该扩展点的扩展在被调用时,将获得同 score 扩展的评分结果作为参数,调度框架每执行一次调度,都会调用所有的插件中的一个 normalize score 扩展一次 |
| Reserve | Reserve 是一个通知性质的扩展点,有状态的插件可以用使用该扩展点来获得节点上为 Pod 预留的资源,该事件发生在调度器将Pod绑定到节点之前,目的是避免调度器在等待 Pod 与节点绑定的过程中调度新的 Pod 到节点上时,发生实际使用的资源超出可用资源的情况。这是调度过程的最后一步骤,Pod 进入 reserved 状态以后,要么在绑定失败时触发 Unreserve 扩展,要么在绑定成功时,由 Post-bind 扩展结束绑定过程。 |
| Permit | Permit 扩展在每个 Pod 调度周期的最后调用,用于阻止或者延迟 Pod 与节点的绑定。Permit 扩展可以做下面三件事的一项:1. approve(批准):当所有的permit 扩展都 approve 了 Pod 与 节点的绑定,调度器将继续执行绑定过程 。2. deny(拒绝):如果任何一个 permit 扩展 deny 了 Pod 与节点的绑定,Pod 将被放回到调度队列,此时将触发 Unreserve 扩展 。3. wait(等待):如果一个permit 扩展返回了 wait,则 Pod 将保持在 permit 阶段,直到被其他扩展 approve ,如果超时事件发生,wait 状态变成 deny,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展。 |
| WaitOnPermit | WaitOnPermit 扩展 与 Permit 扩展点配合使用实现延时调度功能(内部默认实现) |
| PreBind | PreBind 扩展用于在 Pod 绑定之前执行某些逻辑,例如,将一个基于网络的数据卷挂载到节点上 |
| Bind | Bind 扩展用于将 Pod 绑定到节点上 |
| PostBind | PostBind 是一个同志性质的扩展,可以用来执行资源清理的动作 |
| Unreserve | Unreserve 是一个通知性质的扩展,如果为 Pod 预留了资源,Pod 又在绑定过程中被拒绝绑定,则 unreserve 扩展将被调用,Unreserve 扩展应该释放已经为 Pod 预留的节点上的计算资源 |
在 Kube-scheduler 的 Framework 中拥有多个 scheduler.WithXXX 来进行设置
type schedulerOptions struct {
// KubeSchedulerConfiguration 的 APIVersion,例如:kubescheduler.config.k8s.io/v1,没有实际作用。
componentConfigVersion string
// 访问 kube-apiserver 的 REST 客户端
kubeConfig *restclient.Config
// Overridden by profile level percentageOfNodesToScore if set in v1.
// 节点得分所使用的节点百分比,如果在 v1 中设置了 profile 级别的 percentageOfNodesToScore,则会被覆盖
percentageOfNodesToScore int32
// Pod 的初始退避时间
podInitialBackoffSeconds int64
// Pod 的最大退避时间
podMaxBackoffSeconds int64
// 最大不可调度 Pod 的持续时间
podMaxInUnschedulablePodsDuration time.Duration
// Contains out-of-tree plugins to be merged with the in-tree registry.
// 包含了外部插件,用于与内部注册表进行合并
frameworkOutOfTreeRegistry frameworkruntime.Registry
// 调度器的配置文件
profiles []schedulerapi.KubeSchedulerProfile
// 调度器的扩展程序
extenders []schedulerapi.Extender
// 用于捕获构建调度框架的函数
frameworkCapturer FrameworkCapturer
// 调度器的并行度
parallelism int32
// 表示是否应用默认配置文件
applyDefaultProfile bool
}通过 scheduler.New 函数来创建一个 *Scheduler 实例,其代码如下:
// New returns a Scheduler
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
recorderFactory profile.RecorderFactory,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {
stopEverything := stopCh
if stopEverything == nil {
stopEverything = wait.NeverStop
}
options := defaultSchedulerOptions
for _, opt := range opts {
opt(&options)
}
// 设置默认的调度策略
if options.applyDefaultProfile {
var versionedCfg configv1.KubeSchedulerConfiguration
scheme.Scheme.Default(&versionedCfg)
cfg := schedulerapi.KubeSchedulerConfiguration{}
if err := scheme.Scheme.Convert(&versionedCfg, &cfg, nil); err != nil {
return nil, err
}
options.profiles = cfg.Profiles
}
// 创建一个 In-Tree Registry 用来保存 kube-scheduler 自带的调度插件
registry := frameworkplugins.NewInTreeRegistry()
// 将 In-Tree 调度插件和 Out-Of-Tree 调度插件进行合并
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
metrics.Register()
// 创建 Extender 调度器插件,
extenders, err := buildExtenders(options.extenders, options.profiles)
if err != nil {
return nil, fmt.Errorf("couldn't build extenders: %w", err)
}
// 创建 Pod、Node 的Lister,用来 List & Watch Pod 和 Node 资源
podLister := informerFactory.Core().V1().Pods().Lister()
nodeLister := informerFactory.Core().V1().Nodes().Lister()
// The nominator will be passed all the way to framework instantiation.
// 根据调度器策略和调度插件,创建调度框架的集合。
nominator := internalqueue.NewPodNominator(podLister)
snapshot := internalcache.NewEmptySnapshot()
clusterEventMap := make(map[framework.ClusterEvent]sets.String)
profiles, err := profile.NewMap(options.profiles, registry, recorderFactory, stopCh,
frameworkruntime.WithComponentConfigVersion(options.componentConfigVersion),
frameworkruntime.WithClientSet(client),
frameworkruntime.WithKubeConfig(options.kubeConfig),
frameworkruntime.WithInformerFactory(informerFactory),
frameworkruntime.WithSnapshotSharedLister(snapshot),
frameworkruntime.WithPodNominator(nominator),
frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(options.frameworkCapturer)),
frameworkruntime.WithClusterEventMap(clusterEventMap),
frameworkruntime.WithParallelism(int(options.parallelism)),
frameworkruntime.WithExtenders(extenders),
)
if err != nil {
return nil, fmt.Errorf("initializing profiles: %v", err)
}
if len(profiles) == 0 {
return nil, errors.New("at least one profile is required")
}
// 创建调度队列
podQueue := internalqueue.NewSchedulingQueue(
profiles[options.profiles[0].SchedulerName].QueueSortFunc(),
informerFactory,
internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodNominator(nominator),
internalqueue.WithClusterEventMap(clusterEventMap),
internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
)
// 创建缓存,主要用来缓存 Node、Pod 等信息,用来提高调度性能
schedulerCache := internalcache.New(durationToExpireAssumedPod, stopEverything)
// Setup cache debugger.
debugger := cachedebugger.New(nodeLister, podLister, schedulerCache, podQueue)
debugger.ListenForSignal(stopEverything)
sched := newScheduler(
schedulerCache,
extenders,
internalqueue.MakeNextPodFunc(podQueue),
stopEverything,
podQueue,
profiles,
client,
snapshot,
options.percentageOfNodesToScore,
)
// 添加 EventHandlers, 根据 Pod,Node 资源的更新情况,将资源放入合适的 Cache 中,根据 CSINode、
// CSIDriver、PersistentVolume 等资源的更新状态将 PreEnqueueCheck中的 Pod 放入到
// BackoffQueue 、 ActiveQueue。
addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(clusterEventMap))
return sched, nil
}调度插件设置
kube-scheduler 是通过一系列的调度插件最终完成 Pod 调度的,在启动 kube-scheduler 时,首先要加载调度插件,调度插件分为 2种,分别是 in-tree 和 out-of-tree 。
- In-tree 插件(内建插件):这些插件是作为 Kubernetes 核心组件的一部分直接编译和交付的,它们与 Kubernetes 的源代码一起维护,并与 Kubernetes 版本保持同步。这些插件以静态库形式打包到 kube-scheduler 的二进制文件中,一些常见的 in-tree 插件包含默认的调度算法,Packed Scheduling 等。
- Out-of-tree 插件(外部插件):这些插件是作为独立项目开发和维护的,它们与 Kubernetes 核心代码分开,并且可以单独部署和更新。本质上,out-of-tree 插件是基于 kubernetes 的调度器扩展点进行开发的。这些插件以独立的二进制文件的形式存在。
Out-Of-Tree 插件初始化
kube-scheduler 首先加载的是 out-of-tree 插件。在 main 文件中,就会调用 app.NewSchedulerCommand 来创建一个 Scheduler Application 。例如 scheduler-plugins 的 scheduler 实现。
func main() {
// Register custom plugins to the scheduler framework.
// Later they can consist of scheduler profile(s) and hence
// used by various kinds of workloads.
command := app.NewSchedulerCommand(
app.WithPlugin(capacityscheduling.Name, capacityscheduling.New),
app.WithPlugin(coscheduling.Name, coscheduling.New),
app.WithPlugin(loadvariationriskbalancing.Name, loadvariationriskbalancing.New),
app.WithPlugin(networkoverhead.Name, networkoverhead.New),
app.WithPlugin(topologicalsort.Name, topologicalsort.New),
app.WithPlugin(noderesources.AllocatableName, noderesources.NewAllocatable),
app.WithPlugin(noderesourcetopology.Name, noderesourcetopology.New),
app.WithPlugin(preemptiontoleration.Name, preemptiontoleration.New),
app.WithPlugin(targetloadpacking.Name, targetloadpacking.New),
app.WithPlugin(lowriskovercommitment.Name, lowriskovercommitment.New),
// Sample plugins below.
