HTTP的第一个文档版本于1991年发布,名称为HTTP0.9,后来导致1996年正式引入并认可HTTP1.0。HTTP1.1于1997年问世,此后几乎没有迭代改进。2015年2月,互联网工程任务组(IETF)HTTP工作组修订了HTTP,并以HTTP / 2的形式开发了应用协议的第二个主要版本。
参考 kinsta.com 上 what-is-http2 这篇文章。
HTTP RFC 7540

为什么要H2
要解答这个问题,首先就需要知道HTTP1.x 出了什么问题。HTTP协议自1991年诞生依赖,很少有过大修大改。在H2之前最新版本的HTTP1.1已经为网络世界服务了15多年。随着互联网的发展速度越发的迅速,大量的消息充斥,而我们又对信息加载速度的一再苛刻要求。急需改变当前状况。
HTTP1.1 PipeLine
HTTP1.1被限制为每个TCP连接仅处理一个未完成的请求,从而迫使浏览器使用多个TCP连接来同时处理多个请求。
但是,并行使用太多TCP连接会导致TCP拥塞,从而导致网络资源的不公平垄断。Web浏览器在使用多个连接来处理请求可能造成网络请求的大幅度占用,因此降低了其他用户的网络性能。
为了解决这个问题。互联网行业自然被迫采用诸如域分片,串联,数据内联和拼写之类的做法来破解这些约束。

在HTTP1.x 中,可以用“Content-Encoding” 指定Body的编码方式,比如用 gzip 压缩来节约带宽资源,但是Header是一直没有考虑到的,Header中其实也存在大量的固定头部字段,多达上百上前字节,一些大型站点,功能复杂的,每次通信需要带上 “User Agent”、“Cookie”、“Accept” 或者一些自定义字段,这些字段都是重复的,非常浪费。“长尾效应"导致大量的带宽消耗在极度冗余的字段上。
H2 特性
多路复用

“流”是在HTTP/2连接中客户端和服务器之间交换的独立的双向帧传输队列。流有几个重要特征:
- 单个HTTP/2连接可以包含多个并发打开的流,其中任一端点从多个流交错发送多个Frame数据帧
- 流可以单方向的从客户端或者服务端建立
- 流可以被任意一方关闭
- 在流之上发送数据帧的顺序是必须的,一条流之上的Header帧在DATA帧之前。必须按照顺序
- 每一条流都一个流ID,流ID由发起方携带
- 客户端发起的流是单数递增,服务端发起的流是双数递增。
more: https://httpwg.org/specs/rfc7540.html#StreamsLayer
在 HTTP2 的golang实现中可以看到Framer这个结构体,这个结构体规定了帧的读取和发送。在创建新的 ClientConn 时,会对一个ClientConn 通过调用 cc.fr = NewFramer(cc.bw, cc.br) 创建一个 Framer ,并且将整个 net.Conn 当做了 io.Reader 和 io.Writer 参数传给了 Framer 。
在Framer内部,会维护一个 wbuf 的字节队列,新写入的 Frame 会源源不断的写入到队列中。每写入的Frame的所携带的 Stream ID 并不一样。但是相同 Stream ID 会严格保持顺序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| // A Framer reads and writes Frames.
type Framer struct {
r io.Reader
w io.Writer
wbuf []byte
...
}
func (t *Transport) newClientConn(c net.Conn, singleUse bool) (*ClientConn, error) {
cc := &ClientConn{
t: t,
tconn: c,
readerDone: make(chan struct{}),
nextStreamID: 1,
maxFrameSize: 16 << 10, // spec default
initialWindowSize: 65535, // spec default
maxConcurrentStreams: 1000, // "infinite", per spec. 1000 seems good enough.
peerMaxHeaderListSize: 0xffffffffffffffff, // "infinite", per spec. Use 2^64-1 instead.
streams: make(map[uint32]*clientStream),
singleUse: singleUse,
wantSettingsAck: true,
pings: make(map[[8]byte]chan struct{}),
}
if d := t.idleConnTimeout(); d != 0 {
cc.idleTimeout = d
cc.idleTimer = time.AfterFunc(d, cc.onIdleTimeout)
}
if VerboseLogs {
t.vlogf("http2: Transport creating client conn %p to %v", cc, c.RemoteAddr())
}
cc.cond = sync.NewCond(&cc.mu)
cc.flow.add(int32(initialWindowSize))
// TODO: adjust this writer size to account for frame size +
// MTU + crypto/tls record padding.
cc.bw = bufio.NewWriter(stickyErrWriter{c, &cc.werr})
cc.br = bufio.NewReader(c)
cc.fr = NewFramer(cc.bw, cc.br)
cc.fr.ReadMetaHeaders = hpack.NewDecoder(initialHeaderTableSize, nil)
cc.fr.MaxHeaderListSize = t.maxHeaderListSize()
// TODO: SetMaxDynamicTableSize, SetMaxDynamicTableSizeLimit on
// henc in response to SETTINGS frames?
cc.henc = hpack.NewEncoder(&cc.hbuf)
if t.AllowHTTP {
cc.nextStreamID = 3
}
if cs, ok := c.(connectionStater); ok {
state := cs.ConnectionState()
cc.tlsState = &state
}
initialSettings := []Setting{
{ID: SettingEnablePush, Val: 0},
{ID: SettingInitialWindowSize, Val: transportDefaultStreamFlow},
}
if max := t.maxHeaderListSize(); max != 0 {
initialSettings = append(initialSettings, Setting{ID: SettingMaxHeaderListSize, Val: max})
}
cc.bw.Write(clientPreface)
cc.fr.WriteSettings(initialSettings...)
