k8s 架构拓扑
这篇文章将从K8S的架构、存储、网络及服务暴露等几个方面介绍,记录K8S的学习过程。
讨论议题:
- k8s 架构
- k8s 存储架构
- k8s 容器网络
- k8s 服务暴露
准备环境
K8S 集群搭建方式参考, ubuntu20.04 部署 Kubernetes (k8s)
搭建教程当时基于的环境 1.18 ,参考时注意更改到最新的对应版本。
- 集群主机(vmware 虚拟机)
- vm-ks0 (master): 172.16.101.135
- vm-ks1 (node1): 172.16.101.136
- 系统版本: ubuntu 20.04 TLS
- kubernetes版本: v1.22.0
k8s 初始化 ClusterConfiguration yaml
kubeadm init --config=http://s1.kiosk007.top/static/kubeadm-config.yaml --upload-certs -v 6网络插件:flannel
kubectl apply -f http://s1.kiosk007.top/static/kube-flannel.yaml去掉master节点的调度taint
去掉NoSchedule使master节点可以调度pod。
kubectl taint nodes vm-ks0 node-role.kubernetes.io/master:NoSchedule-宿主机安装NFS
NFS 提供远程存储服务,并提供PV,NFS的安装工作参考 这里
# 安装
sudo apt install nfs-kernel-server
# 准备磁盘目录
mkdir -p /data/nfs/
# NFS服务配置文件
sudo vim /etc/exports
/home/weijiaxiang/data/nfs *(rw,no_root_squash,sync)
# 重启NFS,并保持NFS启动开机
systemctl restart nfs-kernel-server
systemctl enable nfs-kernel-server
# 所有Node节点安装NFS客户端
apt install nfs-common rpcbind
# Node 节点上查看能否 mount
showmount -e 172.16.101.1K8S 架构
议题:
- K8S 架构是什么样的
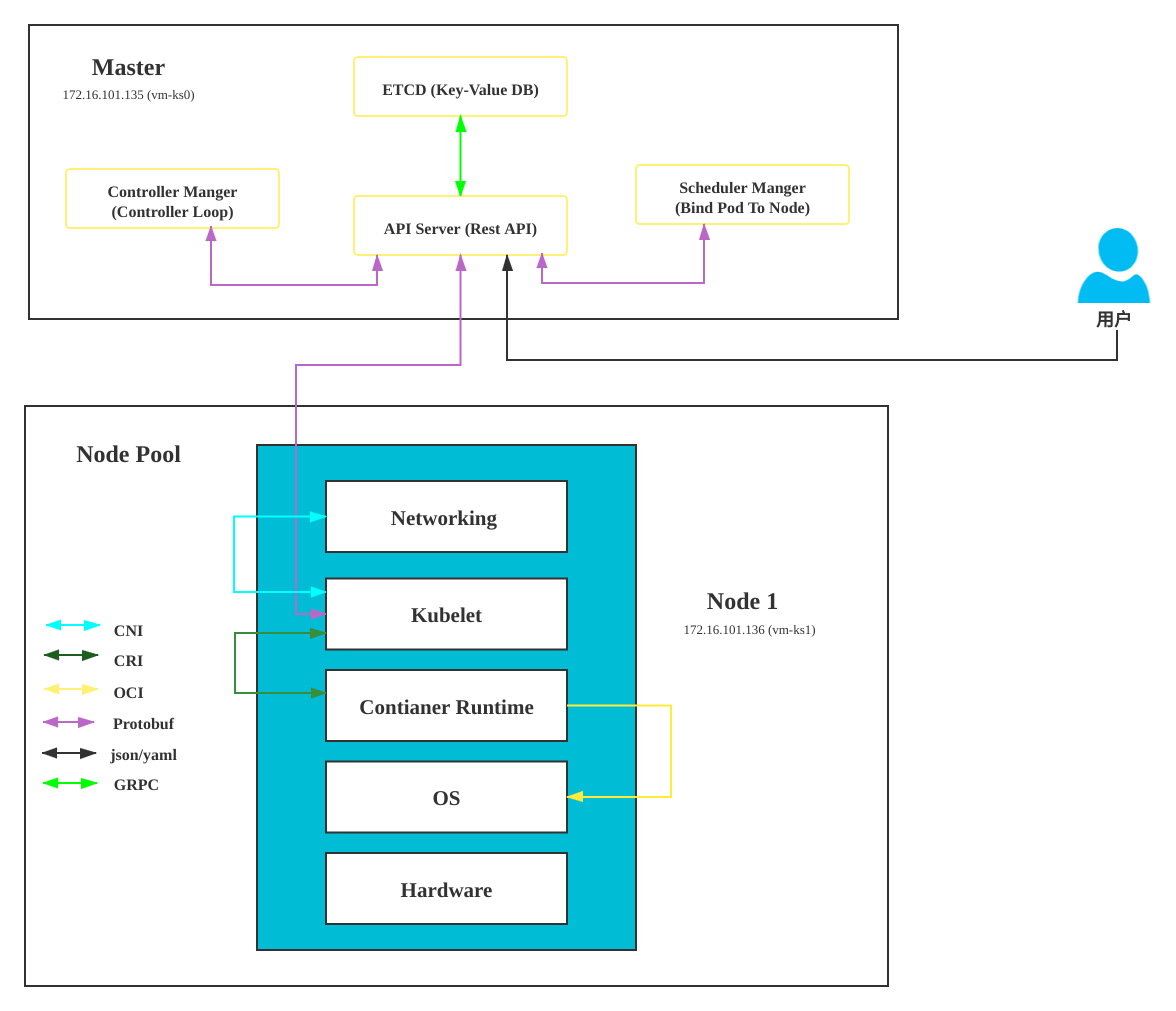
- CNI: 容器网络接口
- CRI:容器运行时接口
- OCI:开放容器标准
容器持久化存储
议题:
- 容器的存储是如何实现的
- k8s集群如何使用存储
PV & PVC
PV (PersistentVolume) 描述的是持久化存储数据卷。这个 API 对象主要定义的是一个持久化存储在宿主机上的目录,比如一个 NFS 的挂载目录。
PVC(PersistentVolumeClaim) 描述的是 Pod 所希望使用的持久化存储的属性。比如,Volume 存储的大小、可读写权限等等。
一般PV由运维人员创建并提供,PVC是由开发人员所创建,以 PVC 模板的方式成为 StatefulSet 的一部分,然后由 StatefulSet 控制器负责创建带编号的 PVC。PV 和 PVC 的 storageClassName 字段必须一样,才能使用
如一个 NFS 的 PV
# nfs-pv001.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv001
labels:
pv: nfs-pv001
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs
nfs:
path: /data/nfs/pv001
server: 172.16.101.1声明一个 1 GiB 大小的 PVC
# nfs-pvc001.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc001
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: nfs
selector:
matchLabels:
pv: nfs-pv001接下来就可以像 hostPath 等常规类型的 Volume 一样,在自己的 YAML 文件里声明使用。
更多例子参考 这里
大多数情况下,持久化 Volume 的实现,往往依赖于一个远程存储服务,比如:远程文件存储(比如,NFS、GlusterFS)、远程块存储(比如,公有云提供的远程磁盘)等等。