// app.WithPlugin(crossnodepreemption.Name, crossnodepreemption.New),
app.WithPlugin(podstate.Name, podstate.New),
app.WithPlugin(qos.Name, qos.New),
)
code := cli.Run(command)
os.Exit(code)
}在调用 app.NewSchedulerCommand 时,通过 app.WithPlugin 选项模式,传入了期望加载到 kube-scheduler 中的 out-of-tree 插件。
- 开发 out-of-tree 插件时,为了避免改动 kubernetes 源码仓库中的
kube-scheduler源码,我们一般会另启动一个项目,例如:scheduler-plugins 。在新项目中我们调用 Kubernetes 源码仓库中的 app 包,来创建一个跟 kube-scheduler 完全一致的调度组件。 - 因为创建应用时,直接调用的是
k8s.io/kubernetes/cmd/kube-scheduler/app.NewSchedulerCommand函数,所以创建的调度器跟kube-scheduler能够完全保持兼容,也就是说从 配置、使用方式、逻辑等等各个方面,都跟 kubernetes 的调度器完全一样,唯一不同就是加载了指定的 out-of-tree 插件。
一个具体的外部插件实现可以参考:PodState 调度插件
In-Tree 插件初始化
在 kube-scheduler 中用 scheduler.New 方法中,通过 registry := frameworkplugins.NewInTreeRegistry() 创建了 in-tree 插件。 NewInTreeRegistry 函数实现如下:
func NewInTreeRegistry() runtime.Registry {
fts := plfeature.Features{
EnableDynamicResourceAllocation: feature.DefaultFeatureGate.Enabled(features.DynamicResourceAllocation),
EnableReadWriteOncePod: feature.DefaultFeatureGate.Enabled(features.ReadWriteOncePod),
EnableVolumeCapacityPriority: feature.DefaultFeatureGate.Enabled(features.VolumeCapacityPriority),
EnableMinDomainsInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MinDomainsInPodTopologySpread),
EnableNodeInclusionPolicyInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.NodeInclusionPolicyInPodTopologySpread),
EnableMatchLabelKeysInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MatchLabelKeysInPodTopologySpread),
EnablePodSchedulingReadiness: feature.DefaultFeatureGate.Enabled(features.PodSchedulingReadiness),
EnablePodDisruptionConditions: feature.DefaultFeatureGate.Enabled(features.PodDisruptionConditions),
EnableInPlacePodVerticalScaling: feature.DefaultFeatureGate.Enabled(features.InPlacePodVerticalScaling),
EnableSidecarContainers: feature.DefaultFeatureGate.Enabled(features.SidecarContainers),
}
registry := runtime.Registry{
dynamicresources.Name: runtime.FactoryAdapter(fts, dynamicresources.New),
imagelocality.Name: imagelocality.New,
tainttoleration.Name: tainttoleration.New,
nodename.Name: nodename.New,
nodeports.Name: nodeports.New,
nodeaffinity.Name: nodeaffinity.New,
podtopologyspread.Name: runtime.FactoryAdapter(fts, podtopologyspread.New),
nodeunschedulable.Name: nodeunschedulable.New,
noderesources.Name: runtime.FactoryAdapter(fts, noderesources.NewFit),
noderesources.BalancedAllocationName: runtime.FactoryAdapter(fts, noderesources.NewBalancedAllocation),
volumebinding.Name: runtime.FactoryAdapter(fts, volumebinding.New),
volumerestrictions.Name: runtime.FactoryAdapter(fts, volumerestrictions.New),
volumezone.Name: volumezone.New,
nodevolumelimits.CSIName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCSI),
nodevolumelimits.EBSName: runtime.FactoryAdapter(fts, nodevolumelimits.NewEBS),
nodevolumelimits.GCEPDName: runtime.FactoryAdapter(fts, nodevolumelimits.NewGCEPD),
nodevolumelimits.AzureDiskName: runtime.FactoryAdapter(fts, nodevolumelimits.NewAzureDisk),
nodevolumelimits.CinderName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCinder),
interpodaffinity.Name: interpodaffinity.New,
queuesort.Name: queuesort.New,
defaultbinder.Name: defaultbinder.New,
defaultpreemption.Name: runtime.FactoryAdapter(fts, defaultpreemption.New),
schedulinggates.Name: runtime.FactoryAdapter(fts, schedulinggates.New),
}
return registry
}kube-scheduler 支持的 In-Tree 有诸如 PrioritySort(按优先级排序)、DefaultPreemption(抢占调度,高优先级踢掉低优先级 Pod )、InterPodAffinity(根据Pod之间的亲和性关系,调度具有相关性的 Pod 到同一节点上)等等。
如 NodeName In-Tree 插件的实现:
NodeName 插件实现位于:pkg/scheduler/framework/plugins/nodename/node_name.go 文件中。node_name.go 文件内容如下:
// NodeName is a plugin that checks if a pod spec node name matches the current node.
type NodeName struct{}
var _ framework.FilterPlugin = &NodeName{}
var _ framework.EnqueueExtensions = &NodeName{}
const (
// Name is the name of the plugin used in the plugin registry and configurations.
Name = names.NodeName
// ErrReason returned when node name doesn't match.
ErrReason = "node(s) didn't match the requested node name"
)
// EventsToRegister returns the possible events that may make a Pod
// failed by this plugin schedulable.
func (pl *NodeName) EventsToRegister() []framework.ClusterEventWithHint {
return []framework.ClusterEventWithHint{
{Event: framework.ClusterEvent{Resource: framework.Node, ActionType: framework.Add | framework.Update}},
}
}
// Name returns name of the plugin. It is used in logs, etc.
func (pl *NodeName) Name() string {
return Name
}
// Filter invoked at the filter extension point.
func (pl *NodeName) Filter(ctx context.Context, _ *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
if !Fits(pod, nodeInfo) {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReason)
}
return nil
}
// Fits actually checks if the pod fits the node.
func Fits(pod *v1.Pod, nodeInfo *framework.NodeInfo) bool {
return len(pod.Spec.NodeName) == 0 || pod.Spec.NodeName == nodeInfo.Node().Name
}
// New initializes a new plugin and returns it.
func New(_ context.Context, _ runtime.Object, _ framework.Handle) (framework.Plugin, error) {
return &NodeName{}, nil
}调度策略初始化
kube-scheduler 在调度时,会选定一个调度策略,同时,kube-scheduler 也支持自定义调度策略,kube-scheduler 支持以下 3 种调度策略:
Scheduler Extender: 社区最初提供的方案是通过Extender 的形式来扩展 scheduler。Extender 是外部服务,支持 Filter、Preempt、Prioritize 和 Bind 的扩展,scheduler 运行到相应的阶段,通过调用 Extender 注册的 webhook 来运行扩展的逻辑,影响调度流程中个阶段的决策结果。
Multiple schedulers: Scheduler 在 Kubernetes 集群中其实类似于一个特殊的 Controller, 通过监听 Pod 和 Node 的信息,给 Pod 挑选最佳的节点,更新 Pod 的 spec.NodeName 的信息来将调度结果同步到节点,所以对于部分有特殊的调度需求的用户,有些开发者通过自研 Custom Scheduler 来完成以上的流程,然后通过和 Default-scheduler 同时部署的方式,来支持自己的特殊的调度需求,在
Pod.Spec.SchedulerName字段中,可以设置该 Pod 的调度策略,默认为 :default。Scheduling Framework: Scheduling Framework 在原有的调度流程中,定义了丰富的扩展点接口,开发者可以以插件的形式实现自己的需求,通过这种方式来讲用户的调度逻辑集成到 Scheduling Framwork 中。
在 kube-scheduler 的源码中,目前只有 Scheduler Extender 和 Scheduling Framework,因为 Multiple schedulers 中的 Custom Scheduler 实现已经不属于 kube-scheduler 代码了。
这里,我们来看下 kube-scheduler 是如何设置调度策略的,kube-scheduler 调度策略的设置是字啊 scheudler.New 函数中设置的,相关代码如下:
func New(ctx context.Context,
client clientset.Interface,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
recorderFactory profile.RecorderFactory,
opts ...Option) (*Scheduler, error) {
...