cc.fr.WriteWindowUpdate(0, transportDefaultConnFlow)
cc.inflow.add(transportDefaultConnFlow + initialWindowSize)
cc.bw.Flush()
if cc.werr != nil {
return nil, cc.werr
}
go cc.readLoop()
return cc, nil
}
|
可以看到。63 行的 cc.bw 可以任意写入非Frame的字符串,如果需要写入 Frame 的话,会通过 64 行的cc.fr.WriteXXXX 写入。如下面的 Setting 帧的写入 。HTTP2 发送一个帧的实现就是将该帧结构完完整整的塞入 wbuf 中, 由 startWrite 写入wbuf, 再由endWrite 函数将wbuf 写入 io.Writer 中,刚才在 NewFramer(cc.bw, cc.br) 函数中已经看到了,io.Writer 就是 net.Conn, 也就是这个 Frame 被发出去了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| // WriteSettings writes a SETTINGS frame with zero or more settings
// specified and the ACK bit not set.
//
// It will perform exactly one Write to the underlying Writer.
// It is the caller's responsibility to not call other Write methods concurrently.
func (f *Framer) WriteSettings(settings ...Setting) error {
f.startWrite(FrameSettings, 0, 0)
for _, s := range settings {
f.writeUint16(uint16(s.ID))
f.writeUint32(s.Val)
}
return f.endWrite()
}
func (f *Framer) startWrite(ftype FrameType, flags Flags, streamID uint32) {
// Write the FrameHeader.
f.wbuf = append(f.wbuf[:0],
0, // 3 bytes of length, filled in in endWrite
0,
0,
byte(ftype),
byte(flags),
byte(streamID>>24),
byte(streamID>>16),
byte(streamID>>8),
byte(streamID))
}
func (f *Framer) endWrite() error {
// Now that we know the final size, fill in the FrameHeader in
// the space previously reserved for it. Abuse append.
length := len(f.wbuf) - frameHeaderLen
if length >= (1 << 24) {
return ErrFrameTooLarge
}
_ = append(f.wbuf[:0],
byte(length>>16),
byte(length>>8),
byte(length))
if f.logWrites {
f.logWrite()
}
n, err := f.w.Write(f.wbuf)
if err == nil && n != len(f.wbuf) {