实际生产环境中,一个大规模的 Kubernetes 集群里很可能有成千上万个 PVC,这就意味着运维人员必须得事先创建出成千上万个 PV。更麻烦的是,随着新的 PVC 不断被提交,运维人员就不得不继续添加新的、能满足条件的 PV。 为了自动化的创建PV,提出了一个 StorageClass 的概念。
而 StorageClass 对象的作用,其实就是创建 PV 的模板。 具体地说,StorageClass 对象会定义如下两个部分内容:
- 第一,PV 的属性。比如,存储类型、Volume 的大小等等。
- 第二,创建这种 PV 需要用到的存储插件。比如,Ceph 等等。
有了这样两个信息之后,Kubernetes 就能够根据用户提交的 PVC,找到一个对应的 StorageClass 了。然后,Kubernetes 就会调用该 StorageClass 声明的存储插件,创建出需要的 PV。
如开源项目 rook。定义的还是一个名叫 block-service 的 StorageClass。(Rook & Ceph 简介)
apiVersion: ceph.rook.io/v1beta1
kind: Pool
metadata:
name: replicapool
namespace: rook-ceph
spec:
replicated:
size: 3
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: block-service
provisioner: ceph.rook.io/block
parameters:
pool: replicapool
#The value of "clusterNamespace" MUST be the same as the one in which your rook cluster exist
clusterNamespace: rook-ceph作为应用开发者,不必再为难运维人员,上面提到的运维人员创建的PV是运维手工分配的,而 Storage Class 是动态创建的。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim1
spec:
accessModes:
- ReadWriteOnce
storageClassName: block-service
resources:
requests:
storage: 30Gi动态 NFS Provision
- 什么是 NFS-Subdir-External-Provisioner
存储组件 NFS subdir external provisioner 是一个存储资源自动调配器,它可用将现有的 NFS 服务器通过持久卷声明来支持 Kubernetes 持久卷的动态分配。自动新建的文件夹将被命名为 ${namespace}-${pvcName}-${pvName} ,由三个资源名称拼合而成。
此组件是对 nfs-client-provisioner 的扩展,nfs-client-provisioner 已经不提供更新,且 nfs-client-provisioner 的 Github 仓库已经迁移到 NFS-Subdir-External-Provisioner 的仓库。
部署需要先将这个项目 clone 下来。
git clone https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner项目的deployment目录下有我们需要的搭建 yaml 文件。
- 创建 ServiceAccount
现在的 Kubernetes 集群大部分是基于 RBAC 的权限控制,所以我们需要创建一个拥有一定权限的 ServiceAccount 与后面要部署的 NFS Subdir Externa Provisioner 组件绑定。
执行 kubectl 命令将 RBAC 文件部署到 Kubernetes 集群
$ kubectl apply -f rbac.yaml- 部署 NFS-Subdir-External-Provisioner
设置 NFS-Subdir-External-Provisioner 部署文件。需要对 deployment.yaml 做一些修改。NFS_SERVER 和 NFS_PATH 都需要改成自己的NFS服务器。另外默认镜像地址为 k8s.gcr.io, 我这里找了网上的一个地址 registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0
$ kubectl apply -f deployment.yaml- 创建 NFS SotageClass
我们在创建 PVC 时经常需要指定 storageClassName 名称,这个参数配置的就是一个 StorageClass 资源名称,PVC 通过指定该参数来选择使用哪个 StorageClass,并与其关联的 Provisioner 组件来动态创建 PV 资源。所以,这里我们需要提前创建一个 Storagelcass 资源。
Provisioner 参数用于声明 NFS 动态卷提供者的名称,该参数值要和上面部署 NFS-Subdir-External-Provisioner 部署文件中指定的 PROVISIONER_NAME 参数保持一致,即设置为 nfs-storage。
- 测试
创建一个用于测试的 pvc。并创建一个 pod 使用pvc写文件
$ kubectl apply -f test-claim.yaml
$ kubectl apply -f test-pods.yaml在宿主机的 nfs 共享目录上发现,已经创建出 SUCCESS 文件。
容器网络
议题:
- 同一台主机的容器既然被隔离,是怎样互相通信的
- 为什么跨主机的容器可以互相通信
- 容器间的网络通信和主机间的网络通信性能相差
- k8s的CNI网络实现
- K8S网络方案L2和L3的区别
- 网络隔离方案
实验环境,起 2个 pod
flannel 网络通信方式
| 通信方式 | 概念 | 方式 |
|---|---|---|
| 主机内通信 | 1台机器内部的 | veth pair |
| L2 主机间通信 | 2台主机连在同一台交换机的场景 | hostgw |
| L3 主机间通信 | 2台主机没有连在同一台交换机的场景。 | 内核态:vxlan 用户态:udp (性能差) |
主机内POD通信 (cni0 与 veth pair)
- node:
vm-ks1:172.16.101.136/16- pod0:
web-0:10.100.1.39 eth0@if6 0a:ff:9f:1b:5c:02 - pod1:
web-1:10.100.1.40 eth0@if7 16:60:24:3d:0f:84
- pod0:
宿主机 vm-ks1 上的网卡, 除了 flannel和cni0 网卡外,还有一堆veth开头的网卡,每创建一个容器或pod都会在宿主机上生成一个 veth pair,这个veth pair可以理解为容器和宿主机之间拉了一条网线。可参考这篇文章
root@vm-ks1:~# ip link show
root@vm-ks1:~# ip link show | egrep "veth" | awk -F":" '{print $1":"$2}'
6: veth50ce0fb7@if3
7: veth51f9d367@if3
8: veth8b0a5941@if3
9: veth940d7fa4@if3
10: veth12a5546b@if3
11: veth1b7e020f@if3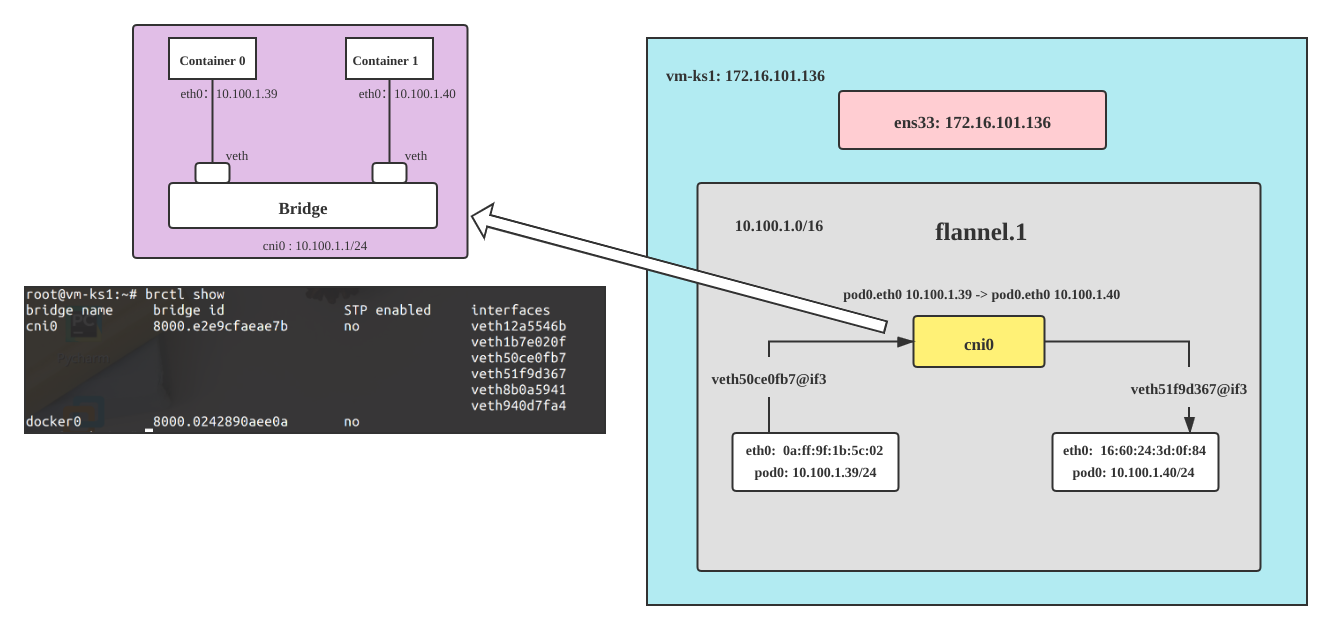
同一主机内的pod之间的互相通信流量会经过 cni0,可以看到 pod0 的Mac地址0a:ff:9f:1b:5c:02 可以直接访问 pod1 的Mac地址 16:60:24:3d:0f:84
。
root@vm-ks1:~# tcpdump -i cni0 port 80 -XXe -v
tcpdump: listening on cni0, link-type EN10MB (Ethernet), capture size 262144 bytes
23:42:29.370870 0a:ff:9f:1b:5c:02 (oui Unknown) > 16:60:24:3d:0f:84 (oui Unknown), ethertype IPv4 (0x0800), length 74: (tos 0x0, ttl 64, id 16685, offset 0, flags [DF], proto TCP (6), length 60)
10.100.1.39.52402 > 10.100.1.40.http: Flags [S], cksum 0x1745 (incorrect -> 0x9d01), seq 2993213598, win 64860, options [mss 1410,sackOK,TS val 2243936499 ecr 0,nop,wscale 7], length 0
0x0000: 1660 243d 0f84 0aff 9f1b 5c02 0800 4500 .`$=......\...E.
0x0010: 003c 412d 4000 4006 e278 0a64 0127 0a64 .<A-@.@..x.d.'.d
0x0020: 0128 ccb2 0050 b268 d09e 0000 0000 a002 .(...P.h........
0x0030: fd5c 1745 0000 0204 0582 0402 080a 85bf .\.E............
0x0040: c0f3 0000 0000 0103 0307 ..........从宿主机的 arp 命令可知 cni0 上的路由表是既有 pod0 的mac地址+ip地址,也有pod1的。
root@vm-ks1:~# arp -v
Address HWtype HWaddress Flags Mask Iface
10.100.0.0 ether da:e9:f6:2d:73:b5 CM flannel.1
10.100.1.41 ether 5e:82:a8:f9:ab:92 C cni0
10.100.1.40 ether 16:60:24:3d:0f:84 C cni0
10.100.1.42 ether ae:85:38:14:2e:3f C cni0
10.100.1.44 ether 56:0c:75:ed:ca:cb C cni0
_gateway ether 00:50:56:e3:07:3f C ens33
172.16.101.1 ether 00:50:56:c0:00:08 C ens33
vm-ks0 ether 00:0c:29:ee:ae:5f C ens33
10.100.1.39 ether 0a:ff:9f:1b:5c:02 C cni0k8s 跨主机ip通信
跨主机间通信分2种,hostgw: eht0 vxlan: flannel0。我们在初始化k8s 集群时使用的是 flannel的网络cni插件。flannel通过给每台宿主机分配一个子网的方式为容器提供虚拟网络,它基于Linux TUN/TAP,使用UDP封装IP包来创建overlay网络,并借助etcd维护网络的分配情况。
udp:使用用户态udp封装,默认使用8285端口。由于是在用户态封装和解包,性能上有较大的损失 vxlan:vxlan封装,需要配置VNI,Port(默认8472)和GBP host-gw:直接路由的方式,将容器网络的路由信息直接更新到主机的路由表中,仅适用于二层直接可达的网络
node:
vm-ks1:172.16.101.136/16- pod0:
web-0:10.100.1.39 eth0@if6 0a:ff:9f:1b:5c:02 - flannel.1:
10.100.0.0 da:e9:f6:2d:73:b5
- pod0:
node:
vm-ks0:172.16.101.135/16- pod2:
web-2:10.100.0.22 eth0@if8 66:14:4c:b9:74:13 - flannel.1:
10.100.1.0 fe:ca:1a:3e:42:41
- pod2:
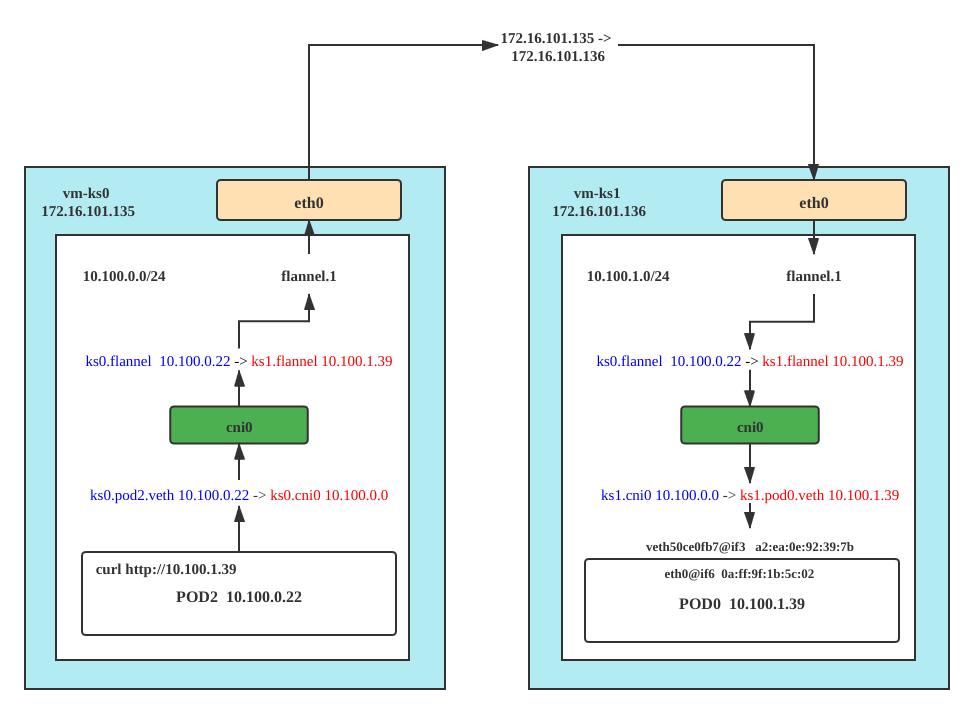
vm-ks0 的 flannel 设备收到“原始 IP 包”后,就要想办法把“原始 IP 包”加上一个目的 MAC 地址,封装成一个二层数据帧,然后发送给“目的 flannel” 设备。vm-ks0 和 vm-ks1 上的 flannel 设备组成了一个虚拟的2层网络,即:通过二层数据帧进行通信。
root@vm-ks0:~# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.100.0.0 netmask 255.255.255.255 broadcast 10.100.0.0
inet6 fe80::d8e9:f6ff:fe2d:73b5 prefixlen 64 scopeid 0x20<link>
ether da:e9:f6:2d:73:b5 txqueuelen 0 (Ethernet)
RX packets 4387 bytes 777102 (777.1 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8578 bytes 1684583 (1.6 MB)
TX errors 19 dropped 49 overruns 0 carrier 19 collisions 0
root@vm-ks0:~# ip neigh show dev flannel.1
10.100.1.0 lladdr fe:ca:1a:3e:42:41 PERMANENT在vm-ks0上执行 ip neigh show dev flannel.1
这条记录的意思非常明确,即:IP 地址 10.100.1.0,对应的 MAC 地址是 fe:ca:1a:3e:42:41。
一个 flannel.1 设备只知道另一端的 flannel.1 设备的 MAC 地址,却不知道对应的宿主机地址是什么。
也就是说,这个 UDP 包该发给哪台宿主机呢?
在这种场景下,flannel.1 设备实际上要扮演一个“网桥”的角色,在二层网络进行 UDP 包的转发。而在 Linux 内核里面,“网桥”设备进行转发的依据,来自于一个叫作 FDB(Forwarding Database)的转发数据库。
这个 flannel.1“网桥”对应的 FDB 信息,也是 flanneld 进程负责维护的。它的内容可以通过 bridge fdb 命令查看到,如下所示
root@vm-ks0:~# bridge fdb show flannel.1 | grep fe:ca:1a:3e:42:41
fe:ca:1a:3e:42:41 dev flannel.1 dst 172.16.101.136 self permanent这下整个转发过程就清楚了,参考下图的封装过程。

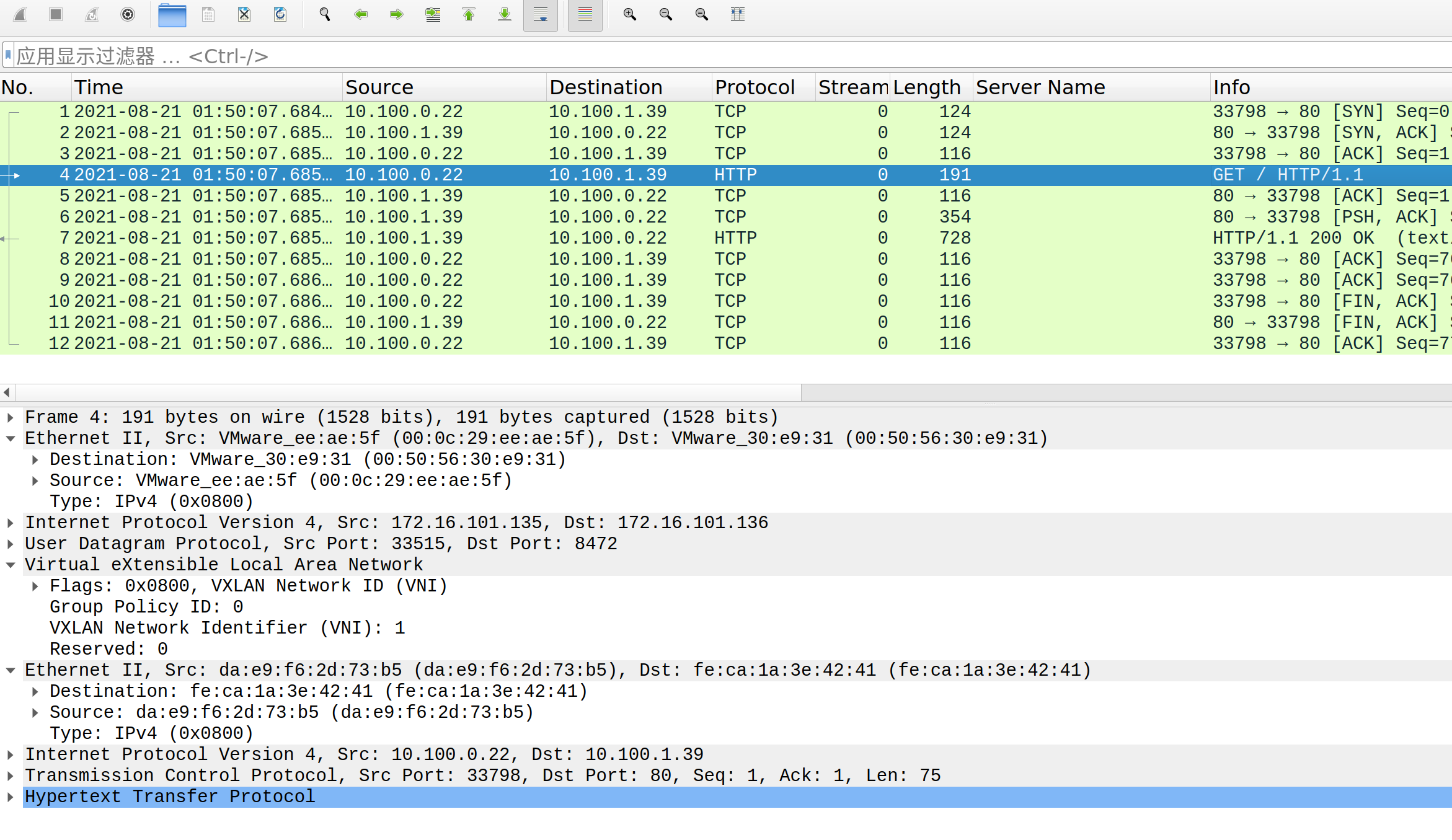
从上面的 wireshark 抓包可以看到,跨主机访问的报文是UDP的VXLAN协议,使用 8472 端口。 VXLAN 上的二层Mac地址分别是两台node节点的flannel网卡的Mac地址。 再向上就如同pod0 和 pod2 直接通信的效果了。
3 层主机之间的通信UDP模式已经废弃。 我们在进行系统级编程的时候,有一个非常重要的优化原则,就是要减少用户态到内核态的切换次数,并且把核心的处理逻辑都放在内核态进行。这也是为什么,Flannel 后来支持的VXLAN 模式,逐渐成为了主流的容器网络方案的原因。
CNI 插件的部署和实现
我们在部署 Kubernetes 的时候,有一个步骤是安装 kubernetes-cni 包,它的目的就是在宿主机上安装 CNI 插件所需的基础可执行文件。
在安装完成后,你可以在宿主机的 /opt/cni/bin 目录下看到它们,如下所示:
root@vm-ks0:~# ls -al /opt/cni/bin/
total 70504
drwxrwxr-x 2 root root 4096 Aug 15 10:07 .
drwxr-xr-x 3 root root 4096 Aug 15 10:07 ..
-rwxr-xr-x 1 root root 4159518 May 14 2020 bandwidth
-rwxr-xr-x 1 root root 4671647 May 14 2020 bridge
-rwxr-xr-x 1 root root 12124326 May 14 2020 dhcp
-rwxr-xr-x 1 root root 5945760 May 14 2020 firewall
-rwxr-xr-x 1 root root 3069556 May 14 2020 flannel
-rwxr-xr-x 1 root root 4174394 May 14 2020 host-device
-rwxr-xr-x 1 root root 3614480 May 14 2020 host-local
-rwxr-xr-x 1 root root 4314598 May 14 2020 ipvlan
-rwxr-xr-x 1 root root 3209463 May 14 2020 loopback
-rwxr-xr-x 1 root root 4389622 May 14 2020 macvlan
-rwxr-xr-x 1 root root 3939867 May 14 2020 portmap
-rwxr-xr-x 1 root root 4590277 May 14 2020 ptp
-rwxr-xr-x 1 root root 3392826 May 14 2020 sbr
-rwxr-xr-x 1 root root 2885430 May 14 2020 static
-rwxr-xr-x 1 root root 3356587 May 14 2020 tuning
-rwxr-xr-x 1 root root 4314446 May 14 2020 vlan这些 CNI 的基础可执行文件,按照功能可以分为三类:
- 第一类,叫作 Main 插件,它是用来创建具体网络设备的二进制文件。比如,bridge(网桥设备)、ipvlan、loopback(lo 设备)、macvlan、ptp(Veth Pair 设备),以及 vlan。我在前面提到过的 Flannel、Weave 等项目,都属于“网桥”类型的 CNI 插件。所以在具体的实现中,它们往往会调用 bridge 这个二进制文件。
- 第二类,叫作 IPAM(IP Address Management)插件,它是负责分配 IP 地址的二进制文件。比如,dhcp,这个文件会向 DHCP 服务器发起请求;host-local,则会使用预先配置的 IP 地址段来进行分配。
- 第三类,是由 CNI 社区维护的内置 CNI 插件。比如:flannel,就是专门为 Flannel 项目提供的 CNI 插件;tuning,是一个通过 sysctl 调整网络设备参数的二进制文件;portmap,是一个通过 iptables 配置端口映射的二进制文件;bandwidth,是一个使用 Token Bucket Filter (TBF) 来进行限流的二进制文件。
首先,实现这个网络方案本身。这一部分需要编写的,其实就是 flanneld 进程里的主要逻辑。比如,创建和配置 flannel.1 设备、配置宿主机路由、配置 ARP 和 FDB 表里的信息等等。
然后,实现该网络方案对应的 CNI 插件。这一部分主要需要做的,就是配置 Infra 容器里面的网络栈,并把它连接在 CNI 网桥上。
其启动和配置原理如下,首先,CNI bridge 插件会在宿主机上检查 CNI 网桥是否存在。如果没有的话,那就创建它。这相当于在宿主机上执行:
# 在宿主机上
$ ip link add cni0 type bridge
$ ip link set cni0 up接下来,CNI bridge 插件会通过 Infra 容器的 Network Namespace 文件,进入到这个 Network Namespace 里面,然后创建一对 Veth Pair 设备。
#在容器里
# 创建一对Veth Pair设备。其中一个叫作eth0,另一个叫作vethb4963f3
$ ip link add eth0 type veth peer name vethb4963f3
# 启动eth0设备
$ ip link set eth0 up
# 将Veth Pair设备的另一端(也就是vethb4963f3设备)放到宿主机(也就是Host Namespace)里
$ ip link set vethb4963f3 netns $HOST_NS
# 通过Host Namespace,启动宿主机上的vethb4963f3设备
$ ip netns exec $HOST_NS ip link set vethb4963f3 up这样,vethb4963f3 就出现在了宿主机上,而且这个 Veth Pair 设备的另一端,就是容器里面的 eth0。(在宿主机上操作也可以,原理都一样)
接下来,CNI bridge 插件就可以把 vethb4963f3 设备连接在 CNI 网桥上
# 在宿主机上
$ ip link set vethb4963f3 master cni0所有容器都可以直接使用 IP 地址与其他容器通信,而无需使用 NAT。
容器自己“看到”的自己的 IP 地址,和别人(宿主机或者容器)看到的地址是完全一样的。
三层网络方案
除了网桥类型的 Flannel 插件,还有一种纯三层(Pure Layer 3)网络方案,典型例子包括 Flannel 的 host-gw 模式和 Calico 项目。
当你设置 Flannel 使用 host-gw 模式之后,flanneld 会在宿主机上创建这样一条规则,以 vm-ks0 为例:
$ ip route
...
10.100.1.0/24 via 172.16.101.136 dev eth0这条路由规则的含义是:目的 IP 地址属于 10.100.1.0/24 网段的 IP 包,应该经过本机的 eth0 设备发出去(即:dev eth0);并且,它下一跳地址(next-hop)是 172.16.101.136(即:via 172.16.101.136)。
host-gw 模式的工作原理,其实就是将每个 Flannel 子网(Flannel Subnet,比如:10.100.1.0/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址。
也就是说,这台“主机”(Host)会充当这条容器通信路径里的“网关”(Gateway)。这也正是“host-gw”的含义。所以说,Flannel host-gw 模式必须要求集群宿主机之间是二层连通的。
不同于 Flannel 通过 Etcd 和宿主机上的 flanneld 来维护路由信息的做法,Calico 项目使用了一个BGP(Border Gateway Protocol,即:边界网关协议) 来自动地在整个集群中分发路由信息。
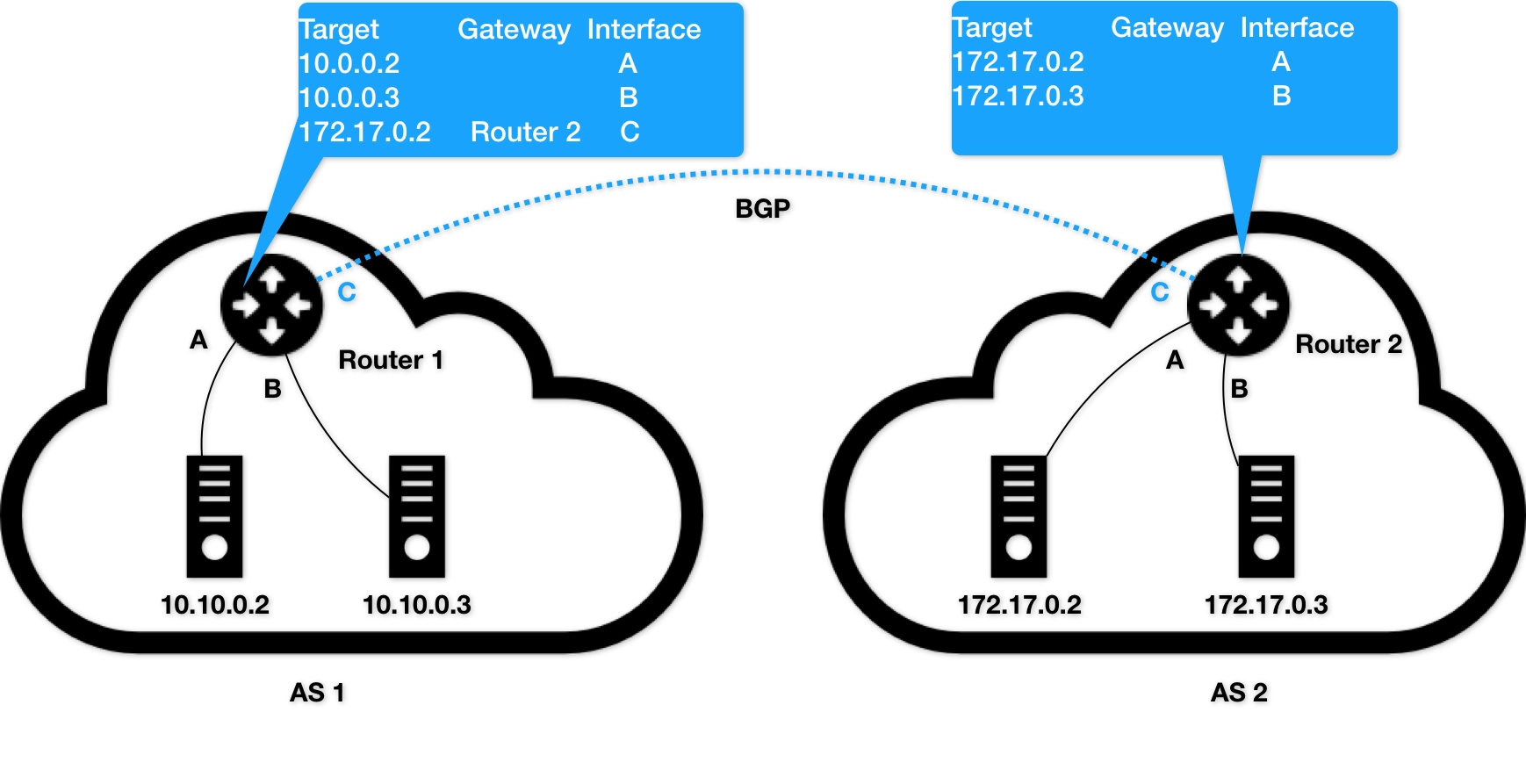
比如上述,有2个自治系统(Autonomous System,简称为 AS):AS 1 和 AS 2。在正常情况下,自治系统之间不会有任何“来往”。
比如,AS 1 里面的主机 10.10.0.2,要访问 AS 2 里面的主机 172.17.0.3 的话。它发出的 IP 包,就会先到达自治系统 AS 1 上的路由器 Router 1。
而在此时,Router 1 的路由表里,有这样一条规则,即:目的地址是 172.17.0.2 包,应该经过 Router 1 的 C 接口,发往网关 Router 2(即:自治系统 AS 2 上的路由器)。至此Router 2 就会把数据包交付到真正的目的主机上。
我们就把它形象地称为:边界网关。它跟普通路由器的不同之处在于,它的路由表里拥有其他自治系统里的主机路由信息。
而 BGP 的这个能力,正好可以取代 Flannel 维护主机上路由表的功能。而且,BGP 这种原生就是为大规模网络环境而实现的协议,其可靠性和可扩展性,远非 Flannel 自己的方案可比。
- 三层网络和二层隧道的区别
- 三层和隧道的异同: 相同之处是都实现了跨主机容器的三层互通,而且都是通过对目的 MAC 地址的操作来实现的;不同之处是三层通过配置下一条主机的路由规则来实现互通,隧道则是通过通过在 IP 包外再封装一层 MAC 包头来实现。
- 三层的优点:少了封包和解包的过程,性能肯定是更高的。
- 三层的缺点:需要自己想办法维护路由规则。
- 隧道的优点:简单,原因是大部分工作都是由 Linux 内核的模块实现了,应用层面工作量较少。
- 隧道的缺点:主要的问题就是性能低。
根据实际的测试,host-gw 的性能损失大约在 10% 左右,而其他所有基于 VXLAN“隧道”机制的网络方案,性能损失都在 20%~30% 左右。
网络隔离
在 Kubernetes 里,网络隔离能力的定义,是依靠一种专门的 API 对象来描述的,即:NetworkPolicy。
Kubernetes 里的 Pod 默认都是“允许所有”(Accept All)的,即:Pod 可以接收来自任何发送方的请求;或者,向任何接收方发送请求。而如果你要对这个情况作出限制,就必须通过 NetworkPolicy 对象来指定。
如下例子:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978这个 NetworkPolicy 对象,指定的隔离规则如下所示:
- 该隔离规则只对 default Namespace 下的,携带了 role=db 标签的 Pod 有效。限制的请求类型包括 ingress(流入)和 egress(流出)。
- Kubernetes 会拒绝任何访问被隔离 Pod 的请求,除非这个请求来自于以下“白名单”里的对象,并且访问的是被隔离 Pod 的 6379 端口。这些“白名单”对象包括: a. default Namespace 里的,携带了 role=fronted 标签的 Pod; b. 携带了 project=myproject 标签的 Namespace 里的任何 Pod; c. 任何源地址属于 172.17.0.0/16 网段,且不属于 172.17.1.0/24 网段的请求。
- Kubernetes 会拒绝被隔离 Pod 对外发起任何请求,除非请求的目的地址属于 10.0.0.0/24 网段,并且访问的是该网段地址的 5978 端口。
在 Kubernetes 生态里,目前已经实现了 NetworkPolicy 的网络插件包括 Calico、Weave 和 kube-router 等多个项目,但是并不包括 Flannel 项目。
所以说,如果想要在使用 Flannel 的同时还使用 NetworkPolicy 的话,你就需要再额外安装一个网络插件,比如 Calico 项目,来负责执行 NetworkPolicy。安装方式
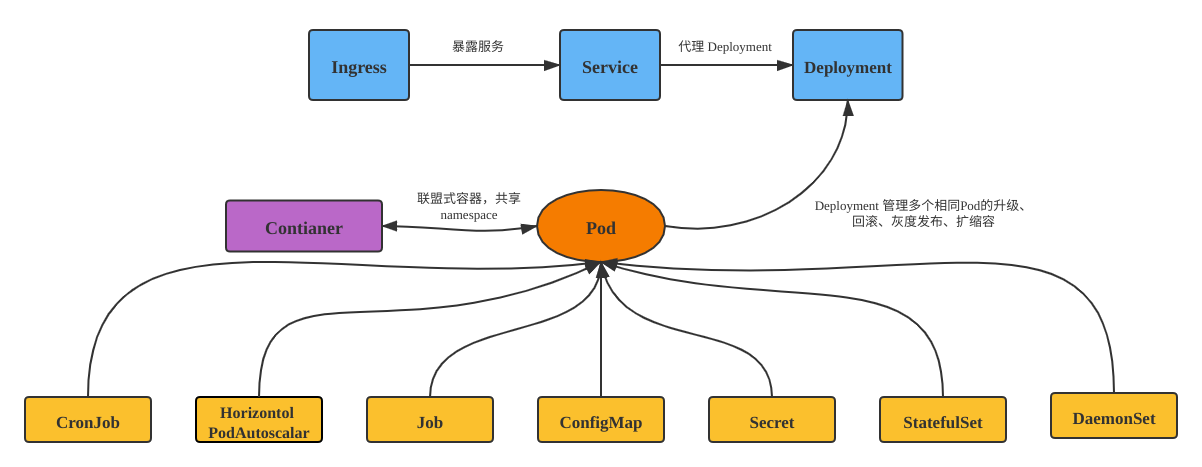
服务暴露
我们知道 deployment 是由一堆 pod 组成的。在我们要访问pod 上的服务时有2个问题需要解决。
- pod 的ip是不固定的,随着调度一直在变
- pod之间需要一种负载均衡的访问
Service
一个最典型的 service 定义如下所示:
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
ports:
- name: default
protocol: TCP
port: 80
targetPort: 80可以看到这个名为 nginx 的service,后面挂载了3个pod。
kubectl describe svc nginx
Name: nginx
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=nginx
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.60.101
IPs: 10.96.60.101
Port: default 80/TCP
TargetPort: 80/TCP
Endpoints: 10.100.1.39:80,10.100.1.40:80,10.100.1.43:80
Session Affinity: None
Events: <none>访问时可以随机负载。
root@vm-ks0:~/k8s/svc# curl 10.96.60.101/hello
hi, web-0
root@vm-ks0:~/k8s/svc# curl 10.96.60.101/hello
hi, web-1
root@vm-ks0:~/k8s/svc# curl 10.96.60.101/hello
hi, web-1
root@vm-ks0:~/k8s/svc# curl 10.96.60.101/hello
hi, web-2
root@vm-ks0:~/k8s/svc# curl 10.96.60.101/hello
hi, web-0实际上,Service 是由 kube-proxy 组件,加上 iptables 来共同实现的。
对于我们前面创建的名叫 nginx 的 Service 来说,一旦它被提交给 Kubernetes,那么 kube-proxy 就可以通过 Service 的 Informer 感知到这样一个 Service 对象的添加。而作为对这个事件的响应,它就会在宿主机上创建这样一条 iptables 规则(你可以通过 iptables-save 看到它),如下所示:
root@vm-ks0:~/k8s/svc# iptables-save | grep "10.96.60.101"
-A KUBE-SERVICES -d 10.96.60.101/32 -p tcp -m comment --comment "default/nginx:default cluster IP" -m tcp --dport 80 -j KUBE-SVC-5JWVWZBQU2R3YJF2
-A KUBE-SVC-5JWVWZBQU2R3YJF2 ! -s 10.100.0.0/16 -d 10.96.60.101/32 -p tcp -m comment --comment "default/nginx:default cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ这条 iptables 规则的含义是:凡是目的地址是 10.96.60.101、目的端口是 80 的 IP 包,都应该跳转到另外一条名叫 KUBE-SVC-5JWVWZBQU2R3YJF2 的 iptables 链进行处理。
那如何做到随机访问,实际上是利用了iptable规则里的random组件里的 --probability 实现的,有33%的概率访问到 web-0, 如果没命中的话,有50%的概率访问到 web-1, 如果还没有命中的话,则必访问到 web-3 。
-A KUBE-SVC-5JWVWZBQU2R3YJF2 -m comment --comment "default/nginx:default" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-WZ2C5AZQZKHYZFZC
-A KUBE-SVC-5JWVWZBQU2R3YJF2 -m comment --comment "default/nginx:default" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-VQLGMKAWCVHQEJD4
-A KUBE-SVC-5JWVWZBQU2R3YJF2 -m comment --comment "default/nginx:default" -j KUBE-SEP-W6K7OWILI2KV46KH不难想到,当你的宿主机上有大量 Pod 的时候,成百上千条 iptables 规则不断地被刷新,会大量占用该宿主机的 CPU 资源,甚至会让宿主机“卡”在这个过程中。所以说,一直以来,基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级的 Pod 的主要障碍。
而 IPVS 模式的 Service,就是解决这个问题的一个行之有效的方法。IPVS 模式的工作原理,其实跟 iptables 模式类似。当我们创建了前面的 Service 之后,kube-proxy 首先会在宿主机上创建一个虚拟网卡(叫作:kube-ipvs0),并为它分配 Service VIP 作为 IP 地址,
所以,在大规模集群里,建议 kube-proxy 设置–proxy-mode=ipvs 来开启这个功能。它为 Kubernetes 集群规模带来的提升,还是非常巨大的。
- DNS 服务发现
在 Kubernetes 中,Service 和 Pod 都会被分配对应的 DNS A 记录(从域名解析 IP 的记录)。
对于 ClusterIP 模式的 Service 来说(比如我们上面的例子),它的 A 记录的格式是:..svc.cluster.local。当你访问这条 A 记录的时候,它解析到的就是该 Service 的 VIP 地址。
root@web-1:/# dig nginx.default.svc.cluster.local +short
10.96.60.101需要注意的是,在 Kubernetes 里,/etc/hosts 文件是单独挂载的,这也是为什么 kubelet 能够对 hostname 进行修改并且 Pod 重建后依然有效的原因。这跟 Docker 的 Init 层是一个原理。