// applyDefaultProfile 值恒为 false,该代码分支不会运行
if options.applyDefaultProfile {
var versionedCfg configv1.KubeSchedulerConfiguration
scheme.Scheme.Default(&versionedCfg)
cfg := schedulerapi.KubeSchedulerConfiguration{}
if err := scheme.Scheme.Convert(&versionedCfg, &cfg, nil); err != nil {
return nil, err
}
options.profiles = cfg.Profiles
}
registry := frameworkplugins.NewInTreeRegistry()
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
metrics.Register()
extenders, err := buildExtenders(logger, options.extenders, options.profiles)
if err != nil {
return nil, fmt.Errorf("couldn't build extenders: %w", err)
}
...
profiles, err := profile.NewMap(ctx, options.profiles, registry, recorderFactory,
frameworkruntime.WithComponentConfigVersion(options.componentConfigVersion),
frameworkruntime.WithClientSet(client),
frameworkruntime.WithKubeConfig(options.kubeConfig),
frameworkruntime.WithInformerFactory(informerFactory),
frameworkruntime.WithSnapshotSharedLister(snapshot),
frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(options.frameworkCapturer)),
frameworkruntime.WithParallelism(int(options.parallelism)),
frameworkruntime.WithExtenders(extenders),
frameworkruntime.WithMetricsRecorder(metricsRecorder),
)
if err != nil {
return nil, fmt.Errorf("initializing profiles: %v", err)
}
if len(profiles) == 0 {
return nil, errors.New("at least one profile is required")
}
preEnqueuePluginMap := make(map[string][]framework.PreEnqueuePlugin)
queueingHintsPerProfile := make(internalqueue.QueueingHintMapPerProfile)
for profileName, profile := range profiles {
preEnqueuePluginMap[profileName] = profile.PreEnqueuePlugins()
queueingHintsPerProfile[profileName] = buildQueueingHintMap(profile.EnqueueExtensions())
}
podQueue := internalqueue.NewSchedulingQueue(
profiles[options.profiles[0].SchedulerName].QueueSortFunc(),
informerFactory,
internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodLister(podLister),
internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
internalqueue.WithPreEnqueuePluginMap(preEnqueuePluginMap),
internalqueue.WithQueueingHintMapPerProfile(queueingHintsPerProfile),
internalqueue.WithPluginMetricsSamplePercent(pluginMetricsSamplePercent),
internalqueue.WithMetricsRecorder(*metricsRecorder),
)
for _, fwk := range profiles {
fwk.SetPodNominator(podQueue)
}
...
sched := &Scheduler{
...
Profiles: profiles,
...
}
...
}第一步:options.applyDefaultProfile 是否为 true , 来决定是否设置默认的调度策略。
第二步:调用 registry := frameworkplugins.NewInTreeRegistry() 创建了调度插件注册表,注册表中,保存了所有的 in-tree 和 out-of-tree 调度插件。
第三步:调用 buildExtenders 来构建 Extender 调度策略,
extenders, err := buildExtenders(logger, options.extenders, options.profiles)
if err != nil {
return nil, fmt.Errorf("couldn't build extenders: %w", err)
}option.extender 是通过 KubeSchedulerConfiguration 配置文件中的字段来设置的
type KubeSchedulerConfiguration struct {
...
Extenders []Extender
...
}
type Extender struct {
// URLPrefix是extender可用的URL前缀
URLPrefix string
// FilterVerb是过滤调用的动词,如果不支持则为空。当向extender发出过滤调用时,此动词将附加到URLPrefix。
FilterVerb string
// PreemptVerb是抢占调用的动词,如果不支持则为空。当向extender发出抢占调用时,此动词将附加到URLPrefix。
PreemptVerb string
// PrioritizeVerb是优先调用的动词,如果不支持则为空。当向extender发出优先调用时,此动词将附加到URLPrefix。
PrioritizeVerb string
// Prioritize调用生成的节点分数的数值乘数。
// 权重应为正整数
Weight int64
// BindVerb是绑定调用的动词,如果不支持则为空。当向extender发出绑定调用时,此动词将附加到URLPrefix。
// 如果此方法由extender实现,则由extender负责将Pod绑定到apiserver。只有一个extender可以实现此函数。
BindVerb string
// EnableHTTPS指定是否应使用https与extender通信
EnableHTTPS bool
// TLSConfig指定传输层安全配置
TLSConfig *ExtenderTLSConfig
// HTTPTimeout指定与extender的调用的超时持续时间。过滤超时会导致Pod的调度失败。优先超时将被忽略,k8s/其他extender的优先级将用于选择节点。
HTTPTimeout metav1.Duration
// NodeCacheCapable指定extender是否能够缓存节点信息,因此调度器应该只发送有关符合条件的节点的最小信息,假设extender已经缓存了集群中所有节点的完整详细信息
NodeCacheCapable bool
// ManagedResources是由此extender管理的扩展资源的列表。
// - 如果Pod请求了此列表中至少一个扩展资源,则Pod将在过滤、优先和绑定(如果extender是绑定者)阶段发送到extender。如果为空或未指定,则所有Pod将发送到此extender。
// - 如果资源的IgnoredByScheduler设置为true,kube-scheduler将跳过在谓词中检查该资源。
// +optional
ManagedResources []ExtenderManagedResource
// Ignorable指定extender是否可忽略,即当extender返回错误或不可访问时,调度不应失败。
Ignorable bool
}可以看到 Extender 类型的调度器插件,实际上就是一个 HTTP 服务器,通过请求 HTTP 服务,来决定调度是否成功。
buildExtenders 函数会返回 []framework.Extender 类型的变量,framework.Exetnder 接口定义如下:
type Extender interface {
// Name returns a unique name that identifies the extender.
Name() string
// Filter based on extender-implemented predicate functions. The filtered list is
// expected to be a subset of the supplied list.
// The failedNodes and failedAndUnresolvableNodes optionally contains the list
// of failed nodes and failure reasons, except nodes in the latter are
// unresolvable.
Filter(pod *v1.Pod, nodes []*v1.Node) (filteredNodes []*v1.Node, failedNodesMap extenderv1.FailedNodesMap, failedAndUnresolvable extenderv1.FailedNodesMap, err error)
// Prioritize based on extender-implemented priority functions. The returned scores & weight
// are used to compute the weighted score for an extender. The weighted scores are added to
// the scores computed by Kubernetes scheduler. The total scores are used to do the host selection.
Prioritize(pod *v1.Pod, nodes []*v1.Node) (hostPriorities *extenderv1.HostPriorityList, weight int64, err error)
// Bind delegates the action of binding a pod to a node to the extender.
Bind(binding *v1.Binding) error
// IsBinder returns whether this extender is configured for the Bind method.
IsBinder() bool
// IsInterested returns true if at least one extended resource requested by
// this pod is managed by this extender.
IsInterested(pod *v1.Pod) bool
// ProcessPreemption returns nodes with their victim pods processed by extender based on
// given:
// 1. Pod to schedule
// 2. Candidate nodes and victim pods (nodeNameToVictims) generated by previous scheduling process.
// The possible changes made by extender may include:
// 1. Subset of given candidate nodes after preemption phase of extender.
// 2. A different set of victim pod for every given candidate node after preemption phase of extender.
ProcessPreemption(
pod *v1.Pod,
nodeNameToVictims map[string]*extenderv1.Victims,
nodeInfos NodeInfoLister,
) (map[string]*extenderv1.Victims, error)
// SupportsPreemption returns if the scheduler extender support preemption or not.
SupportsPreemption() bool
// IsIgnorable returns true indicates scheduling should not fail when this extender
// is unavailable. This gives scheduler ability to fail fast and tolerate non-critical extenders as well.
IsIgnorable() bool
}通过framework.Extender 接口定义,我们不难发现,Extender 类型的调度策略,只支持以下的调度阶段的处理:Filter、Preempt、Prioritize 和 Bind 。
接着, 通过 profile.NewMap 创建了调度策略,并将调度策略保存在 Map 类型的变量中,Map 类型定义如下:
type Map map[string]framework.Framework可以看到 profiles 中保存了所有的调度策略,map 的 key 是调度策略的名称,value 是调度策略框架,通过 Key 查找需要用到的调度策略,通过 value 来执行具体的 Pod 调度。framework.Framework 定义如下:
type Framework interface {
Handle
// PreEnqueuePlugins returns the registered preEnqueue plugins.
PreEnqueuePlugins() []PreEnqueuePlugin
// EnqueueExtensions returns the registered Enqueue extensions.
EnqueueExtensions() []EnqueueExtensions
// QueueSortFunc returns the function to sort pods in scheduling queue
QueueSortFunc() LessFunc
// RunPreFilterPlugins runs the set of configured PreFilter plugins. It returns
// *Status and its code is set to non-success if any of the plugins returns
// anything but Success. If a non-success status is returned, then the scheduling
// cycle is aborted.
// It also returns a PreFilterResult, which may influence what or how many nodes to
// evaluate downstream.
RunPreFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod) (*PreFilterResult, *Status)
// RunPostFilterPlugins runs the set of configured PostFilter plugins.
// PostFilter plugins can either be informational, in which case should be configured
// to execute first and return Unschedulable status, or ones that try to change the
// cluster state to make the pod potentially schedulable in a future scheduling cycle.
RunPostFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
// RunPreBindPlugins runs the set of configured PreBind plugins. It returns
// *Status and its code is set to non-success if any of the plugins returns
// anything but Success. If the Status code is "Unschedulable", it is
// considered as a scheduling check failure, otherwise, it is considered as an
// internal error. In either case the pod is not going to be bound.
RunPreBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// RunPostBindPlugins runs the set of configured PostBind plugins.
RunPostBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
// RunReservePluginsReserve runs the Reserve method of the set of
// configured Reserve plugins. If any of these calls returns an error, it
// does not continue running the remaining ones and returns the error. In
// such case, pod will not be scheduled.
RunReservePluginsReserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// RunReservePluginsUnreserve runs the Unreserve method of the set of
// configured Reserve plugins.
RunReservePluginsUnreserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
// RunPermitPlugins runs the set of configured Permit plugins. If any of these
// plugins returns a status other than "Success" or "Wait", it does not continue
// running the remaining plugins and returns an error. Otherwise, if any of the
// plugins returns "Wait", then this function will create and add waiting pod
// to a map of currently waiting pods and return status with "Wait" code.
// Pod will remain waiting pod for the minimum duration returned by the Permit plugins.
RunPermitPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// WaitOnPermit will block, if the pod is a waiting pod, until the waiting pod is rejected or allowed.
WaitOnPermit(ctx context.Context, pod *v1.Pod) *Status
// RunBindPlugins runs the set of configured Bind plugins. A Bind plugin may choose
// whether or not to handle the given Pod. If a Bind plugin chooses to skip the
// binding, it should return code=5("skip") status. Otherwise, it should return "Error"
// or "Success". If none of the plugins handled binding, RunBindPlugins returns
// code=5("skip") status.
RunBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// HasFilterPlugins returns true if at least one Filter plugin is defined.
HasFilterPlugins() bool
// HasPostFilterPlugins returns true if at least one PostFilter plugin is defined.
HasPostFilterPlugins() bool
// HasScorePlugins returns true if at least one Score plugin is defined.
HasScorePlugins() bool
// ListPlugins returns a map of extension point name to list of configured Plugins.
ListPlugins() *config.Plugins
// ProfileName returns the profile name associated to a profile.
ProfileName() string
// PercentageOfNodesToScore returns percentageOfNodesToScore associated to a profile.
PercentageOfNodesToScore() *int32
// SetPodNominator sets the PodNominator
SetPodNominator(nominator PodNominator)
}可以看到 framework.Framework 中包含了,各个调度扩展点的调用方法,每个扩展点,有可能包含多个调度插件。后面会详细接受,具体是如何调度 Pod 的。
这里,我们再来看下 profile.NewMap 具体是如何创建调度策略的 map 结构体的,NewMap 定义如下:
func NewMap(ctx context.Context, cfgs []config.KubeSchedulerProfile, r frameworkruntime.Registry, recorderFact RecorderFactory,
opts ...frameworkruntime.Option) (Map, error) {
m := make(Map)
v := cfgValidator{m: m}
for _, cfg := range cfgs {
p, err := newProfile(ctx, cfg, r, recorderFact, opts...)
if err != nil {
return nil, fmt.Errorf("creating profile for scheduler name %s: %v", cfg.SchedulerName, err)
}
if err := v.validate(cfg, p); err != nil {
return nil, err
}
m[cfg.SchedulerName] = p
}
return m, nil
}通过上述代码,不难发现,NewMap 遍历 KubeSchedulerConfiguration 配置文件中的 Profiles 字段,针对每一个调度策略配置,调用 newProfile 创建 framework.Framework ,并以 map 的形式保存在 Map 类型的变量中。framework.Framework 是一个接口类型,具体实现为: framework 。frameworkImpl 是一个重要的结构体,可以理解是一个具体的调度引擎。frameworkImpl 包含了很多方法,这些方法用来完成一次完整的 Pod调度。
接着,调用 internalqueue.NewSchedulingQueue 创建了一个优先级调度队列,并使用调度策略对调度队列进行了设置。
调度队列管理
kube-scheduler 会从调度队列中获取需要调度的 Pod 和目标 Node 列表,通过调度流程,最终将 Pod 调度到合适的 Node 节点上。
创建调度队列
先来看下,调度队列是如何创建的,在 scheduler.New 中,通过以下代码创建了优先级调度队列 podQueue:
func New(ctx context.Context,
client clientset.Interface,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
recorderFactory profile.RecorderFactory,
opts ...Option) (*Scheduler, error) {
...
// 首先遍历 profiles 获取其对应的已注册好的 PreEnqueuePlugins 插件,这些插件会在 Pods 被添加到 activeQ 之前调用。
preEnqueuePluginMap := make(map[string][]framework.PreEnqueuePlugin)
queueingHintsPerProfile := make(internalqueue.QueueingHintMapPerProfile)
for profileName, profile := range profiles {
preEnqueuePluginMap[profileName] = profile.PreEnqueuePlugins()
queueingHintsPerProfile[profileName] = buildQueueingHintMap(profile.EnqueueExtensions())
}
// 初始化一个优先队列作为调度队列
podQueue := internalqueue.NewSchedulingQueue(
profiles[options.profiles[0].SchedulerName].QueueSortFunc(),
informerFactory,
// 设置 pod 的 Initial阶段的 Backoff 的持续时间
internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
// 最大backoff持续时间
internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodLister(podLister),
// 设置一个pod在 unschedulablePods 队列停留的最长时间
internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
internalqueue.WithPreEnqueuePluginMap(preEnqueuePluginMap),
internalqueue.WithQueueingHintMapPerProfile(queueingHintsPerProfile),
// 指标相关
internalqueue.WithPluginMetricsSamplePercent(pluginMetricsSamplePercent),
internalqueue.WithMetricsRecorder(*metricsRecorder),
)
...
sched := &Scheduler{
Cache: schedulerCache,
client: client,
nodeInfoSnapshot: snapshot,
percentageOfNodesToScore: options.percentageOfNodesToScore,
Extenders: extenders,
StopEverything: stopEverything,
SchedulingQueue: podQueue,
Profiles: profiles,
logger: logger,
}
sched.NextPod = podQueue.Pop
sched.applyDefaultHandlers()
if err = addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(queueingHintsPerProfile)); err != nil {
return nil, fmt.Errorf("adding event handlers: %w", err)
}
return sched, nil
}podQueue 数据结构如下:
type PriorityQueue struct {
*nominator
stop chan struct{}
clock clock.Clock
// pod initial backoff duration.
podInitialBackoffDuration time.Duration
// pod maximum backoff duration.
podMaxBackoffDuration time.Duration
// the maximum time a pod can stay in the unschedulablePods.
podMaxInUnschedulablePodsDuration time.Duration
cond sync.Cond
// inFlightPods holds the UID of all pods which have been popped out for which Done
// hasn't been called yet - in other words, all pods that are currently being
// processed (being scheduled, in permit, or in the binding cycle).
//
// The values in the map are the entry of each pod in the inFlightEvents list.
// The value of that entry is the *v1.Pod at the time that scheduling of that
// pod started, which can be useful for logging or debugging.
inFlightPods map[types.UID]*list.Element
// inFlightEvents holds the events received by the scheduling queue
// (entry value is clusterEvent) together with in-flight pods (entry
// value is *v1.Pod). Entries get added at the end while the mutex is
// locked, so they get serialized.
//
// The pod entries are added in Pop and used to track which events
// occurred after the pod scheduling attempt for that pod started.
// They get removed when the scheduling attempt is done, at which
// point all events that occurred in the meantime are processed.
//
// After removal of a pod, events at the start of the list are no
// longer needed because all of the other in-flight pods started
// later. Those events can be removed.
inFlightEvents *list.List
// activeQ is heap structure that scheduler actively looks at to find pods to
// schedule. Head of heap is the highest priority pod.
activeQ *heap.Heap
// podBackoffQ is a heap ordered by backoff expiry. Pods which have completed backoff
// are popped from this heap before the scheduler looks at activeQ
podBackoffQ *heap.Heap
// unschedulablePods holds pods that have been tried and determined unschedulable.
unschedulablePods *UnschedulablePods
// schedulingCycle represents sequence number of scheduling cycle and is incremented
// when a pod is popped.
schedulingCycle int64
// moveRequestCycle caches the sequence number of scheduling cycle when we
// received a move request. Unschedulable pods in and before this scheduling
// cycle will be put back to activeQueue if we were trying to schedule them
// when we received move request.
// TODO: this will be removed after SchedulingQueueHint goes to stable and the feature gate is removed.
moveRequestCycle int64
// preEnqueuePluginMap is keyed with profile name, valued with registered preEnqueue plugins.
preEnqueuePluginMap map[string][]framework.PreEnqueuePlugin
// queueingHintMap is keyed with profile name, valued with registered queueing hint functions.
queueingHintMap QueueingHintMapPerProfile
// closed indicates that the queue is closed.
// It is mainly used to let Pop() exit its control loop while waiting for an item.
closed bool
nsLister listersv1.NamespaceLister
metricsRecorder metrics.MetricAsyncRecorder
// pluginMetricsSamplePercent is the percentage of plugin metrics to be sampled.
pluginMetricsSamplePercent int
// isSchedulingQueueHintEnabled indicates whether the feature gate for the scheduling queue is enabled.
isSchedulingQueueHintEnabled bool
}PriorityQueue 优先级队列中,包含了以下3个重要的子队列:activeQ、backoffQ、unscheduleQ 。
activeQ:Scheduler 启动的时候所有等待被调度的 Pod 都会进入activeQ,activeQ会按照 Pod 的 priority 进行排序,Scheduler PipeLine 会从activeQ获取一个 Pod 并执行调度流程 (Pipeline) , 当调度失败之后,会直接根据情况选择进入unschedulableQ或者backoffQ, 如果在当前 Pod 调度期间 Node Cache 、 Pod Cache 等 Scheduler Cache 有变化就进入backoffQ,否则进入unschedulableQ。backBackoffQ: 称为退避队列, 持有从unschedulablePods中移走的 Pod,并将在其 backoff periods 退避结束时移动到activeQ队列,Pod 在退避队列中等待并定期尝试进行重新调度。重新调度的频率会按照一个指数级的算法定时增加,从而充分探索可用的资源,直到找到可以分配给该 Pod 的节点。unschedulablePods(unschedulableQ) : 不可调度 Pod 的列表,也可以将其理解为不可调度队列, 持有已经尝试进行调度并且确定是不可以调度的 Pod.
backoff机制是并发编程中常见的一种机制,即如果任务反复执行依旧失败,则会按次增长等待调度时间,降低重试效率,从而避免反复失败浪费调度资源
针对调度失败的pod会优先存储在backoff队列中,等待后续重试
unschedulableQ 会顶起较长时间(例如 60 秒)刷入 activeQ 或者 backoffQ ,或者在 Scheduler Cache 发生变化的时候触发关联的 Pod 刷入 activeQ 或者 backoffQ ;backoffQ 会以 backoff 机制相比 unschedulableQ 比较快地让待调度的 Pod 进入 activeQ 进行重新调度。
Pod 在3个队列的移动过程如下图所示:
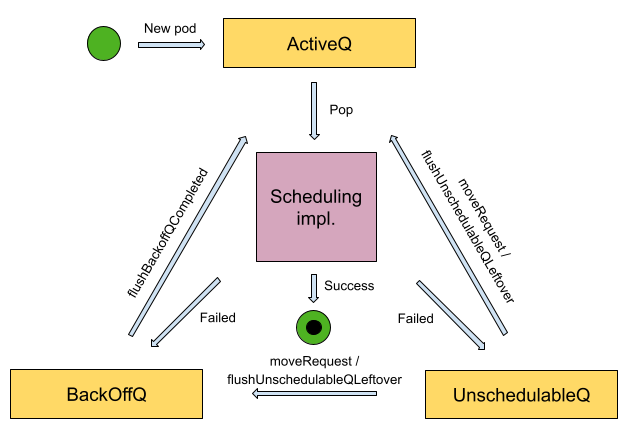
三个队列都是 Kubernetes 调度器的三个基本导向队列,调度器将使用其内置策略和其他算法来对它们进行维护和管理。
在创建调度队列时,对队列进行了以下的设置:
指定了队列中的 Pod 排序方法:默认为调度策略列表中,第一个调度策略的 QueueSortFunc 函数;
PodInitialBackoffDuration: 定义在尝试调度失败后的初始回退时间间隔,当调度器无法调度成功时,会等待一段时间后再重新尝试调度,这个参数指定了初始的等待时间间隔。PodMaxBackoffDuration: 定义在尝试调度失败后的最大回退时间间隔。如果调度器多次尝试调度失败,会逐渐增加等待时间间隔, 但不会超过此参数定义的最大值。PodMaxInUnschedulablePodsDuration: 定义 Pod 在无法调度的情况下最大的等待时间。如果 Pod 一直无法被调度,会在达到此参数定义的最大等待时间后被抛弃;PreEnqueuePluginMap: 一个映射,将调度器的预调度插件与其配置进行关联。预调度插件在调度器尝试将 Pod 放入调度队列之前运行,用于对 Pod 进行预处理或过滤;QueueingHintMapPerProfile: 一个映射,将调度器的队列与调度器的配置文件中关联,以影响器在调度队列的位置和优先级;pluginMetricsSmaplePercent: 定义插件度量指标采样的百分比。在 Kubernetes 调度器中,插件可以生成度量指标来监控其性能。
Pod 入队列
在 r 中通过 Kubernetes EventHandler 的方式,来在 Pod 、Node 有变更时,将 Pod 添加到指定的调度队列中和缓冲中,将Node 添加到缓冲中:
- 如果
len(pod.Spec.NodeName) == 0, 说明 Pod 还没有被调度过,则会将 Pod 添加到activeQ或podBackoffQ;
Pod 出队列
在 cmd/kube-scheduler/app/server.go文件中,通过sched.Run启动了调度器。sched.Run函数实现如下:
func (sched *Scheduler) Run(ctx context.Context) {
logger := klog.FromContext(ctx)
sched.SchedulingQueue.Run(logger)
// We need to start scheduleOne loop in a dedicated goroutine,
// because scheduleOne function hangs on getting the next item
// from the SchedulingQueue.
// If there are no new pods to schedule, it will be hanging there
// and if done in this goroutine it will be blocking closing
// SchedulingQueue, in effect causing a deadlock on shutdown.
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
<-ctx.Done()
sched.SchedulingQueue.Close()
}首先,通过调用 sched.SchedulingQueue.Run() 启动优先队列服务。
// Run starts the goroutine to pump from podBackoffQ to activeQ
func (p *PriorityQueue) Run() {
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
go wait.Until(p.flushUnschedulablePodsLeftover, 30*time.Second, p.stop)
}这里有2个点:
- 每1秒 执行一个
p.flushBackoffQCompleted()函数,将所有的已完成退避的 Pod 从backoffQ队列移动到activeQ队列,重新尝试调度。 - 每30秒执行一次
flushUnschedulablePodsLeftover()函数,将所有停留在unschedulablePods中时间超过podMaxInUnschedulablePodsDuration的 Pod 移动到backoffQ或activeQ队列。
接着,go wait.UntilWithContext(ctx, sched.scheduleOne, 0) 会新建一个 goroutine,在 goroutine 中,会不断的循环执行 sched.scheduleOne 。sched.scheduleOne 用来从 Pod 调度队列中取出一个待调度的 Pod ,根据调度策略和插件进行 Pod 调度。
Pod 调度流程 (调度起点:scheduleOne 函数)
调度流程,是 kube-scheduler 最核心的流程,而 scheduleOne 函数正是其体现。
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting.
func (sched *Scheduler) scheduleOne(ctx context.Context) {
logger := klog.FromContext(ctx)
// 从 scheduler 的待调度 pod 队列中取出一个 pod 进行调度
podInfo, err := sched.NextPod(logger)
if err != nil {
logger.Error(err, "Error while retrieving next pod from scheduling queue")
return
}
// 如果获取的 podInfo 或p odInfo.Pod 为 nil,说明队列中暂无需要调度的 Pod,直接退出当前调度循环
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
// TODO(knelasevero): Remove duplicated keys from log entry calls
// When contextualized logging hits GA
// https://github.com/kubernetes/kubernetes/issues/111672
logger = klog.LoggerWithValues(logger, "pod", klog.KObj(pod))
ctx = klog.NewContext(ctx, logger)
logger.V(4).Info("About to try and schedule pod", "pod", klog.KObj(pod))
// sched.frameworkForPod(pod) 函数调用,会根据 pod.Spec.SchedulerName 获取 pod 指定的调度策略的名字。
// 之后,从调度策略注册表中,获取个该调度策略的 framework.Framework,framework.Framework包含了调度需要的调度插件。
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
logger.Error(err, "Error occurred")
return
}
// 检查是否需要调度,以下 Pod 不会被调度:
// 1. 如果 Pod 正在被删除中,则不会调度该 Pod;
// 2. 如果该 Pod 已经被 Assumed 过,则不会调度该 Pod。被 Assumed 过的 Pod 会被存放到一个叫 assumedPods 的缓存中。
if sched.skipPodSchedule(ctx, fwk, pod) {
return
}
logger.V(3).Info("Attempting to schedule pod", "pod", klog.KObj(pod))
// Synchronously attempt to find a fit for the pod.
start := time.Now()
// 如果 Pod 能够被调度,会使用 framework.NewCycleState() 函数,创建一个新的调度周期状态对象state,
// 用来保存调度过程中的状态信息,比如已经被调度的 Pod、还未被调度的 Pod 等。
// 这个调度周期状态对象在 kube-scheduler 的调度过程中会被使用,来记录和管理调度的状态,具体通常会包含以下信息:
// 1. 已经被调度的 Pod 列表:记录已经被成功调度到节点上的 Pod。
// 2. 待调度的 Pod 列表:记录还未被调度的 Pod。
// 3. 节点状态信息:记录集群中各个节点的状态,比如资源利用情况、标签信息等。
// 4. 调度器的配置信息:记录调度器的配置参数,比如调度策略、优先级规则等。
// 这些信息会在 kube-scheduler 的调度循环中被不断更新和引用,以保证调度器能够根据最新的状态信息为新的 Pod 进行合适的节点选择。
state := framework.NewCycleState()
state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)
// Initialize an empty podsToActivate struct, which will be filled up by plugins or stay empty.
podsToActivate := framework.NewPodsToActivate()
state.Write(framework.PodsToActivateKey, podsToActivate)
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
// 调用 sched.schedulingCycle 函数,进入到调度循环中,调度循环的输出是调度结果。
scheduleResult, assumedPodInfo, status := sched.schedulingCycle(schedulingCycleCtx, state, fwk, podInfo, start, podsToActivate)
if !status.IsSuccess() {
sched.FailureHandler(schedulingCycleCtx, fwk, assumedPodInfo, status, scheduleResult.nominatingInfo, start)
return
}
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
// 如果调度成功,则会创建一个 goroutine,该 goroutine 是一个绑定循环,用来异步的将待调度的 Pod 和分配的 Node 进行绑定,
// 也即设置 pod.Spec.NodeName 字段。可以看到,调度 Pod 是同步的,但是绑定 Pod 的调度结果时,是异步的,以提高调度并发。
go func() {
bindingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
metrics.Goroutines.WithLabelValues(metrics.Binding).Inc()
defer metrics.Goroutines.WithLabelValues(metrics.Binding).Dec()
// 进度到绑定循环中,绑定循环后面会详细介绍
status := sched.bindingCycle(bindingCycleCtx, state, fwk, scheduleResult, assumedPodInfo, start, podsToActivate)
if !status.IsSuccess() {
sched.handleBindingCycleError(bindingCycleCtx, state, fwk, assumedPodInfo, start, scheduleResult, status)
return
}
// Usually, DonePod is called inside the scheduling queue,
// but in this case, we need to call it here because this Pod won't go back to the scheduling queue.