err = io.ErrShortWrite
}
return err
}
|
那么由此就得知了流的组成,和流多路复用的原理。以及流之间的帧是有顺序的。(这个例子足够简单,以至于没有实现流优先级的概念,也没有流控之类的概念,后面我们再介绍)
但是我们帧可以任意交织在一起。实现一套逻辑层面的流的概念。
更多帧格式参见:https://httpwg.org/specs/rfc7540.html#FrameTypes
HPACK

在 HTTP1.1 中,每一个请求都携带着沉重的 header,包含 cookie 、trace-link、server-timing、X-FF 信息。
在网站提供丰富媒体内容的情况下,客户端发送多个几乎相同的HTTP头部,会导致延迟和有限的网络资源的不必要消耗。HTTP2 正是针对这点进行了优化,
HPACK 正是HTTP2 减少HTTP请求header的秘诀,HPACK 由 RFC7541 规定。
而HPACK 的压缩方式分 3 种
- 静态字典
- 动态字典
- 压缩算法:Huffman 压缩 (最高压缩比 8:5)
静态字典
https://httpwg.org/specs/rfc7541.html#static.table.definition
静态字典由 index、header name、header value 组成,比如字符2就可以直接代表 :method : GET
1
2
3
4
5
| Index Header Name Header Value
1 :authority
2 :method GET
3 :method POST
4 :path /
|
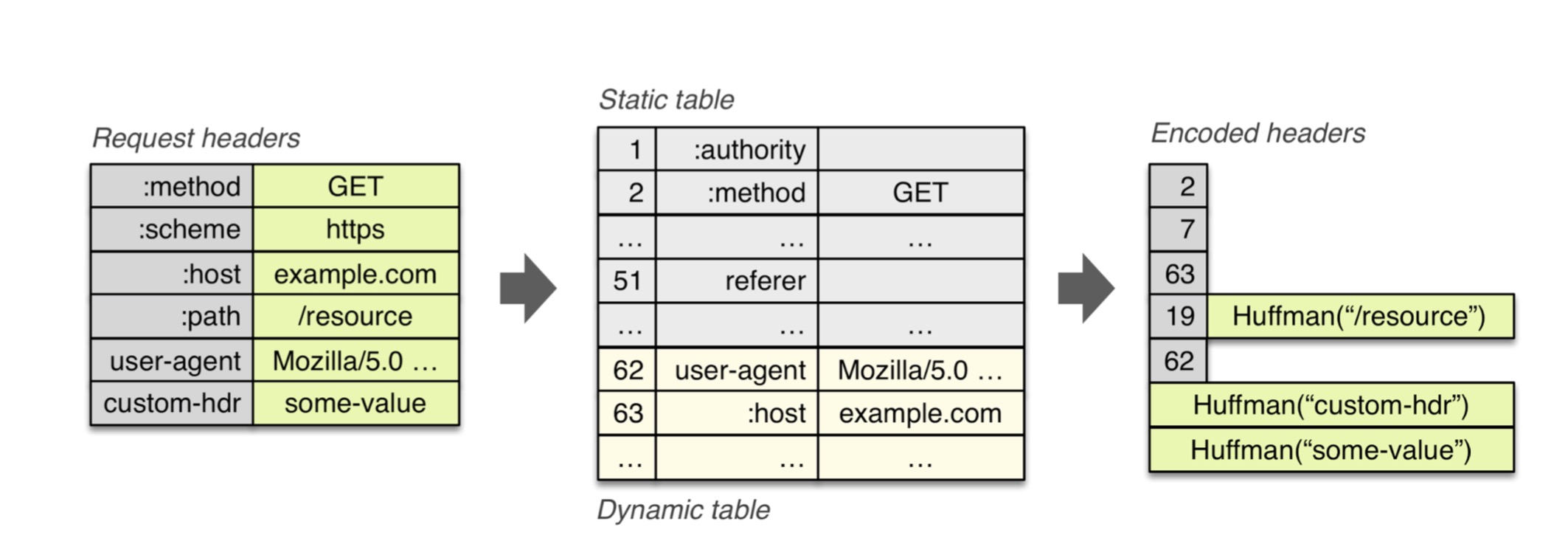
可以在静态表字典里查到的会直接引用,无法查到的会进行 Huffman 编码。
静态表一共有61项,动态表采用先入先出的淘汰策略,大小由 SETTINGS_HEADER_TABLE_SIZE 控制。
Huffman 编码原理
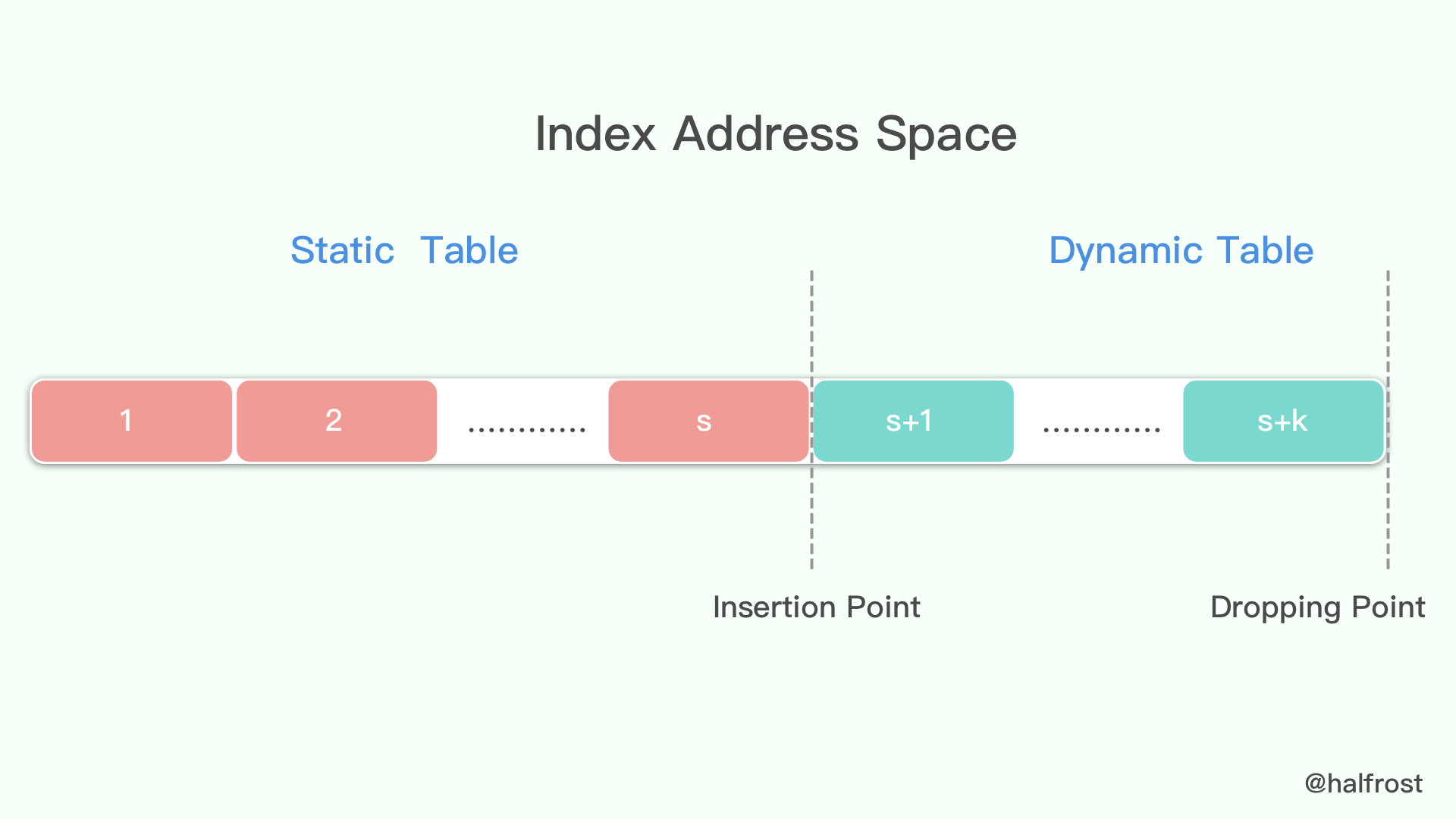
出现概率较大的字符串用较短的数字编码,出现概率较小的字符串用比较长的数字编码。
huffman 编码分两种,一种是静态 huffman,一种是动态huffman,静态huffman编码是对当前已有的字符的一个出现概率的统计。0、1、.、a、c、e 等字符串出现概率较高,所以就用较短的字符做映射从而统计生成了一套静态 huffmane 编码表。早先的 spdy 使用的动态huffman编码,但是容易被攻击,所以HTTP2使用的都是静态 huffman 编码,
- 计算各字母的出现概率
- 将出现概率较小的两个字母相加构成子树,左小右大
- 重复步骤二完成树的构建
- 给树的左链接编码0.右链接编码1
- 每个字母的编码即从根节点至叶节点的串联和
huffman 树编码(Huffman Decoding)
举例
有一串字符
A 出现 25 次 、 B 出现 15 次、C 出现 14 次、 D 出现 20 次、 E 出现 17 次、F 出现9 次
按照左小右大的规则。 F 与 C 组成一组, 加起来是 23 ,以此类推。
从 Golang 的 hpack 实现中可以调取 http2/hpack 来做header编解码。核心代码只有2部分,NewEncoder 创建一个编码Encoder对象。通过 WriteFeild 来实现header内容的写入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| // NewEncoder returns a new Encoder which performs HPACK encoding. An
// encoded data is written to w.
func NewEncoder(w io.Writer) *Encoder {
e := &Encoder{
minSize: uint32Max,
maxSizeLimit: initialHeaderTableSize,
tableSizeUpdate: false,
w: w,
}
e.dynTab.table.init()
e.dynTab.setMaxSize(initialHeaderTableSize)
return e
}
// WriteField encodes f into a single Write to e's underlying Writer.
// This function may also produce bytes for "Header Table Size Update"
// if necessary. If produced, it is done before encoding f.
func (e *Encoder) WriteField(f HeaderField) error {
e.buf = e.buf[:0]
if e.tableSizeUpdate {
e.tableSizeUpdate = false
if e.minSize < e.dynTab.maxSize {
e.buf = appendTableSize(e.buf, e.minSize)
}
e.minSize = uint32Max
e.buf = appendTableSize(e.buf, e.dynTab.maxSize)
}
idx, nameValueMatch := e.searchTable(f)
if nameValueMatch {
e.buf = appendIndexed(e.buf, idx)
} else {
indexing := e.shouldIndex(f)
if indexing {
e.dynTab.add(f)
}
if idx == 0 {
e.buf = appendNewName(e.buf, f, indexing)
} else {
e.buf = appendIndexedName(e.buf, f, idx, indexing)
}
}
n, err := e.w.Write(e.buf)
if err == nil && n != len(e.buf) {
err = io.ErrShortWrite
}
return err
}
|
- 代码第21行,更新增大动态表size,这个不用关心,只有SETTING帧协商时才会变大,正常是走不到21行的这个if语句。
- 代码第30行,在hpack表(静态表+动态表)中搜索,如果能搜到(name+value)则在第32行将索引写入buffer中,否则在第34行判断一下是否可以索引,可以索引的话就加入到动态表,如果 idx 为0(name和value都没有查到)则对整个header kv进行索引,如果有idx,证明只是value没有被索引,只对value 索引即可
下面以 appendNewName(dst []byte, f HeaderField, indexing bool) 为例
1
2
3
4
5
6
7
8
9
10
11
12
| // appendNewName appends f, as encoded in one of "Literal Header field
// - New Name" representation variants, to dst and returns the
// extended buffer.
//
// If f.Sensitive is true, "Never Indexed" representation is used. If
// f.Sensitive is false and indexing is true, "Incremental Indexing"
// representation is used.
func appendNewName(dst []byte, f HeaderField, indexing bool) []byte {
dst = append(dst, encodeTypeByte(indexing, f.Sensitive))
dst = appendHpackString(dst, f.Name)
return appendHpackString(dst, f.Value)
}
|
- 第9行代码,表示加一个前缀,表示该字段是否可以被索引,sensitive如果为true的话表示不能被索引,比如一些每次请求绝对会变化的value,如
server-timing就不能被索引。 - 第10行代码,将Header Name 进行动态表索引。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| // appendHpackString appends s, as encoded in "String Literal"
// representation, to dst and returns the extended buffer.
//
// s will be encoded in Huffman codes only when it produces strictly
// shorter byte string.
func appendHpackString(dst []byte, s string) []byte {
huffmanLength := HuffmanEncodeLength(s)
if huffmanLength < uint64(len(s)) {
first := len(dst)
dst = appendVarInt(dst, 7, huffmanLength)
dst = AppendHuffmanString(dst, s)
dst[first] |= 0x80
} else {
dst = appendVarInt(dst, 7, uint64(len(s)))
dst = append(dst, s...)
}
return dst
}
|
- 第7行代码获取huffman编码后的长度, string 的每一位被编码后的长度之和会由
HuffmanEncodeLength提供,如果Huffman编码后有字节节省才会真正编码。负责直接将原数据直接加入到 dst buffer 中。 - 第8行证明了Huffman 编码更有优势。在buffer开始或等于 0x80 表示 Huffman编码。并由
AppendHuffmanString(dst, s) 真正开始Huffman编码。由于是静态Huffman编码,所以接下来要做的事情就是查表了。
实际上可供编码的只有7位,最高位置1表示是huffman 编码。
例如:method: GET 在静态表中为 2,则最终编码为 1000 0010 hex 表示为82
![]()
名字和值都在索引表中
![]()
名字在索引表中,值进行编码
![]()
名字和值都不在索引表中,2个都进行huffman编码
HPACK 压缩比检测:
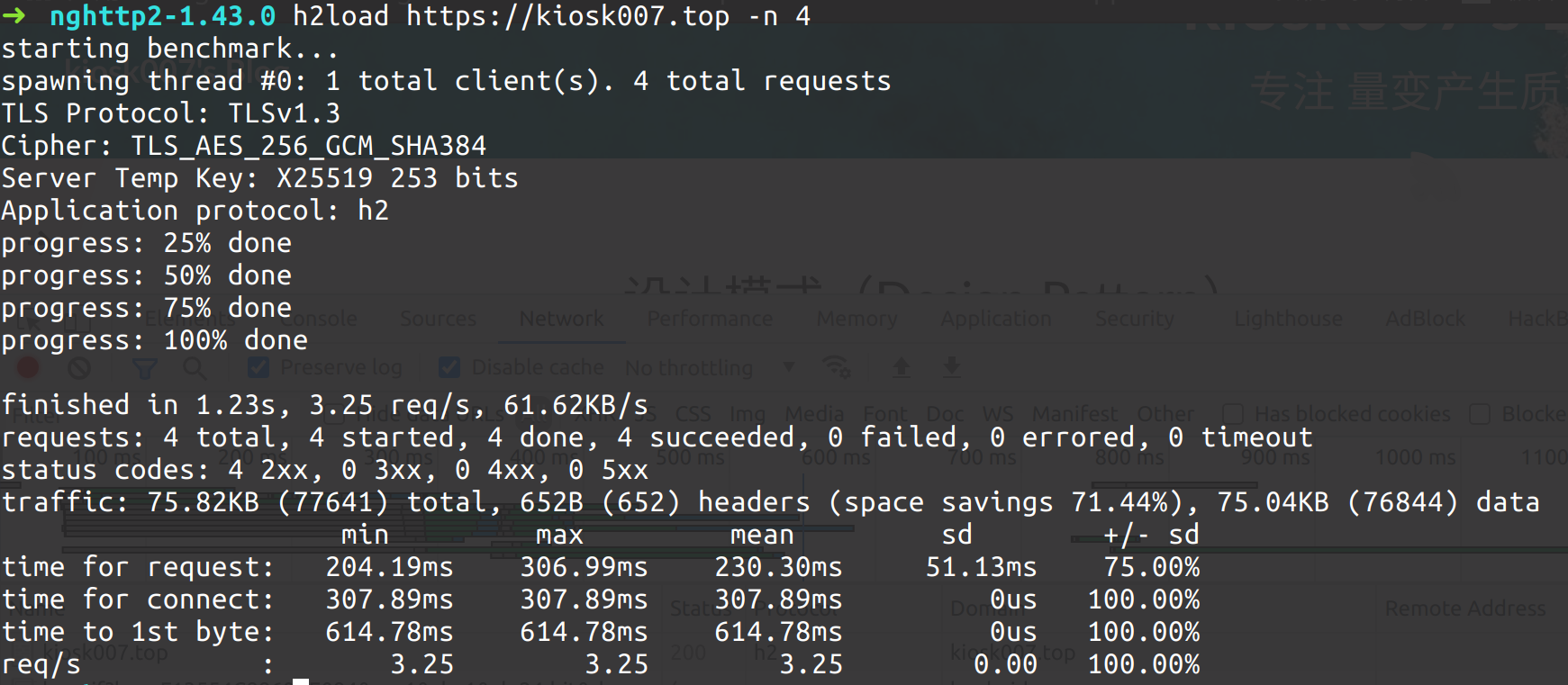
空间节省了 71.44% , 访问的次数越多,节约的空间越多,访问一次只会发挥 静态表和huffman 算法的作用。
流优先级 && 流控

这里就先说流控吧。
HTTP2 一般 Connection 和 Stream 的初始 flow-control window 大小都是 65535 bytes (如果一切顺利不丢包的情况下,RTT为 100ms,则每秒最多能发送65535*(1000/100)的数据,大约就是600KB/s)。通过发送 SETTINGS Frame,携带 SETTINGS_INITIAL_WINDOW_SIZE ,修改初始窗口大小。如果当前窗口已存在,会做delta 更新,这个值即为新的 stream flow-control window 初始大小。

通过对官方代码按照 RFC 实现的http2库分析:
首先服务端视角,入向流量每收到一个 DataFrame 都会在自身链接级别和流级别更新当前的 flow-control,而每创建一个新stream时,其入向 sc.inflow 是继承当前连接级别的 flow-control 。即所有 stream 级别的窗口之和等于 Connection 级别的窗口。
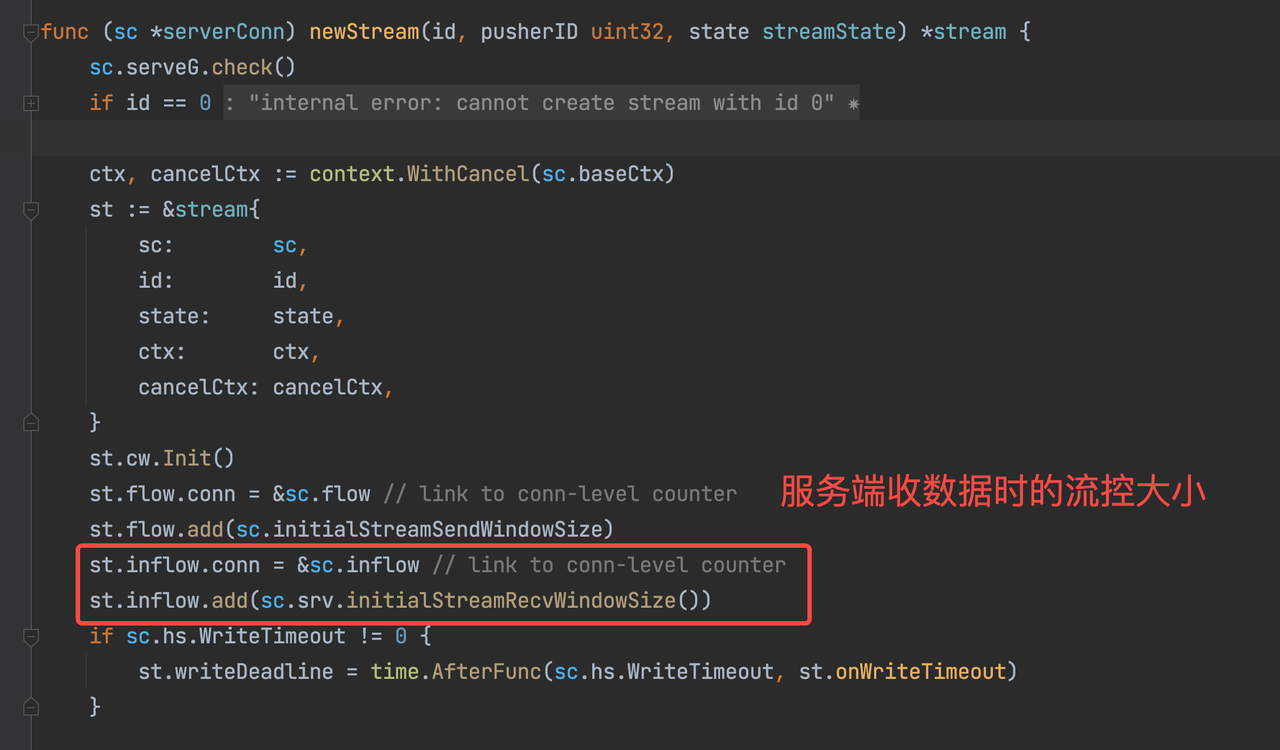
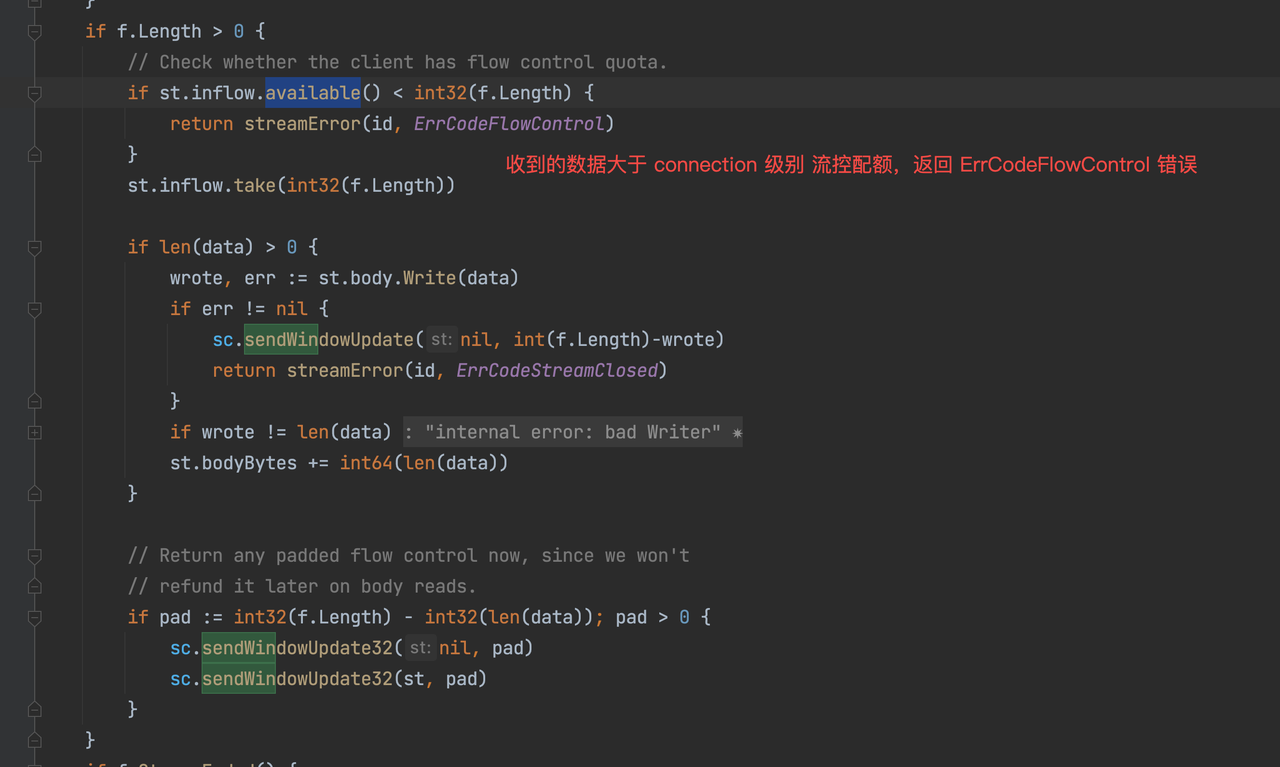
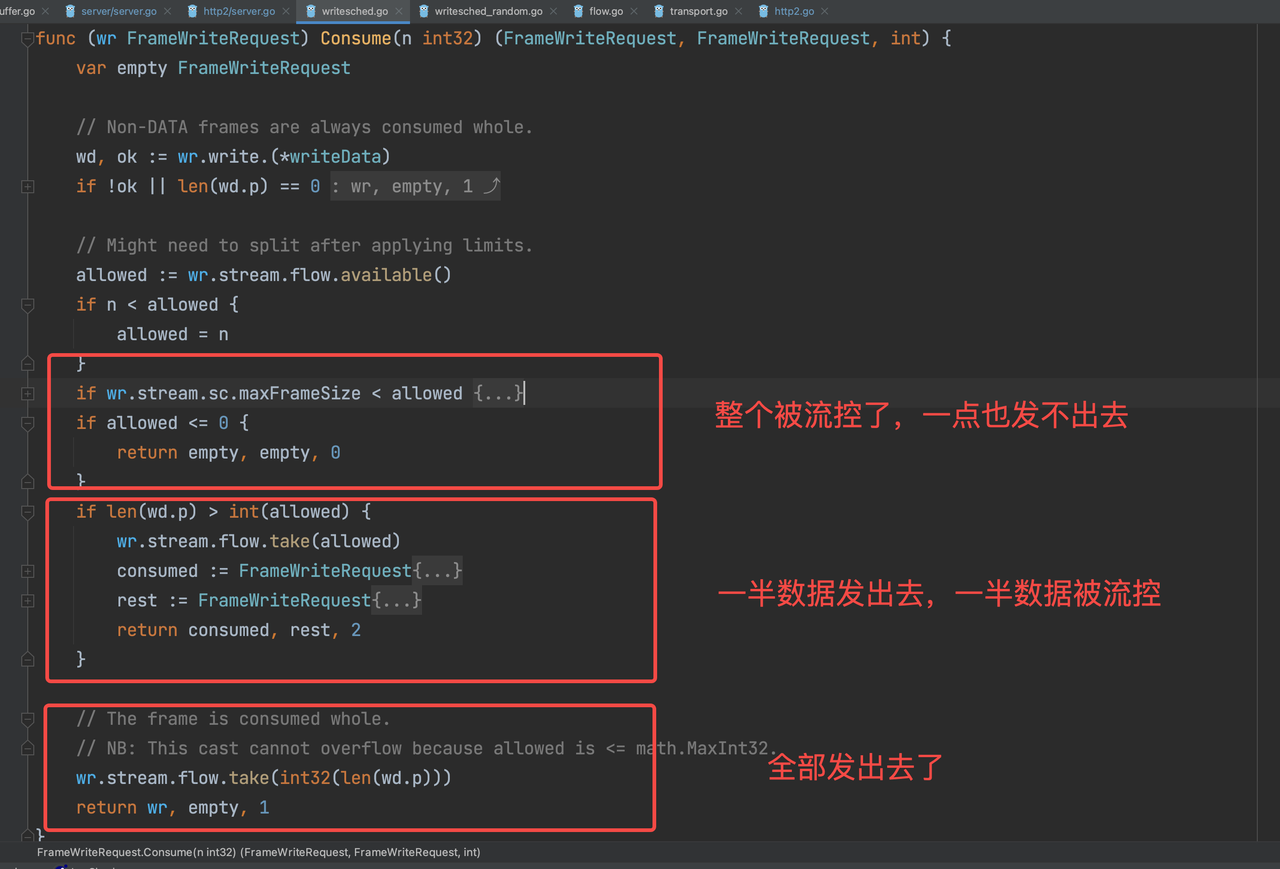
整个发送过程会遵从流控限制,如果窗口 > 0 但是 窗口 < 客户端要发送的数据,客户端要发送的数据会被分成2部分,其中流控内的数据会被发送
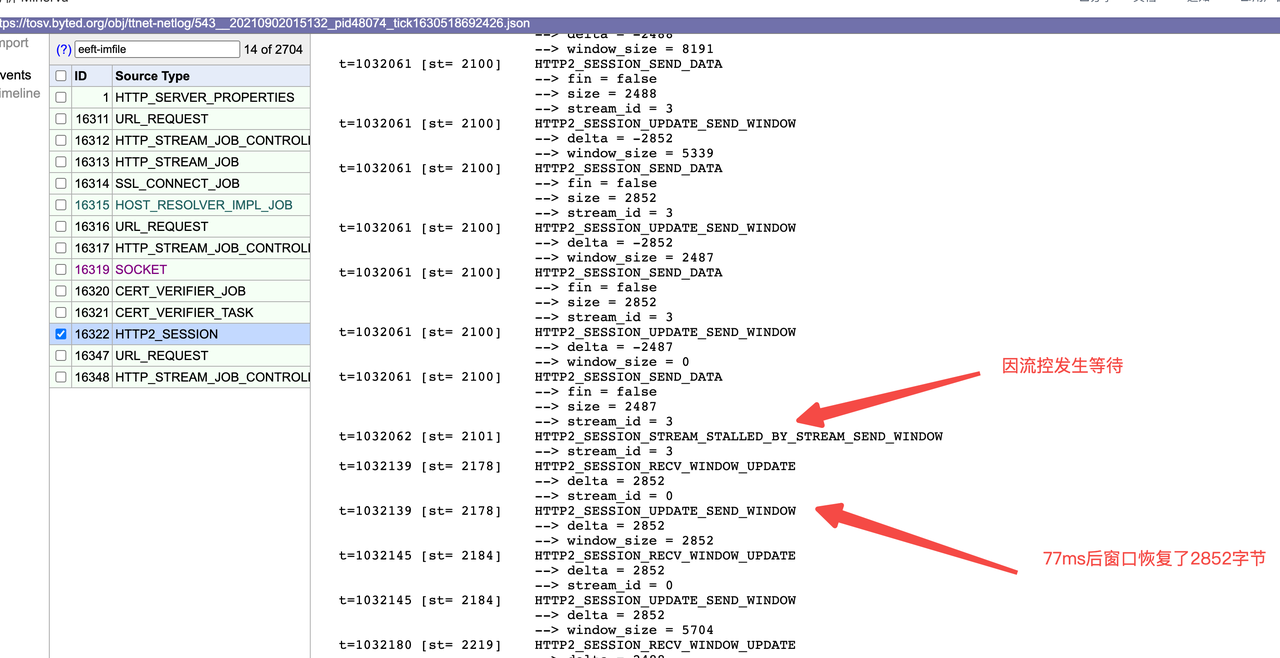
在一次实际的上传过程中,观察到如下的一次上传的 netlog。服务端的窗口经常因为耗尽而等待,等待时长约 70ms + ,与akamai 的 ping 延迟基本也在 30-60ms 。每次窗口恢复和挤牙膏一样非常缓慢。
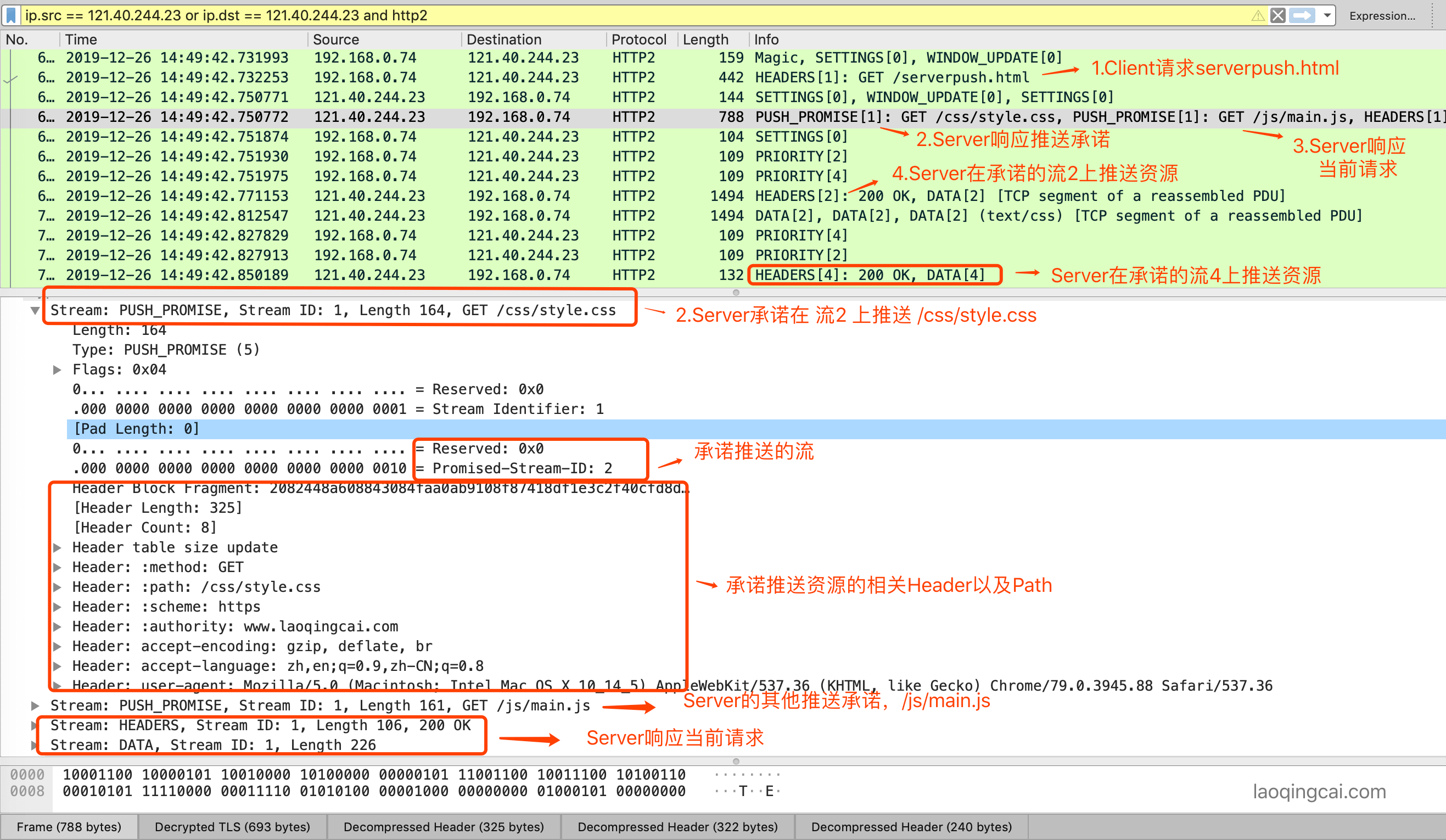
Server Push
Push Promise 是HTTP2 与 HTTP1.1 最大的一个区别,它是指在客户端在发起一个请求时,服务端在返回该请求响应之前,返回一个 PushPromise 表示有资源要推送,并且会再新开一个偶数流,推送内容,在客户端发起请求之前让客户端拿到数据。如下是 push promise 的服务端实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| func NewPushHandler() http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
for path, handler := range pushResources {
if r.URL.Path == path {
handler.ServeHTTP(w, r)
return
}
}
cacheBust := time.Now().UnixNano()
if pusher, ok := w.(http.Pusher); ok {
for path := range pushResources {
url := fmt.Sprintf("%s?%d", path, cacheBust)
if err := pusher.Push(url, nil); err != nil {
log.Printf("Failed to push %v: %v", path, err)
}
}
}
time.Sleep(100 * time.Millisecond) // fake network latency + parsing time
if err := PushTmpl.Execute(w, struct {
CacheBust int64
HTTPSHost string
HTTP1Prefix string
}{
CacheBust: cacheBust,
HTTPSHost: HttpsHost(),
HTTP1Prefix: Http1Prefix(),
}); err != nil {
log.Printf("Executing server push template: %v", err)
}
})
}
|
连接前言
TLS 握手成功之后,客户端需要发送一个"连接前言”(connection preface),用来确认HTTP/2的连接。Magic被称为H2不可知的魔法。而PRISM,其实就是在暗讽2013年斯诺登事件爆出的“棱镜计划”。
参考:https://blog.jgc.org/2015/11/the-secret-message-hidden-in-every.html
1
| Magic: PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
|
参考: