# HTTP/2.0 Header Compression
在 HTTP/1.x 时代,支持Body压缩,Header不支持压缩。而现在一个网页可能有几十到上百个请求,一个请求Header至少 500Byte 以上。而这些页面的请求Header大多都是一些重复的字符如UA、Cookie,会消耗不必要的带宽,增加延迟。
在HTTP/2.0中,引入了Header Compression(rfc7541),头部压缩技术使用了HPACK,有效的压缩了Header。
# 开门见山
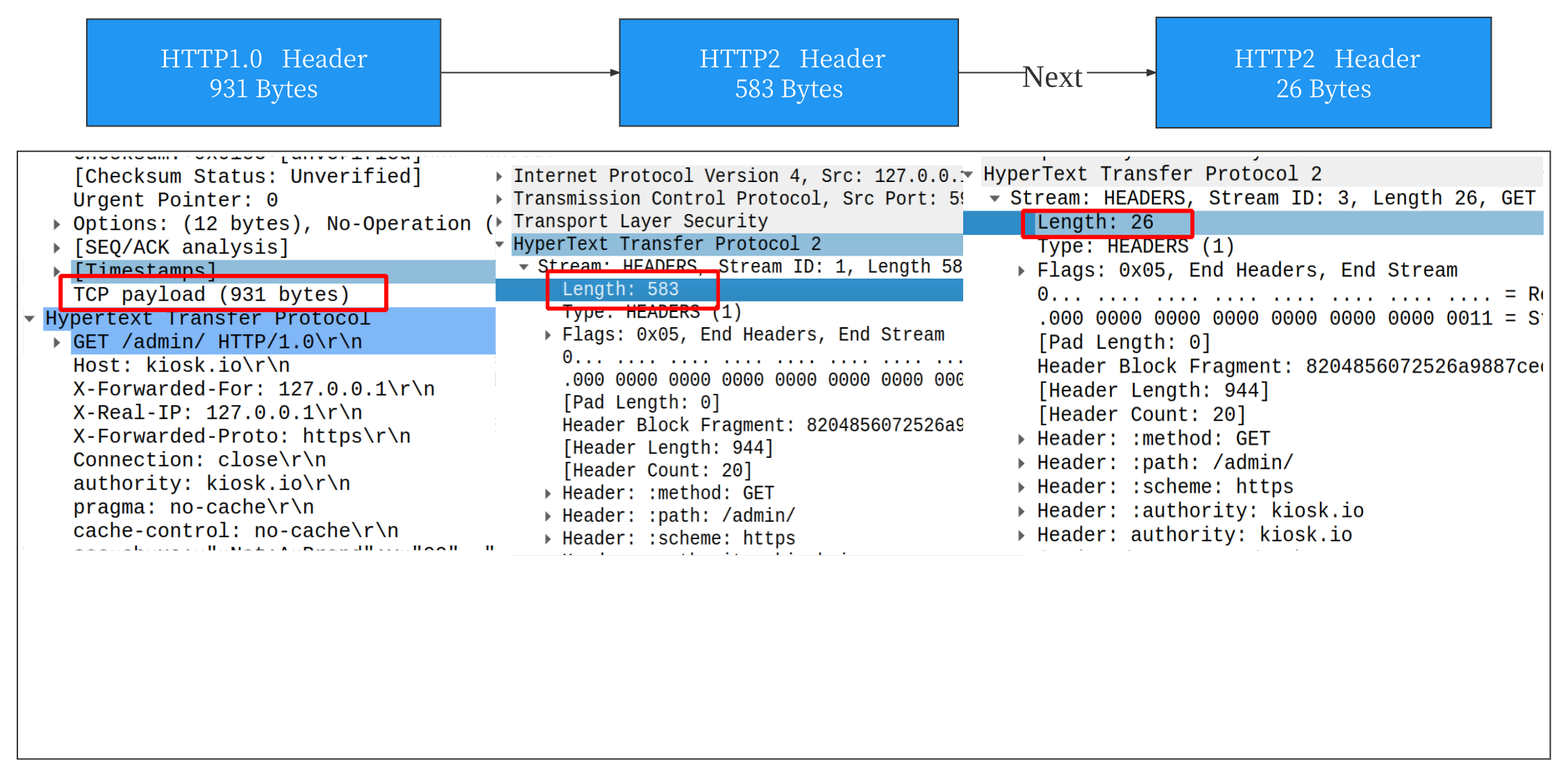
我们先看看压缩效果,我们先来看一下HPACK压缩效果。比如说一个简单的HTTP请求,Header大约是 900 Byte,在 HTTP/2.0 中,首次请求会被压缩到 600 Byte,接着在后续的请求中会被压缩到 120 Byte,首次请求压缩率达到 50% ,后续达到 95% 。可以说效果是非常明显的,如下图( wireshark 抓包 ):
实验:我们使用 curl 命令发起请求观察。先发起一个 http1.1 请求,再连续发起2个 HTTP2 请求对比。
``` bash
export SSLKEYLOGFILE=~/sslkey.log
# 使用http1.1 请求
curl --http1.1 -v 'https://kiosk.io/admin/' \
-H 'authority: kiosk.io' \
-H 'pragma: no-cache' \
-H 'cache-control: no-cache' \
-H 'sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="97", "Chromium";v="97"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Linux"' \
.... 多加一些 Header 可以体现出压缩效率
-H 'cookie: 1234567890qwertyuiopasdfghjklzxcvbnm' -o /dev/null \
# 使用http2 请求
curl --http2 -v 'https://kiosk.io/admin/' \
.... Header 保持和H1一样,这里省略
--next --http2 -v 'https://kiosk.io/admin/' \
.... Header 省略
```
 # 压缩原理
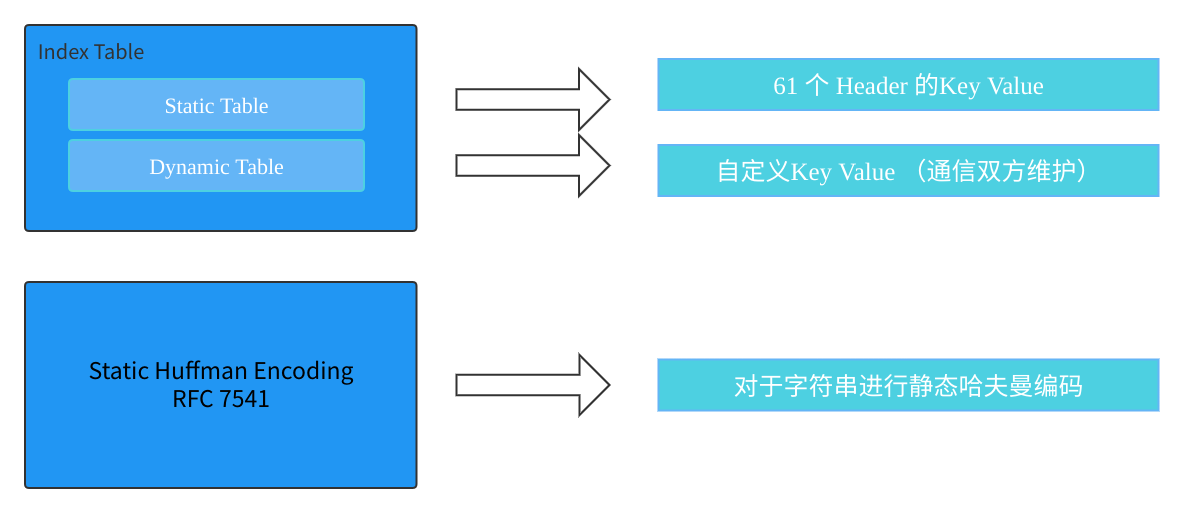
HTTP2 使用 HPACK 压缩格式压缩请求和响应标头元数据,这种格式采用下面两种技术压缩:
- 通过静态哈夫曼代码对传输的标头字段进行编码,从而减小数据传输的大小。
- 单个连接中,client 和 server 共同维护一个相同的标头字段索引列表,此列表在之后的传输中用作编解码的参考。
# 压缩原理
HTTP2 使用 HPACK 压缩格式压缩请求和响应标头元数据,这种格式采用下面两种技术压缩:
- 通过静态哈夫曼代码对传输的标头字段进行编码,从而减小数据传输的大小。
- 单个连接中,client 和 server 共同维护一个相同的标头字段索引列表,此列表在之后的传输中用作编解码的参考。
 下面参考Golang http2/hpack 的实现,详细介绍一下其工作模式。
## Indexs Table
索引表(rfc7541#section-2.3),包含Static Table静态表、Dynamic Table动态表。静态表包含61个预定义的key value,动态表包含自定义的key value。
HPACK使用Static Table、Dynamic Table将Header字段与索引Index相关联,这两个表合并为一个地址空间,用于定义索引值,如下图:
下面参考Golang http2/hpack 的实现,详细介绍一下其工作模式。
## Indexs Table
索引表(rfc7541#section-2.3),包含Static Table静态表、Dynamic Table动态表。静态表包含61个预定义的key value,动态表包含自定义的key value。
HPACK使用Static Table、Dynamic Table将Header字段与索引Index相关联,这两个表合并为一个地址空间,用于定义索引值,如下图:
 认识静/动态索引表需要先认识headerFieldTable结构体,动态表和静态表都是基于它实现的。
``` golang
type headerFieldTable struct {
// As in hpack, unique ids are 1-based. The unique id for ents[k] is k + evictCount + 1.
ents []HeaderField
evictCount uint64
// byName maps a HeaderField name to the unique id of the newest entry with the same name.
byName map[string]uint64
// byNameValue maps a HeaderField name/value pair to the unique id of the newest
byNameValue map[pairNameValue]uint64
}
```
下面将对上述的字段分别进行描述:
- **ents**:entries 的缩写,代表着当前已经索引的 Header 数据。在 headerFieldTable 中,每一个 Header 都有一个唯一的 Id,以ents[k]为例,该唯一 id 的计算方式是k + evictCount + 1。
- **evictCount**:已经从 ents 中删除的条目数。
- **byName**:存储具有相同 Name 的 Header 的唯一 Id,最新 Header 的 Name 会覆盖老的唯一 Id。
- **byNameValue**:以 Header 的 Name 和 Value 为 key 存储对应的唯一 Id。
对字段的含义有所了解后,接下来对 headerFieldTable 几个比较重要的方法进行解析。
- **(t *headerFieldTable) addEntry(f HeaderField)**: 将Header加入到 headerFieldTable 中
``` golang
func (t *headerFieldTable) addEntry(f HeaderField) {
id := uint64(t.len()) + t.evictCount + 1
t.byName[f.Name] = id
t.byNameValue[pairNameValue{f.Name, f.Value}] = id
t.ents = append(t.ents, f)
}
```
计算出 Header 在 headerFieldTable 中的唯一 Id,并将其分别存入byName和byNameValue中。最后,将 Header 存入ents。
- **(t *headerFieldTable) evictOldest**: 将Header从 headerFieldTable 中删除,毕竟索引表是有大小限制的。
``` golang
func (t *headerFieldTable) evictOldest(n int) {
if n > t.len() {
panic(fmt.Sprintf("evictOldest(%v) on table with %v entries", n, t.len()))
}
for k := 0; k < n; k++ {
f := t.ents[k]
id := t.evictCount + uint64(k) + 1
if t.byName[f.Name] == id {
delete(t.byName, f.Name)
}
if p := (pairNameValue{f.Name, f.Value}); t.byNameValue[p] == id {
delete(t.byNameValue, p)
}
}
copy(t.ents, t.ents[n:])
for k := t.len() - n; k < t.len(); k++ {
t.ents[k] = HeaderField{} // so strings can be garbage collected
}
t.ents = t.ents[:t.len()-n]
if t.evictCount+uint64(n) < t.evictCount {
panic("evictCount overflow")
}
t.evictCount += uint64(n)
}
```
第一个 for 循环的下标是从 0 开始的,也就是说删除 Header 时遵循先进先出的原则。删除 Header 的步骤如下:
1. 删除byName和byNameValue的映射。
2. 将第 n 位及其之后的 Header 前移。
3. 将倒数的 n 个 Header 置空,以方便垃圾回收。
4. 改变 ents 的长度。
5. 增加evictCount的数量。
- **(t *headerFieldTable) search(f HeaderField)** 从当前表中搜索指定 Header 并返回在当前表中的 Index(此处的Index和切片中的下标含义是不一样的)
``` golang
func (t *headerFieldTable) search(f HeaderField) (i uint64, nameValueMatch bool) {
if !f.Sensitive {
if id := t.byNameValue[pairNameValue{f.Name, f.Value}]; id != 0 {
return t.idToIndex(id), true
}
}
if id := t.byName[f.Name]; id != 0 {
return t.idToIndex(id), false
}
return 0, false
}
```
1. 如果 Header 的 Name和 Value 均匹配,则返回当前表中的 Index 且nameValueMatch 为 true。
2. 如果仅有 Header 的 Name 匹配,则返回当前表中的 Index 且nameValueMatch为 false。
3. 如果 Header 的 Name 和 Value 均不匹配,则返回 0 且 nameValueMatch为 false。
- **(t *headerFieldTable) idToIndex(id uint64)** 通过当前表中的唯一 Id 计算出当前表对应的 Index
```golang
func (t *headerFieldTable) idToIndex(id uint64) uint64 {
if id <= t.evictCount {
panic(fmt.Sprintf("id (%v) <= evictCount (%v)", id, t.evictCount))
}
k := id - t.evictCount - 1 // convert id to an index t.ents[k]
if t != staticTable {
return uint64(t.len()) - k // dynamic table
}
return k + 1
}
```
1. 静态表:Index从 1 开始,且 Index 为 1 时对应的元素为t.ents[0]。
2. 动态表: Index也从 1 开始,但是 Index 为 1 时对应的元素为t.ents[t.len()-1]。
## Static Table
静态表(rfc7541#section-2.3.1),包含61个预定义Header key-value,传输的时候使用对应的索引Index替换。静态表内容具体的定义可以参考这里 rfc7541#appendix-A。
```
+-------+-----------------------------+---------------+
| Index | Header Name | Header Value |
+-------+-----------------------------+---------------+
| 1 | :authority | |
| 2 | :method | GET |
| 3 | :method | POST |
| 4 | :path | / |
| 5 | :path | /index.html |
| 6 | :scheme | http |
| 7 | :scheme | https |
| 8 | :status | 200 |
| 9 | :status | 204 |
| 10 | :status | 206 |
| 11 | :status | 304 |
| 12 | :status | 400 |
| 13 | :status | 404 |
| 14 | :status | 500 |
| 15 | accept-charset | |
...省略
| 58 | user-agent | |
| 59 | vary | |
| 60 | via | |
| 61 | www-authenticate | |
+-------+-----------------------------+---------------+
```
在golang里的实现如下:
``` golang
var staticTable = newStaticTable()
func newStaticTable() *headerFieldTable {
t := &headerFieldTable{}
t.init()
for _, e := range staticTableEntries[:] {
t.addEntry(e)
}
return t
}
var staticTableEntries = [...]HeaderField{
{Name: ":authority"},
{Name: ":method", Value: "GET"},
{Name: ":method", Value: "POST"},
// 此处省略代码
{Name: "www-authenticate"},
}
```
上面的t.init函数仅做初始化t.byName和t.byNameValue用。
实际传输的过程中如果遇到对应的字符,则直接以index代替。
```
:method GET = 2 = 00000010
:method POST = 3 = 00000011
:path / = 4 = 00000100
:path /index.html = 5 = 00000101
:scheme https = 7 = 00000111
```
## Dynamic Table
动态表( rfc7541#section-2.3.2),是一个FIFO队列,初始是空的,它有以下特点:
解压header的时候按需添加,每次添加的时候,放在队首,移除的时候,从队尾开始。
大小不是无限制的,可以通过SETTING Frame里的SETTINGS_HEADER_TABLE_SIZE设置,默认 256Byte。
动/静态表中内部的 Index 和内部的唯一 Id,而在一次连接中 HPACK 索引列表是由静态表和动态表一起构成
认识静/动态索引表需要先认识headerFieldTable结构体,动态表和静态表都是基于它实现的。
``` golang
type headerFieldTable struct {
// As in hpack, unique ids are 1-based. The unique id for ents[k] is k + evictCount + 1.
ents []HeaderField
evictCount uint64
// byName maps a HeaderField name to the unique id of the newest entry with the same name.
byName map[string]uint64
// byNameValue maps a HeaderField name/value pair to the unique id of the newest
byNameValue map[pairNameValue]uint64
}
```
下面将对上述的字段分别进行描述:
- **ents**:entries 的缩写,代表着当前已经索引的 Header 数据。在 headerFieldTable 中,每一个 Header 都有一个唯一的 Id,以ents[k]为例,该唯一 id 的计算方式是k + evictCount + 1。
- **evictCount**:已经从 ents 中删除的条目数。
- **byName**:存储具有相同 Name 的 Header 的唯一 Id,最新 Header 的 Name 会覆盖老的唯一 Id。
- **byNameValue**:以 Header 的 Name 和 Value 为 key 存储对应的唯一 Id。
对字段的含义有所了解后,接下来对 headerFieldTable 几个比较重要的方法进行解析。
- **(t *headerFieldTable) addEntry(f HeaderField)**: 将Header加入到 headerFieldTable 中
``` golang
func (t *headerFieldTable) addEntry(f HeaderField) {
id := uint64(t.len()) + t.evictCount + 1
t.byName[f.Name] = id
t.byNameValue[pairNameValue{f.Name, f.Value}] = id
t.ents = append(t.ents, f)
}
```
计算出 Header 在 headerFieldTable 中的唯一 Id,并将其分别存入byName和byNameValue中。最后,将 Header 存入ents。
- **(t *headerFieldTable) evictOldest**: 将Header从 headerFieldTable 中删除,毕竟索引表是有大小限制的。
``` golang
func (t *headerFieldTable) evictOldest(n int) {
if n > t.len() {
panic(fmt.Sprintf("evictOldest(%v) on table with %v entries", n, t.len()))
}
for k := 0; k < n; k++ {
f := t.ents[k]
id := t.evictCount + uint64(k) + 1
if t.byName[f.Name] == id {
delete(t.byName, f.Name)
}
if p := (pairNameValue{f.Name, f.Value}); t.byNameValue[p] == id {
delete(t.byNameValue, p)
}
}
copy(t.ents, t.ents[n:])
for k := t.len() - n; k < t.len(); k++ {
t.ents[k] = HeaderField{} // so strings can be garbage collected
}
t.ents = t.ents[:t.len()-n]
if t.evictCount+uint64(n) < t.evictCount {
panic("evictCount overflow")
}
t.evictCount += uint64(n)
}
```
第一个 for 循环的下标是从 0 开始的,也就是说删除 Header 时遵循先进先出的原则。删除 Header 的步骤如下:
1. 删除byName和byNameValue的映射。
2. 将第 n 位及其之后的 Header 前移。
3. 将倒数的 n 个 Header 置空,以方便垃圾回收。
4. 改变 ents 的长度。
5. 增加evictCount的数量。
- **(t *headerFieldTable) search(f HeaderField)** 从当前表中搜索指定 Header 并返回在当前表中的 Index(此处的Index和切片中的下标含义是不一样的)
``` golang
func (t *headerFieldTable) search(f HeaderField) (i uint64, nameValueMatch bool) {
if !f.Sensitive {
if id := t.byNameValue[pairNameValue{f.Name, f.Value}]; id != 0 {
return t.idToIndex(id), true
}
}
if id := t.byName[f.Name]; id != 0 {
return t.idToIndex(id), false
}
return 0, false
}
```
1. 如果 Header 的 Name和 Value 均匹配,则返回当前表中的 Index 且nameValueMatch 为 true。
2. 如果仅有 Header 的 Name 匹配,则返回当前表中的 Index 且nameValueMatch为 false。
3. 如果 Header 的 Name 和 Value 均不匹配,则返回 0 且 nameValueMatch为 false。
- **(t *headerFieldTable) idToIndex(id uint64)** 通过当前表中的唯一 Id 计算出当前表对应的 Index
```golang
func (t *headerFieldTable) idToIndex(id uint64) uint64 {
if id <= t.evictCount {
panic(fmt.Sprintf("id (%v) <= evictCount (%v)", id, t.evictCount))
}
k := id - t.evictCount - 1 // convert id to an index t.ents[k]
if t != staticTable {
return uint64(t.len()) - k // dynamic table
}
return k + 1
}
```
1. 静态表:Index从 1 开始,且 Index 为 1 时对应的元素为t.ents[0]。
2. 动态表: Index也从 1 开始,但是 Index 为 1 时对应的元素为t.ents[t.len()-1]。
## Static Table
静态表(rfc7541#section-2.3.1),包含61个预定义Header key-value,传输的时候使用对应的索引Index替换。静态表内容具体的定义可以参考这里 rfc7541#appendix-A。
```
+-------+-----------------------------+---------------+
| Index | Header Name | Header Value |
+-------+-----------------------------+---------------+
| 1 | :authority | |
| 2 | :method | GET |
| 3 | :method | POST |
| 4 | :path | / |
| 5 | :path | /index.html |
| 6 | :scheme | http |
| 7 | :scheme | https |
| 8 | :status | 200 |
| 9 | :status | 204 |
| 10 | :status | 206 |
| 11 | :status | 304 |
| 12 | :status | 400 |
| 13 | :status | 404 |
| 14 | :status | 500 |
| 15 | accept-charset | |
...省略
| 58 | user-agent | |
| 59 | vary | |
| 60 | via | |
| 61 | www-authenticate | |
+-------+-----------------------------+---------------+
```
在golang里的实现如下:
``` golang
var staticTable = newStaticTable()
func newStaticTable() *headerFieldTable {
t := &headerFieldTable{}
t.init()
for _, e := range staticTableEntries[:] {
t.addEntry(e)
}
return t
}
var staticTableEntries = [...]HeaderField{
{Name: ":authority"},
{Name: ":method", Value: "GET"},
{Name: ":method", Value: "POST"},
// 此处省略代码
{Name: "www-authenticate"},
}
```
上面的t.init函数仅做初始化t.byName和t.byNameValue用。
实际传输的过程中如果遇到对应的字符,则直接以index代替。
```
:method GET = 2 = 00000010
:method POST = 3 = 00000011
:path / = 4 = 00000100
:path /index.html = 5 = 00000101
:scheme https = 7 = 00000111
```
## Dynamic Table
动态表( rfc7541#section-2.3.2),是一个FIFO队列,初始是空的,它有以下特点:
解压header的时候按需添加,每次添加的时候,放在队首,移除的时候,从队尾开始。
大小不是无限制的,可以通过SETTING Frame里的SETTINGS_HEADER_TABLE_SIZE设置,默认 256Byte。
动/静态表中内部的 Index 和内部的唯一 Id,而在一次连接中 HPACK 索引列表是由静态表和动态表一起构成
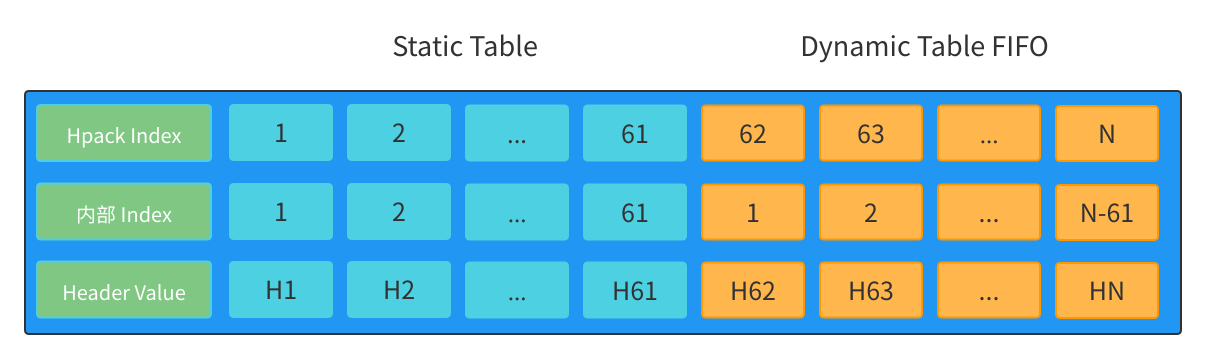 上图蓝色区域是静态表,黄色区域是动态表。
**在 HPACK 索引中静态表部分的索引和静态表的内部索引保持一致,动态表部分的索引为动态表内部索引加上静态表索引的最大值。** 在一次连接中 Client 和 Server 通过 HPACK 索引标识唯一的 Header 元素。
## HPACK Encoding
在 golang 的 `func (e *Encoder) WriteField(f HeaderField) error` 方法中可以看到什么时候用的静态表,什么时候用的动态表。先看看这个方法。
``` golang
// WriteField encodes f into a single Write to e's underlying Writer.
// This function may also produce bytes for "Header Table Size Update"
// if necessary. If produced, it is done before encoding f.
func (e *Encoder) WriteField(f HeaderField) error {
e.buf = e.buf[:0]
// 收到 SETTINGS 帧,且包含 SettingHeaderTableSize 表示动态表需要更新,才会进入到这里
if e.tableSizeUpdate {
e.tableSizeUpdate = false
if e.minSize < e.dynTab.maxSize {
e.buf = appendTableSize(e.buf, e.minSize)
}
e.minSize = uint32Max
e.buf = appendTableSize(e.buf, e.dynTab.maxSize)
}
// 查找是否被索引
idx, nameValueMatch := e.searchTable(f)
if nameValueMatch {
e.buf = appendIndexed(e.buf, idx)
} else {
// 是否应该被索引,有可能设置一些敏感词不应该被索引,golang indexing 一直是true
indexing := e.shouldIndex(f)
if indexing {
e.dynTab.add(f) // 加入动态表
}
if idx == 0 {
e.buf = appendNewName(e.buf, f, indexing)
} else {
e.buf = appendIndexedName(e.buf, f, idx, indexing)
}
}
n, err := e.w.Write(e.buf)
if err == nil && n != len(e.buf) {
err = io.ErrShortWrite
}
return err
}
```
下面我们对上面的一些函数做一些分析。
- **(e *Encoder) searchTable(f HeaderField)** 从 HPACK 索引列表中搜索 Header,并返回对应的索引。
``` golang
func (e *Encoder) searchTable(f HeaderField) (i uint64, nameValueMatch bool) {
i, nameValueMatch = staticTable.search(f)
if nameValueMatch {
return i, true
}
j, nameValueMatch := e.dynTab.table.search(f)
if nameValueMatch || (i == 0 && j != 0) {
return j + uint64(staticTable.len()), nameValueMatch
}
return i, false
}
```
搜索顺序为,先搜索静态表,如果静态表不匹配,则搜索动态表,最后返回。
## 索引 Header 表示法
### Key 和 Value 均被索引过
如果Name和Value 都已经被索引,则在Header的编码过程中直接添加索引即可
此表示法对应的函数为 appendIndexed,且该 Header 已经在索引列表中。
该函数将 Header 在 HPACK 索引列表中的索引编码,原先的 Header 最后仅用少量的几个字节就可以表示。
``` golang
func appendIndexed(dst []byte, i uint64) []byte {
first := len(dst)
dst = appendVarInt(dst, 7, i)
dst[first] |= 0x80
return dst
}
```
由appendIndexed知,用索引头字段表示法时,第一个字节的格式必须是 **0b1xxxxxxx**,即第 0 位必须为1,低 7 位用来表示值。
如果索引大于 **uint64((1 << n) - 1)**时,需要使用多个字节来存储索引的值,步骤如下:
1. 第一个字节的最低 n 位全为 1。
2. 索引 i 减去 **uint64((1 << n) - 1)**后,每次取低 7 位或上**0b10000000**, 然后 i 右移 7 位并和 128 进行比较,判断是否进入下一次循环。
3. 循环结束后将剩下的 i 值直接放入 buf 中。
用这种方法表示 Header 时,仅需要少量字节就可以表示一个完整的 Header 头字段,最好的情况是一个字节就可以表示一个 Header 字段。
> VarInt 是一种编码方式, 可以参考 https://zhuanlan.zhihu.com/p/84250836
可参考 rfc7541#section-6.1
```
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 1 | Index (7+) |
+---+---------------------------+
```
### 增加动态表
当已有的HPACK表中没有索引时,需要增加动态表。此时对应的是 **e.dynTab.add(f)** 该方法
``` golang
func (dt *dynamicTable) add(f HeaderField) {
dt.table.addEntry(f)
dt.size += f.Size()
dt.evict()
}
```
动态表新增非常简单,就是简单的 addEntry 方法,其本质是静态 Huffman 编码,但实际上的编码过程在后面的两个函数 **appendNewName(e.buf, f, indexing)** 和 **appendIndexedName(e.buf, f, idx, indexing)**
这两个函数分别表示 一、Header 的 Name 和 Value 均无匹配索引; 二、Header 的 Name 有匹配索引
这两种情况均会将 Header 添加到动态表中。
先看 **appendNewName(e.buf, f, indexing)** 这个函数。
``` golang
func appendNewName(dst []byte, f HeaderField, indexing bool) []byte {
dst = append(dst, encodeTypeByte(indexing, f.Sensitive)) // 返回0x40
dst = appendHpackString(dst, f.Name)
return appendHpackString(dst, f.Value)
}
```
经过编码后会呈下图所示:可参考 rfc7541#section-6.2.1
```
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 0 | 1 | 0 |
+---+---+-----------------------+
| H | Name Length (7+) |
+---+---------------------------+
| Name String (Length octets) |
+---+---------------------------+
| H | Value Length (7+) |
+---+---------------------------+
| Value String (Length octets) |
+-------------------------------+
```
另一个 **appendIndexedName(e.buf, f, idx, indexing)** 方法
``` golang
func appendIndexedName(dst []byte, f HeaderField, i uint64, indexing bool) []byte {
first := len(dst)
var n byte
if indexing { // 是否应该被索引
n = 6
} else {
n = 4
}
dst = appendVarInt(dst, n, i)
dst[first] |= encodeTypeByte(indexing, f.Sensitive)
return appendHpackString(dst, f.Value)
}
```
经过编码后会呈下图所示:可参考 rfc7541#section-6.2.1
```
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 0 | 1 | Index (6+) |
+---+---+-----------------------+
| H | Value Length (7+) |
+---+---------------------------+
| Value String (Length octets) |
+-------------------------------+
```
### Huffman 编码原理
Hpack 中的 Huffman 是静态Huffman编码,对应上面的 **appendHpackString** 函数,接下来我们详细看看。
``` golang
func appendHpackString(dst []byte, s string) []byte {
huffmanLength := HuffmanEncodeLength(s)
if huffmanLength < uint64(len(s)) {
first := len(dst)
dst = appendVarInt(dst, 7, huffmanLength)
dst = AppendHuffmanString(dst, s)
dst[first] |= 0x80
} else {
dst = appendVarInt(dst, 7, uint64(len(s)))
dst = append(dst, s...)
}
return dst
}
```
这个方法有一个 if-else ,是为了判断是否要 Huffman 编码 ,如果编码后长度反而变大了,那还不如不编码用原始字符。
Huffman 编码原理如下,就是对静态 Huffman 表进行查询,将传输中的字符串编码。
``` golang
func appendByteToHuffmanCode(dst []byte, rembits uint8, c byte) ([]byte, uint8) {
code := huffmanCodes[c]
nbits := huffmanCodeLen[c]
for {
if rembits > nbits {
t := uint8(code << (rembits - nbits))
dst[len(dst)-1] |= t
rembits -= nbits
break
}
t := uint8(code >> (nbits - rembits))
dst[len(dst)-1] |= t
nbits -= rembits
rembits = 8
if nbits == 0 {
break
}
dst = append(dst, 0)
}
return dst, rembits
}
var huffmanCodes = [256]uint32{
0x1ff8,
0x7fffd8,
0xfffffe2,
0xfffffe3,
0xfffffe4,
....
}
var huffmanCodeLen = [256]uint8{
13, 23, 28, 28, 28, 28, 28, 28, 28, 24, 30, 28, 28, 30, 28, 28,
28, 28, 28, 28, 28, 28, 30, 28, 28, 28, 28, 28, 28, 28, 28, 28,
...
}
```
# 验证&总结
## HPACK 编码
``` golang
var (
buf bytes.Buffer
oriSize int
)
henc := hpack.NewEncoder(&buf)
headers := []hpack.HeaderField{
{Name: ":authority", Value: "dss0.bdstatic.com"},
{Name: ":method", Value: "GET"},
{Name: ":path", Value: "/5aV1bjqh_Q23odCf/static/superman/img/topnav/baiduyun@2x-e0be79e69e.png"},
{Name: ":scheme", Value: "https"},
{Name: "accept-encoding", Value: "gzip"},
{Name: "user-agent", Value: "Go-http-client/2.0"},
{Name: "custom-header", Value: "custom-value"},
}
for _, header := range headers {
oriSize += len(header.Name) + len(header.Value)
henc.WriteField(header)
}
fmt.Printf("ori size: %v, encoded size: %v\n", oriSize, buf.Len())
//输出为:ori size: 197, encoded size: 111
```
## HPACK 解码
``` golang
// 此处省略HPACK编码中的编码例子
var (
invalid error
sawRegular bool
// 16 << 20 from fr.maxHeaderListSize() from
remainSize uint32 = 16 << 20
)
hdec := hpack.NewDecoder(4096, nil)
// 16 << 20 from fr.maxHeaderStringLen() from fr.maxHeaderListSize()
hdec.SetMaxStringLength(int(remainSize))
hdec.SetEmitFunc(func(hf hpack.HeaderField) {
if !httpguts.ValidHeaderFieldValue(hf.Value) {
invalid = fmt.Errorf("invalid header field value %q", hf.Value)
}
isPseudo := strings.HasPrefix(hf.Name, ":")
if isPseudo {
if sawRegular {
invalid = errors.New("pseudo header field after regular")
}
} else {
sawRegular = true
// if !http2validWireHeaderFieldName(hf.Name) {
// invliad = fmt.Sprintf("invalid header field name %q", hf.Name)
// }
}
if invalid != nil {
fmt.Println(invalid)
hdec.SetEmitEnabled(false)
return
}
size := hf.Size()
if size > remainSize {
hdec.SetEmitEnabled(false)
// mh.Truncated = true
return
}
remainSize -= size
fmt.Printf("%+v\n", hf)
// mh.Fields = append(mh.Fields, hf)
})
defer hdec.SetEmitFunc(func(hf hpack.HeaderField) {})
fmt.Println(hdec.Write(buf.Bytes()))
// 输出如下:
// ori size: 197, encoded size: 111
// header field ":authority" = "dss0.bdstatic.com"
// header field ":method" = "GET"
// header field ":path" = "/5aV1bjqh_Q23odCf/static/superman/img/topnav/baiduyun@2x-e0be79e69e.png"
// header field ":scheme" = "https"
// header field "accept-encoding" = "gzip"
// header field "user-agent" = "Go-http-client/2.0"
// header field "custom-header" = "custom-value"
// 111
```
上图蓝色区域是静态表,黄色区域是动态表。
**在 HPACK 索引中静态表部分的索引和静态表的内部索引保持一致,动态表部分的索引为动态表内部索引加上静态表索引的最大值。** 在一次连接中 Client 和 Server 通过 HPACK 索引标识唯一的 Header 元素。
## HPACK Encoding
在 golang 的 `func (e *Encoder) WriteField(f HeaderField) error` 方法中可以看到什么时候用的静态表,什么时候用的动态表。先看看这个方法。
``` golang
// WriteField encodes f into a single Write to e's underlying Writer.
// This function may also produce bytes for "Header Table Size Update"
// if necessary. If produced, it is done before encoding f.
func (e *Encoder) WriteField(f HeaderField) error {
e.buf = e.buf[:0]
// 收到 SETTINGS 帧,且包含 SettingHeaderTableSize 表示动态表需要更新,才会进入到这里
if e.tableSizeUpdate {
e.tableSizeUpdate = false
if e.minSize < e.dynTab.maxSize {
e.buf = appendTableSize(e.buf, e.minSize)
}
e.minSize = uint32Max
e.buf = appendTableSize(e.buf, e.dynTab.maxSize)
}
// 查找是否被索引
idx, nameValueMatch := e.searchTable(f)
if nameValueMatch {
e.buf = appendIndexed(e.buf, idx)
} else {
// 是否应该被索引,有可能设置一些敏感词不应该被索引,golang indexing 一直是true
indexing := e.shouldIndex(f)
if indexing {
e.dynTab.add(f) // 加入动态表
}
if idx == 0 {
e.buf = appendNewName(e.buf, f, indexing)
} else {
e.buf = appendIndexedName(e.buf, f, idx, indexing)
}
}
n, err := e.w.Write(e.buf)
if err == nil && n != len(e.buf) {
err = io.ErrShortWrite
}
return err
}
```
下面我们对上面的一些函数做一些分析。
- **(e *Encoder) searchTable(f HeaderField)** 从 HPACK 索引列表中搜索 Header,并返回对应的索引。
``` golang
func (e *Encoder) searchTable(f HeaderField) (i uint64, nameValueMatch bool) {
i, nameValueMatch = staticTable.search(f)
if nameValueMatch {
return i, true
}
j, nameValueMatch := e.dynTab.table.search(f)
if nameValueMatch || (i == 0 && j != 0) {
return j + uint64(staticTable.len()), nameValueMatch
}
return i, false
}
```
搜索顺序为,先搜索静态表,如果静态表不匹配,则搜索动态表,最后返回。
## 索引 Header 表示法
### Key 和 Value 均被索引过
如果Name和Value 都已经被索引,则在Header的编码过程中直接添加索引即可
此表示法对应的函数为 appendIndexed,且该 Header 已经在索引列表中。
该函数将 Header 在 HPACK 索引列表中的索引编码,原先的 Header 最后仅用少量的几个字节就可以表示。
``` golang
func appendIndexed(dst []byte, i uint64) []byte {
first := len(dst)
dst = appendVarInt(dst, 7, i)
dst[first] |= 0x80
return dst
}
```
由appendIndexed知,用索引头字段表示法时,第一个字节的格式必须是 **0b1xxxxxxx**,即第 0 位必须为1,低 7 位用来表示值。
如果索引大于 **uint64((1 << n) - 1)**时,需要使用多个字节来存储索引的值,步骤如下:
1. 第一个字节的最低 n 位全为 1。
2. 索引 i 减去 **uint64((1 << n) - 1)**后,每次取低 7 位或上**0b10000000**, 然后 i 右移 7 位并和 128 进行比较,判断是否进入下一次循环。
3. 循环结束后将剩下的 i 值直接放入 buf 中。
用这种方法表示 Header 时,仅需要少量字节就可以表示一个完整的 Header 头字段,最好的情况是一个字节就可以表示一个 Header 字段。
> VarInt 是一种编码方式, 可以参考 https://zhuanlan.zhihu.com/p/84250836
可参考 rfc7541#section-6.1
```
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 1 | Index (7+) |
+---+---------------------------+
```
### 增加动态表
当已有的HPACK表中没有索引时,需要增加动态表。此时对应的是 **e.dynTab.add(f)** 该方法
``` golang
func (dt *dynamicTable) add(f HeaderField) {
dt.table.addEntry(f)
dt.size += f.Size()
dt.evict()
}
```
动态表新增非常简单,就是简单的 addEntry 方法,其本质是静态 Huffman 编码,但实际上的编码过程在后面的两个函数 **appendNewName(e.buf, f, indexing)** 和 **appendIndexedName(e.buf, f, idx, indexing)**
这两个函数分别表示 一、Header 的 Name 和 Value 均无匹配索引; 二、Header 的 Name 有匹配索引
这两种情况均会将 Header 添加到动态表中。
先看 **appendNewName(e.buf, f, indexing)** 这个函数。
``` golang
func appendNewName(dst []byte, f HeaderField, indexing bool) []byte {
dst = append(dst, encodeTypeByte(indexing, f.Sensitive)) // 返回0x40
dst = appendHpackString(dst, f.Name)
return appendHpackString(dst, f.Value)
}
```
经过编码后会呈下图所示:可参考 rfc7541#section-6.2.1
```
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 0 | 1 | 0 |
+---+---+-----------------------+
| H | Name Length (7+) |
+---+---------------------------+
| Name String (Length octets) |
+---+---------------------------+
| H | Value Length (7+) |
+---+---------------------------+
| Value String (Length octets) |
+-------------------------------+
```
另一个 **appendIndexedName(e.buf, f, idx, indexing)** 方法
``` golang
func appendIndexedName(dst []byte, f HeaderField, i uint64, indexing bool) []byte {
first := len(dst)
var n byte
if indexing { // 是否应该被索引
n = 6
} else {
n = 4
}
dst = appendVarInt(dst, n, i)
dst[first] |= encodeTypeByte(indexing, f.Sensitive)
return appendHpackString(dst, f.Value)
}
```
经过编码后会呈下图所示:可参考 rfc7541#section-6.2.1
```
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 0 | 1 | Index (6+) |
+---+---+-----------------------+
| H | Value Length (7+) |
+---+---------------------------+
| Value String (Length octets) |
+-------------------------------+
```
### Huffman 编码原理
Hpack 中的 Huffman 是静态Huffman编码,对应上面的 **appendHpackString** 函数,接下来我们详细看看。
``` golang
func appendHpackString(dst []byte, s string) []byte {
huffmanLength := HuffmanEncodeLength(s)
if huffmanLength < uint64(len(s)) {
first := len(dst)
dst = appendVarInt(dst, 7, huffmanLength)
dst = AppendHuffmanString(dst, s)
dst[first] |= 0x80
} else {
dst = appendVarInt(dst, 7, uint64(len(s)))
dst = append(dst, s...)
}
return dst
}
```
这个方法有一个 if-else ,是为了判断是否要 Huffman 编码 ,如果编码后长度反而变大了,那还不如不编码用原始字符。
Huffman 编码原理如下,就是对静态 Huffman 表进行查询,将传输中的字符串编码。
``` golang
func appendByteToHuffmanCode(dst []byte, rembits uint8, c byte) ([]byte, uint8) {
code := huffmanCodes[c]
nbits := huffmanCodeLen[c]
for {
if rembits > nbits {
t := uint8(code << (rembits - nbits))
dst[len(dst)-1] |= t
rembits -= nbits
break
}
t := uint8(code >> (nbits - rembits))
dst[len(dst)-1] |= t
nbits -= rembits
rembits = 8
if nbits == 0 {
break
}
dst = append(dst, 0)
}
return dst, rembits
}
var huffmanCodes = [256]uint32{
0x1ff8,
0x7fffd8,
0xfffffe2,
0xfffffe3,
0xfffffe4,
....
}
var huffmanCodeLen = [256]uint8{
13, 23, 28, 28, 28, 28, 28, 28, 28, 24, 30, 28, 28, 30, 28, 28,
28, 28, 28, 28, 28, 28, 30, 28, 28, 28, 28, 28, 28, 28, 28, 28,
...
}
```
# 验证&总结
## HPACK 编码
``` golang
var (
buf bytes.Buffer
oriSize int
)
henc := hpack.NewEncoder(&buf)
headers := []hpack.HeaderField{
{Name: ":authority", Value: "dss0.bdstatic.com"},
{Name: ":method", Value: "GET"},
{Name: ":path", Value: "/5aV1bjqh_Q23odCf/static/superman/img/topnav/baiduyun@2x-e0be79e69e.png"},
{Name: ":scheme", Value: "https"},
{Name: "accept-encoding", Value: "gzip"},
{Name: "user-agent", Value: "Go-http-client/2.0"},
{Name: "custom-header", Value: "custom-value"},
}
for _, header := range headers {
oriSize += len(header.Name) + len(header.Value)
henc.WriteField(header)
}
fmt.Printf("ori size: %v, encoded size: %v\n", oriSize, buf.Len())
//输出为:ori size: 197, encoded size: 111
```
## HPACK 解码
``` golang
// 此处省略HPACK编码中的编码例子
var (
invalid error
sawRegular bool
// 16 << 20 from fr.maxHeaderListSize() from
remainSize uint32 = 16 << 20
)
hdec := hpack.NewDecoder(4096, nil)
// 16 << 20 from fr.maxHeaderStringLen() from fr.maxHeaderListSize()
hdec.SetMaxStringLength(int(remainSize))
hdec.SetEmitFunc(func(hf hpack.HeaderField) {
if !httpguts.ValidHeaderFieldValue(hf.Value) {
invalid = fmt.Errorf("invalid header field value %q", hf.Value)
}
isPseudo := strings.HasPrefix(hf.Name, ":")
if isPseudo {
if sawRegular {
invalid = errors.New("pseudo header field after regular")
}
} else {
sawRegular = true
// if !http2validWireHeaderFieldName(hf.Name) {
// invliad = fmt.Sprintf("invalid header field name %q", hf.Name)
// }
}
if invalid != nil {
fmt.Println(invalid)
hdec.SetEmitEnabled(false)
return
}
size := hf.Size()
if size > remainSize {
hdec.SetEmitEnabled(false)
// mh.Truncated = true
return
}
remainSize -= size
fmt.Printf("%+v\n", hf)
// mh.Fields = append(mh.Fields, hf)
})
defer hdec.SetEmitFunc(func(hf hpack.HeaderField) {})
fmt.Println(hdec.Write(buf.Bytes()))
// 输出如下:
// ori size: 197, encoded size: 111
// header field ":authority" = "dss0.bdstatic.com"
// header field ":method" = "GET"
// header field ":path" = "/5aV1bjqh_Q23odCf/static/superman/img/topnav/baiduyun@2x-e0be79e69e.png"
// header field ":scheme" = "https"
// header field "accept-encoding" = "gzip"
// header field "user-agent" = "Go-http-client/2.0"
// header field "custom-header" = "custom-value"
// 111
```