// 标记 Pod 调度完成
sched.SchedulingQueue.Done(assumedPodInfo.Pod.UID)
}()
}调度循环(Scheduling Cycle)
当获取到一个待调度的 Pod 后,就会调用sched.schedulingCycle 进入到调度循环中。schedulingCycle函数执行 Pod 调度逻辑。schedulingCycle函数中,会按顺序依次执行以下调度扩展点:
| 扩展点 | 描述 |
|---|---|
| PreFilter | PreFilter 扩展用于对 Pod 的信息进行预处理,或者检查一些集群或 Pod 必须满足的前提条件,然后将其存入缓存中待 Filter 扩展点执行的时候使用,如果 Prefilter 返回了 error,则调度过程终止 |
| Filter | FIlter 扩展用于排除那些不能运行该 Pod 的节点,对于每一个节点,调度器都将按顺序执行 filter 插件;如果任何一个 filter 将节点标记为不可用,则余下的 Filter 都将不会再执行,调度器可以同时对多个节点执行 Filter 扩展 |
| PostFilter | PostFilter 如果在 Filter 扩展点全部节点都被过滤掉了,没有合适的节点进行调度,才会执行 PostFilter 扩展点,如果启用了 Pod 抢占特性,那么会在这个扩展点进行抢占操作,可以用于 logs/metircs |
| PreScore | PreScore 扩展会对 Score 扩展点的数据做一些预处理操作,然后将其存入缓存中待 Score 扩展点执行的时候使用 |
| Score | Score 扩展用于为所有可选节点进行打分,调度器将针对每一个节点调用每个 Sore 扩展,评分结果是一个范围内的整数,代表最小和最大分数。在 normalize scoring 阶段,调度器将会把每个 score 扩展对具体某个节点的评分结果和该扩展的权重合并起来,作为最终评分结果 |
| Reserve | Reserve 是一个通知性质的扩展点,有状态的插件可以使用该扩展点来获得节点上为 Pod 预留的资源,该事件发生在调度器将 Pod 绑定到节点之前,目的是避免调度器在等待 Pod 与节点绑定的过程中调度新的 Pod 到节点上时,发生实际使用资源超出可用资源的情况(因为绑定 Pod 到节点上是异步发生的)。这是调度过程的最后一个步骤,Pod 进入 reserved 状态以后,要么在绑定失败时触发 Unreserve 扩展,要么在绑定成功时,由 Post-bind 扩展结束绑定过程 |
| Permit | Permit 扩展在每个 Pod 调度周期的最后调用,用于阻止或者延迟 Pod 与节点的绑定。Permit 扩展可以做下面三件事中的一项:1. approve(批准):当所有的 permit 扩展都 approve 了 Pod 与节点的绑定,调度器将继续执行绑定过程;2. deny(拒绝):如果任何一个 permit 扩展 deny 了 Pod 与节点的绑定,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展;3. wait(等待):如果一个 permit 扩展返回了 wait,则 Pod 将保持在 permit 阶段,直到被其他扩展 approve,如果超时事件发生,wait 状态变成 deny,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展 |
| 以下是 调度循环的核心代码: |
// schedulingCycle tries to schedule a single Pod.
func (sched *Scheduler) schedulingCycle(
ctx context.Context,
state *framework.CycleState,
fwk framework.Framework,
podInfo *framework.QueuedPodInfo,
start time.Time,
podsToActivate *framework.PodsToActivate,
) (ScheduleResult, *framework.QueuedPodInfo, *framework.Status) {
logger := klog.FromContext(ctx)
// 获取调度的 Pod 对象,类型为 *v1.Pod
pod := podInfo.Pod
// 尝试调度该 Pod 到合适的 Node 上,Node 列表通过 sched.nodeInfoSnapshot.NodeInfos().List() 方法来获取
scheduleResult, err := sched.SchedulePod(ctx, fwk, state, pod)
if err != nil {
// 如果返回的调度错误是 ErrNoNodesAvailable,则调度失败,退出调度循环
if err == ErrNoNodesAvailable {
status := framework.NewStatus(framework.UnschedulableAndUnresolvable).WithError(err)
return ScheduleResult{nominatingInfo: clearNominatedNode}, podInfo, status
}
fitError, ok := err.(*framework.FitError)
if !ok {
logger.Error(err, "Error selecting node for pod", "pod", klog.KObj(pod))
return ScheduleResult{nominatingInfo: clearNominatedNode}, podInfo, framework.AsStatus(err)
}
// SchedulePod() may have failed because the pod would not fit on any host, so we try to
// preempt, with the expectation that the next time the pod is tried for scheduling it
// will fit due to the preemption. It is also possible that a different pod will schedule
// into the resources that were preempted, but this is harmless.
// 执行 PostFilter 调度扩展点
if !fwk.HasPostFilterPlugins() {
logger.V(3).Info("No PostFilter plugins are registered, so no preemption will be performed")
return ScheduleResult{}, podInfo, framework.NewStatus(framework.Unschedulable).WithError(err)
}
// Run PostFilter plugins to attempt to make the pod schedulable in a future scheduling cycle.
// 如果调度失败,并且调度策略的插件列表中,有插件实现了 PostFilter 扩展点,则执行调度抢占逻辑
result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)
msg := status.Message()
fitError.Diagnosis.PostFilterMsg = msg
if status.Code() == framework.Error {
logger.Error(nil, "Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", msg)
} else {
logger.V(5).Info("Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", msg)
}
var nominatingInfo *framework.NominatingInfo
if result != nil {
nominatingInfo = result.NominatingInfo
}
return ScheduleResult{nominatingInfo: nominatingInfo}, podInfo, framework.NewStatus(framework.Unschedulable).WithError(err)
}
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInSeconds(start))
// Tell the cache to assume that a pod now is running on a given node, even though it hasn't been bound yet.
// This allows us to keep scheduling without waiting on binding to occur.
assumedPodInfo := podInfo.DeepCopy()
assumedPod := assumedPodInfo.Pod
// assume modifies `assumedPod` by setting NodeName=scheduleResult.SuggestedHost
// 调用 sched.assume,在 scheduler 的 cache 中记录这个 pod 已经调度了,因为更新 pod 的 nodeName 是异步操作,
// 防止 pod 被重复调度
err = sched.assume(logger, assumedPod, scheduleResult.SuggestedHost)
if err != nil {
// This is most probably result of a BUG in retrying logic.
// We report an error here so that pod scheduling can be retried.
// This relies on the fact that Error will check if the pod has been bound
// to a node and if so will not add it back to the unscheduled pods queue
// (otherwise this would cause an infinite loop).
return ScheduleResult{nominatingInfo: clearNominatedNode}, assumedPodInfo, framework.AsStatus(err)
}
// Run the Reserve method of reserve plugins.
// 执行 Reserve 插件扩展点,Reserve 是一个通知性质的扩展点,有状态的插件可以使用该扩展点来获得节点上为 Pod 预留的资源,
// 该事件发生在调度器将 Pod 绑定到节点之前,目的是避免调度器在等待 Pod 与节点绑定的过程中调度新的 Pod 到节点上时,
// 发生实际使用资源超出可用资源的情况(因为绑定 Pod 到节点上是异步发生的)。这是调度过程的最后一个步骤,
// Pod 进入 reserved 状态以后,要么在绑定失败时触发 Unreserve 扩展,要么在绑定成功时,由 Post-bind 扩展结束绑定过程。
if sts := fwk.RunReservePluginsReserve(ctx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
// trigger un-reserve to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(logger, assumedPod); forgetErr != nil {
logger.Error(forgetErr, "Scheduler cache ForgetPod failed")
}
if sts.IsRejected() {
fitErr := &framework.FitError{
NumAllNodes: 1,
Pod: pod,
Diagnosis: framework.Diagnosis{
NodeToStatusMap: framework.NodeToStatusMap{scheduleResult.SuggestedHost: sts},
},
}
fitErr.Diagnosis.AddPluginStatus(sts)
return ScheduleResult{nominatingInfo: clearNominatedNode}, assumedPodInfo, framework.NewStatus(sts.Code()).WithError(fitErr)
}
return ScheduleResult{nominatingInfo: clearNominatedNode}, assumedPodInfo, sts
}
// Run "permit" plugins.
// 执行 Permit 插件扩展点,用于阻止或者延迟 Pod 与节点的绑定。Permit 扩展可以做下面三件事中的一项:
// 1. approve(批准):当所有的 permit 扩展都 approve 了 Pod 与节点的绑定,调度器将继续执行绑定过程;
// 2. deny(拒绝):如果任何一个 permit 扩展 deny 了 Pod 与节点的绑定,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展;
// 3. wait(等待):如果一个 permit 扩展返回了 wait,则 Pod 将保持在 permit 阶段,直到被其他扩展 approve。
// 如果超时事件发生,wait 状态变成 deny,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展
// 为某些资源预留(reserve)空间,以确保在节点上可以为指定的 Pod 预留需要的资源。
runPermitStatus := fwk.RunPermitPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if !runPermitStatus.IsWait() && !runPermitStatus.IsSuccess() {
// trigger un-reserve to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(logger, assumedPod); forgetErr != nil {
logger.Error(forgetErr, "Scheduler cache ForgetPod failed")
}
if runPermitStatus.IsRejected() {
fitErr := &framework.FitError{
NumAllNodes: 1,
Pod: pod,
Diagnosis: framework.Diagnosis{
NodeToStatusMap: framework.NodeToStatusMap{scheduleResult.SuggestedHost: runPermitStatus},
},
}
fitErr.Diagnosis.AddPluginStatus(runPermitStatus)
return ScheduleResult{nominatingInfo: clearNominatedNode}, assumedPodInfo, framework.NewStatus(runPermitStatus.Code()).WithError(fitErr)
}
return ScheduleResult{nominatingInfo: clearNominatedNode}, assumedPodInfo, runPermitStatus
}
// At the end of a successful scheduling cycle, pop and move up Pods if needed.
if len(podsToActivate.Map) != 0 {
sched.SchedulingQueue.Activate(logger, podsToActivate.Map)
// Clear the entries after activation.
podsToActivate.Map = make(map[string]*v1.Pod)
}
return scheduleResult, assumedPodInfo, nil
}schedulingCycle 函数会调用 sched.SchedulePod 来进行 Pod 调度,sched.SchedulePod 的具体实现如下:
// schedulePod tries to schedule the given pod to one of the nodes in the node list.
// If it succeeds, it will return the name of the node.
// If it fails, it will return a FitError with reasons.
func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (resultScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
// 更新调度器的缓存快照,以确保调度器的节点信息是最新的
if err := sched.Cache.UpdateSnapshot(klog.FromContext(ctx), sched.nodeInfoSnapshot); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
// 如果缓存快照中,没有可调度的 Node,则直接返回 ErrNoNodesAvailable 错误
if sched.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
// 调用 sched.findNodesThatFitPod 方法,查找适合调度给定 Pod 的节点,获取可行节点列表、诊断信息和可能的错误
feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
if err != nil {
return result, err
}
trace.Step("Computing predicates done")
// 如果没有找到适合的节点,返回一个 FitError,其中包含未能调度的 Pod、所有节点数量和诊断信息
if len(feasibleNodes) == 0 {
return result, &framework.FitError{
Pod: pod,
NumAllNodes: sched.nodeInfoSnapshot.NumNodes(),
Diagnosis: diagnosis,
}
}
// When only one node after predicate, just use it.
// 如果只有一个适合的节点,则直接将 Pod 调度到该节点上
if len(feasibleNodes) == 1 {
return ScheduleResult{
SuggestedHost: feasibleNodes[0].Name,
EvaluatedNodes: 1 + len(diagnosis.NodeToStatusMap),
FeasibleNodes: 1,
}, nil
}
// 调用 prioritizeNodes 方法对可行节点进行优先级排序,获取一个优先级列表
// prioritizeNodes 函数中执行了 PreScore、Score 扩展点
priorityList, err := prioritizeNodes(ctx, sched.Extenders, fwk, state, pod, feasibleNodes)
if err != nil {
return result, err
}
// 调用 selectHost 方法选择最终的节点,并返回建议的节点名称、评估节点的数量和可行节点的数量
host, _, err := selectHost(priorityList, numberOfHighestScoredNodesToReport)
trace.Step("Prioritizing done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + len(diagnosis.NodeToStatusMap),
FeasibleNodes: len(feasibleNodes),
}, err
}schedulePod 根据一系列的调度扩展点,最终为 Pod 选择一个最佳调度点。schedulePod 方法中,有以下 3 个核心函数调用:
sched.findNodesThatFidPod(ctx, fwk, state, pod):查找合适调度给定 Pod 的节点,获取可行节点列表、诊断信息和可能的错误;prioritizeNodes(ctx, sched.Extenders, fwk, state, pod, feasibleNodes):对可行节点进行优先级排序,获取一个优先级列表;selectHost(priorityList, numberOfHighestScoredNodesToReport):选择最终的节点,并返回建议的节点名称、评估节点的数量和可行节点的数量。
下面是几个函数的具体实现:
findNodesThatFitPod 方法实现了一个 kube-scheduler 调度扩展点中的 PreFilter、Filter 扩展点,具体实现代码如下:
// findNodesThatFitPod 实现了 kube-scheduler 调度扩展点中的以下扩展点:PreFilter、Filter 扩展点
func (sched *Scheduler) findNodesThatFitPod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node,framework.Diagnosis, error) {
logger := klog.FromContext(ctx)
diagnosis := framework.Diagnosis{
NodeToStatusMap: make(framework.NodeToStatusMap),
}
// 获取待调度的节点列表
allNodes, err := sched.nodeInfoSnapshot.NodeInfos().List()
if err != nil {
return nil, diagnosis, err
}
// 执行 PreFilter 扩展点
preRes, s := fwk.RunPreFilterPlugins(ctx, state, pod)
// 如果预过滤结果不成功,根据状态处理不同情况
// 1. 如果状态不是被拒绝,则将所有节点标记为相同状态,并记录预过滤消息;
// 2. 返回相应的诊断信息和错误。
if !s.IsSuccess() {
if !s.IsRejected() {
return nil, diagnosis, s.AsError()
}
// All nodes in NodeToStatusMap will have the same status so that they can be handled in the preemption.
// Some non trivial refactoring is needed to avoid this copy.
for _, n := range allNodes {
diagnosis.NodeToStatusMap[n.Node().Name] = s
}
// Record the messages from PreFilter in Diagnosis.PreFilterMsg.
msg := s.Message()
diagnosis.PreFilterMsg = msg
logger.V(5).Info("Status after running PreFilter plugins for pod", "pod", klog.KObj(pod), "status", msg)
diagnosis.AddPluginStatus(s)
return nil, diagnosis, nil
}
// "NominatedNodeName" can potentially be set in a previous scheduling cycle as a result of preemption.
// This node is likely the only candidate that will fit the pod, and hence we try it first before iterating over all nodes.
if len(pod.Status.NominatedNodeName) > 0 {
feasibleNodes, err := sched.evaluateNominatedNode(ctx, pod, fwk, state, diagnosis)
if err != nil {
logger.Error(err, "Evaluation failed on nominated node", "pod", klog.KObj(pod), "node", pod.Status.NominatedNodeName)
}
// Nominated node passes all the filters, scheduler is good to assign this node to the pod.
if len(feasibleNodes) != 0 {
return feasibleNodes, diagnosis, nil
}
}
nodes := allNodes
if !preRes.AllNodes() {
nodes = make([]*framework.NodeInfo, 0, len(preRes.NodeNames))
for n := range preRes.NodeNames {
nInfo, err := sched.nodeInfoSnapshot.NodeInfos().Get(n)
if err != nil {
return nil, diagnosis, err
}
nodes = append(nodes, nInfo)
}
}
// 运行 Filter 扩展点,对节点进行过滤,获取符合条件的节点列表
feasibleNodes, err := sched.findNodesThatPassFilters(ctx, fwk, state, pod, &diagnosis, nodes)
// always try to update the sched.nextStartNodeIndex regardless of whether an error has occurred
// this is helpful to make sure that all the nodes have a chance to be searched
processedNodes := len(feasibleNodes) + len(diagnosis.NodeToStatusMap)
sched.nextStartNodeIndex = (sched.nextStartNodeIndex + processedNodes) % len(nodes)
if err != nil {
return nil, diagnosis, err
}
feasibleNodes, err = findNodesThatPassExtenders(ctx, sched.Extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)
if err != nil {
return nil, diagnosis, err
}
return feasibleNodes, diagnosis, nil
}prioritizeNodes 函数代码实现如下:
// prioritizeNodes prioritizes the nodes by running the score plugins,
// which return a score for each node from the call to RunScorePlugins().
// The scores from each plugin are added together to make the score for that node, then
// any extenders are run as well.
// All scores are finally combined (added) to get the total weighted scores of all nodes
func prioritizeNodes(
ctx context.Context,
extenders []framework.Extender,
fwk framework.Framework,
state *framework.CycleState,
pod *v1.Pod,
nodes []*v1.Node,
) ([]framework.NodePluginScores, error) { logger := klog.FromContext(ctx)
// If no priority configs are provided, then all nodes will have a score of one.
// This is required to generate the priority list in the required format
if len(extenders) == 0 && !fwk.HasScorePlugins() {
result := make([]framework.NodePluginScores, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodePluginScores{
Name: nodes[i].Name,
TotalScore: 1,
})
}
return result, nil
}
// Run PreScore plugins.
preScoreStatus := fwk.RunPreScorePlugins(ctx, state, pod, nodes)
if !preScoreStatus.IsSuccess() {
return nil, preScoreStatus.AsError()
}
// Run the Score plugins.
nodesScores, scoreStatus := fwk.RunScorePlugins(ctx, state, pod, nodes)
if !scoreStatus.IsSuccess() {
return nil, scoreStatus.AsError()
}
// Additional details logged at level 10 if enabled.
loggerVTen := logger.V(10)
if loggerVTen.Enabled() {
for _, nodeScore := range nodesScores {
for _, pluginScore := range nodeScore.Scores {
loggerVTen.Info("Plugin scored node for pod", "pod", klog.KObj(pod), "plugin", pluginScore.Name, "node", nodeScore.Name, "score", pluginScore.Score)
}
}
}
if len(extenders) != 0 && nodes != nil {
// allNodeExtendersScores has all extenders scores for all nodes.
// It is keyed with node name.
allNodeExtendersScores := make(map[string]*framework.NodePluginScores, len(nodes))
var mu sync.Mutex
var wg sync.WaitGroup
for i := range extenders {
if !extenders[i].IsInterested(pod) {
continue
}
wg.Add(1)
go func(extIndex int) {
metrics.Goroutines.WithLabelValues(metrics.PrioritizingExtender).Inc()
defer func() {
metrics.Goroutines.WithLabelValues(metrics.PrioritizingExtender).Dec()
wg.Done()
}()
prioritizedList, weight, err := extenders[extIndex].Prioritize(pod, nodes)
if err != nil {
// Prioritization errors from extender can be ignored, let k8s/other extenders determine the priorities
logger.V(5).Info("Failed to run extender's priority function. No score given by this extender.", "error", err, "pod", klog. KObj(pod), "extender", extenders[extIndex].Name())
return
}
mu.Lock()
defer mu.Unlock()
for i := range *prioritizedList {
nodename := (*prioritizedList)[i].Host
score := (*prioritizedList)[i].Score
if loggerVTen.Enabled() {
loggerVTen.Info("Extender scored node for pod", "pod", klog.KObj(pod), "extender", extenders[extIndex].Name(), "node", nodename, "score", score)
}
// MaxExtenderPriority may diverge from the max priority used in the scheduler and defined by MaxNodeScore,
// therefore we need to scale the score returned by extenders to the score range used by the scheduler.
finalscore := score * weight * (framework.MaxNodeScore / extenderv1.MaxExtenderPriority)
if allNodeExtendersScores[nodename] == nil {
allNodeExtendersScores[nodename] = &framework.NodePluginScores{
Name: nodename,
Scores: make([]framework.PluginScore, 0, len(extenders)),
}
}
allNodeExtendersScores[nodename].Scores = append(allNodeExtendersScores[nodename].Scores, framework.PluginScore{
Name: extenders[extIndex].Name(),
Score: finalscore,
})
allNodeExtendersScores[nodename].TotalScore += finalscore
}
}(i)
}
// wait for all go routines to finish
wg.Wait()
for i := range nodesScores {
if score, ok := allNodeExtendersScores[nodes[i].Name]; ok {
nodesScores[i].Scores = append(nodesScores[i].Scores, score.Scores...)
nodesScores[i].TotalScore += score.TotalScore
}
}
}
if loggerVTen.Enabled() {
for i := range nodesScores {
loggerVTen.Info("Calculated node's final score for pod", "pod", klog.KObj(pod), "node", nodesScores[i].Name, "score", nodesScores[i]. TotalScore)
}
}
return nodesScores, nil
}selectHost 函数代码如下:
// selectHost takes a prioritized list of nodes and then picks one
// in a reservoir sampling manner from the nodes that had the highest score.
// It also returns the top {count} Nodes,
// and the top of the list will be always the selected host.
func selectHost(nodeScoreList []framework.NodePluginScores, count int) (string, []framework.NodePluginScores, error) {
// 如果 nodeScoreList 为空,说明其中没有适合调度的 Node,直接返回空的列表
if len(nodeScoreList) == 0 {
return "", nil, errEmptyPriorityList
}
var h nodeScoreHeap = nodeScoreList
heap.Init(&h)
cntOfMaxScore := 1
selectedIndex := 0 // The top of the heap is the NodeScoreResult with the highest score.
sortedNodeScoreList := make([]framework.NodePluginScores, 0, count)
sortedNodeScoreList = append(sortedNodeScoreList, heap.Pop(&h).(framework.NodePluginScores))
// This for-loop will continue until all Nodes with the highest scores get checked for a reservoir sampling,
// and sortedNodeScoreList gets (count - 1) elements.
for ns := heap.Pop(&h).(framework.NodePluginScores); ; ns = heap.Pop(&h).(framework.NodePluginScores) {
if ns.TotalScore != sortedNodeScoreList[0].TotalScore && len(sortedNodeScoreList) == count {
break
}
if ns.TotalScore == sortedNodeScoreList[0].TotalScore {
cntOfMaxScore++
if rand.Intn(cntOfMaxScore) == 0 {
// Replace the candidate with probability of 1/cntOfMaxScore
selectedIndex = cntOfMaxScore - 1
}
}
sortedNodeScoreList = append(sortedNodeScoreList, ns)
if h.Len() == 0 {
break
}
}
if selectedIndex != 0 {
// replace the first one with selected one
previous := sortedNodeScoreList[0]
sortedNodeScoreList[0] = sortedNodeScoreList[selectedIndex]
sortedNodeScoreList[selectedIndex] = previous
}
if len(sortedNodeScoreList) > count {
sortedNodeScoreList = sortedNodeScoreList[:count]
}
return sortedNodeScoreList[0].Name, sortedNodeScoreList, nil
}绑定循环(Binding Cycle)
在 scheduleOne 函数中,当调度循环返回了一个可用的节点之后,接下来就需要进入到绑定循环中,绑定循环,可以将该 Node 和 待调度的 Pod ,进行绑定,所谓绑定,其实就是设置 pod.Spec.NodeName 字段的值为节点的名字。
可以看 sched.bindingCycle 函数的具体实现,以此来了解 kube-scheduler 是如何将 Node 绑定给 Pod 的,sched.bindingCycle 实现了 PreBind、Bind 和 PostBind 调度扩展点。代码如下:
// bindingCycle tries to bind an assumed Pod.
func (sched *Scheduler) bindingCycle(
ctx context.Context,
state *framework.CycleState,
fwk framework.Framework,
scheduleResult ScheduleResult,
assumedPodInfo *framework.QueuedPodInfo,
start time.Time,
podsToActivate *framework.PodsToActivate) *framework.Status {
logger := klog.FromContext(ctx)
assumedPod := assumedPodInfo.Pod
// Run "permit" plugins.
// 如果 Pod 处在等待状态,则等待 Pod 被所有的 Permit 插件 allow 或者 reject。否则,阻塞在此
if status := fwk.WaitOnPermit(ctx, assumedPod); !status.IsSuccess() {
if status.IsRejected() {
fitErr := &framework.FitError{
NumAllNodes: 1,
Pod: assumedPodInfo.Pod,
Diagnosis: framework.Diagnosis{
NodeToStatusMap: framework.NodeToStatusMap{scheduleResult.SuggestedHost: status},
UnschedulablePlugins: sets.New(status.Plugin()),
},
}
return framework.NewStatus(status.Code()).WithError(fitErr)
}
return status
}
// Run "prebind" plugins.
// 执行 PreBind 调度扩展点
if status := fwk.RunPreBindPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost); !status.IsSuccess() {
return status
}
// Run "bind" plugins.
// 执行 Bind 调度扩展点
if status := sched.bind(ctx, fwk, assumedPod, scheduleResult.SuggestedHost, state); !status.IsSuccess() {
return status
}
// Calculating nodeResourceString can be heavy. Avoid it if klog verbosity is below 2.
logger.V(2).Info("Successfully bound pod to node", "pod", klog.KObj(assumedPod), "node", scheduleResult.SuggestedHost, "evaluatedNodes", scheduleResult.EvaluatedNodes, "feasibleNodes", scheduleResult.FeasibleNodes)
metrics.PodScheduled(fwk.ProfileName(), metrics.SinceInSeconds(start))
metrics.PodSchedulingAttempts.Observe(float64(assumedPodInfo.Attempts))
if assumedPodInfo.InitialAttemptTimestamp != nil {
metrics.PodSchedulingDuration.WithLabelValues(getAttemptsLabel(assumedPodInfo)).Observe(metrics.SinceInSeconds(*assumedPodInfo. InitialAttemptTimestamp))
metrics.PodSchedulingSLIDuration.WithLabelValues(getAttemptsLabel(assumedPodInfo)).Observe(metrics.SinceInSeconds(*assumedPodInfo. InitialAttemptTimestamp))
}
// Run "postbind" plugins.
// 执行 PostBind 调度扩展点
fwk.RunPostBindPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost)
// At the end of a successful binding cycle, move up Pods if needed.
if len(podsToActivate.Map) != 0 {
sched.SchedulingQueue.Activate(logger, podsToActivate.Map)
// Unlike the logic in schedulingCycle(), we don't bother deleting the entries
// as `podsToActivate.Map` is no longer consumed.
}
return nil
}其他参考: