Golang GMP模型
介绍 GMP 的文章有很多了,大家应该也粗浅的知道什么G(goroutine)M(Machine)P(Processsor)。相较于 Java 这样的编程语言,我们经常听到一个线程池的概念。线程池就是提前创建若干个线程,如果有任务需要处理,线程池里的线程就会处理任务,处理完之后线程并不会被销毁,而是等待下一个任务。由于创建和销毁线程都是消耗系统资源的,所以当你想要频繁的创建和销毁线程的时候就可以考虑使用线程池来提升系统的性能。
GMP 的出现可以类比Java中的线程池,当然也有像 ants 这样的协程池实现,但是本质上 Golang GMP 就是在很好的完成线程池的角色任务。
GMP 模型简介
G-M-P分别代表:
- G - Goroutine,Go协程,是参与调度与执行的最小单位
- M - Machine,指的是系统级线程
- P - Processor,指的是逻辑处理器,P关联了的本地可运行G的队列(也称为LRQ),最多可存放256个G。
Go 语言的协程调度
Go 为了提供更容易的使用的并发方法,使用了 goroutine 和 channel。goroutine 来自协程的概念,让一组可复用的函数运行在一组线程之上。即使某个协程发生了阻塞,该线程上的其他协程也可以被 runtime 调度到其他可运行的线程之上,最关键的是,程序员看不到这些底层的调度逻辑。
协程同时非常轻量,一个 goroutine的栈只占几KB,并且其实际可以伸缩,如果需要更多的内容,runtime 会自动再分配。
GMP调度流程大致如下:
- 线程M想运行任务就需得获取 P,即与P关联。
- 然从 P 的本地队列(LRQ)获取 G
- 若LRQ中没有可运行的G,M 会尝试从全局队列(GRQ)拿一批G放到P的本地队列,
- 若全局队列也未找到可运行的G时候,M会随机从其他 P 的本地队列偷一半放到自己 P 的本地队列。
- 拿到可运行的G之后,M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
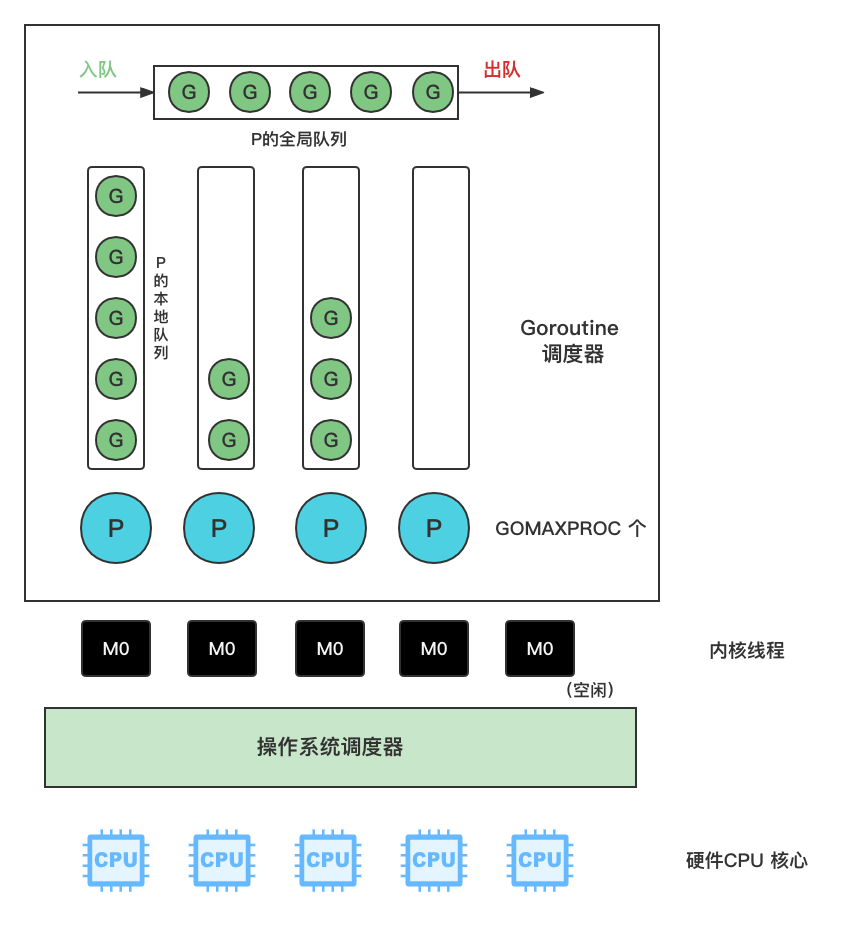
全局队列(Global Queue):存放等待运行的 Goroutine。
Goroutine 在创建后,优先放进本地队列中,本地队列满了之后(本地队列一般大小256),则会把本地队列中一半的G放入全局队列中。
Processer 是可以指定个数,一般可以在程序中使用
runtime.GOMAXPROCS()来设置。Machine(Thread) 线程想运行任务就得获取P,从P的本地队列获取G,P队列为空的时,M也会尝试从全局队列中获取一批G放入到P的本地队列中,或者从其他的P本地队列中偷一半放入到自己的P的本地队列中。
M 与 P 个数的问题
P 的个数问题:由启动时环境变量 $GOMAXPROCS 或者由 runtime 的方法 GOMAXPROCS() 决定。这意味着程序在任意时刻最大同时会有 $GOMAXPROCS 个 goroutine 同时运行。
M的个数问题:go 语言本身限制,go在程序启动时,会设置M的最大数量,默认限制最大是 10000个,但实际内核很难支持这么多的线程数,可以再 runtime/debug 包中使用 SetMaxThreads() 函数来设置最大数。有一个M阻塞会创建一个新的M
M 与 P 的关系?
M 与 P 的数量没有绝对关系,一个 M 阻塞,P 就会去创建或者切换另一个 M,所以,即使 P 的默认数量是 1,也有可能会创建很多个 M 出来。
M 与 P 何时被创建?
P 在运行时系统会根据事先设定的数量而被创建。
M 在没有足够的 M 开关联 P 并运行其中可运行的G时,比如所有的M 都发生了阻塞,而 P 中还有很多就绪任务,就会寻找空闲的M,没有空闲的M就会创建新的 M
G 与 M 的关系
在 GMP 模型中,经常有听到 N:1 、N:M、1:1 的说法
- N:1: N 个协程绑定 1个线程,优点是协程在用户态线程内完成切换,不会陷入到内核态,切换快速。缺点是用不了硬件的多核加速,另外一旦某一个协程阻塞,会导致线程阻塞,其他协程都无法执行。
- 1:1 即一个协程绑定一个线程,缺点比较明显。协程的创建、删除和切换都由CPU完成,过于昂贵。和普通的线程模型就没区别了。
- M:N: M个协程绑定N个线程,是
N:1和1:1类型的结合。这对协程调度器要求高,效率越高。
调度器的设计策略
- 复用线程:避免频繁的创建、销毁线程,尽量复用。
1)work stealing 机制
当本线程无可运行的G时,尝试从其他的线程绑定的P偷取G,而不是销毁线程。
2)hand off 机制
当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程去执行,阻塞的协程会留在阻塞的线程之上。阻塞的协程退出阻塞状态后,会重新加入P本地队列。
利用并行:通过 GOMAXPROCS 限定P的个数,可以充分利用CPU。
抢占式:在 coroutine 中要等待一个协程主动让出 CPU 才执行下一个协程,在 Go (高版本)中,一个 goroutine 最多占用 CPU 10ms,防止其他 goroutine 被饿死,这就是 goroutine 不同于 coroutine 的一个地方。
全局G队列:在新的调度器中依然有全局G队列,当M执行 work stealing 从其他P偷不到G时,他可以从全局G队列中获取G
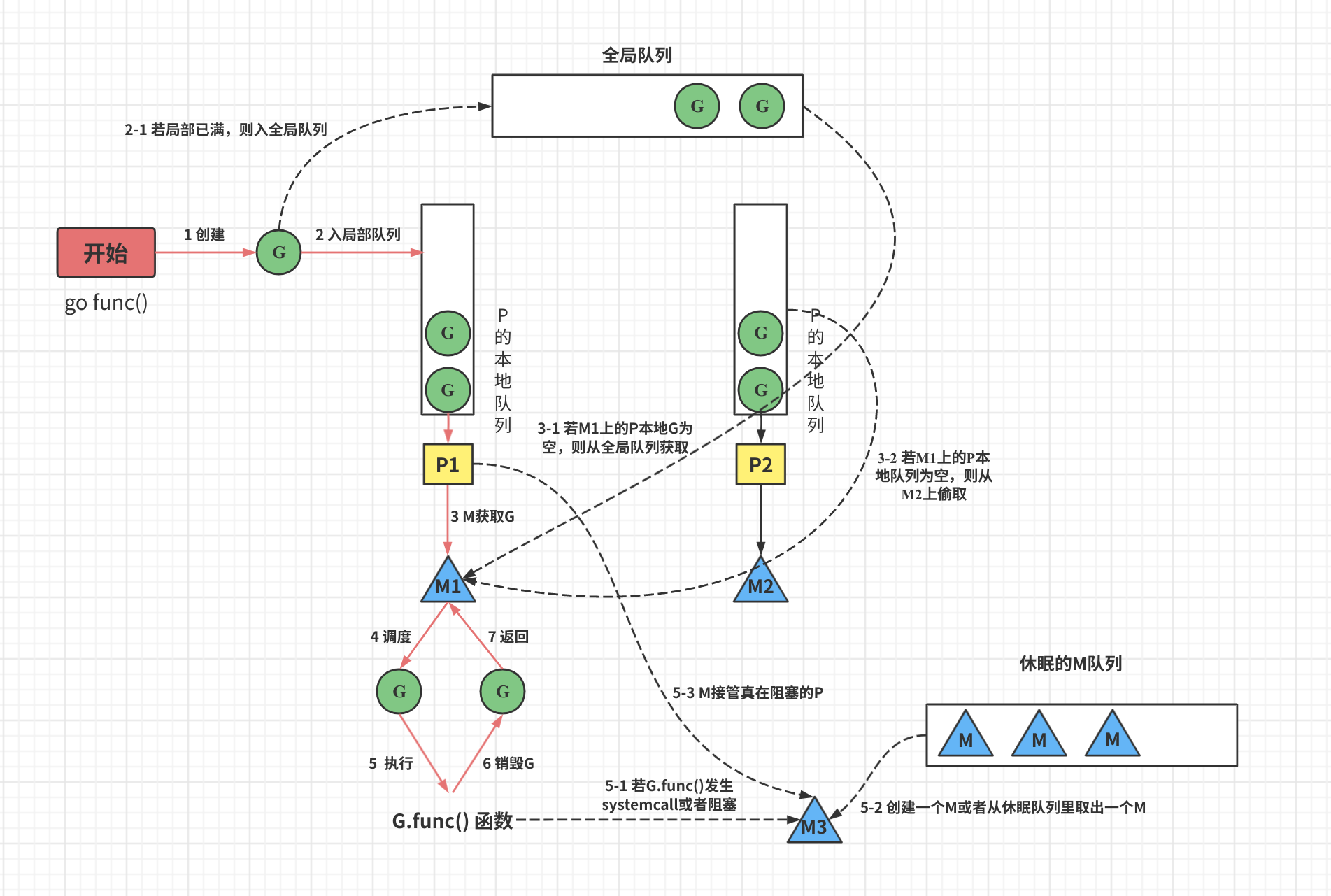
1、通过 go func() 来创建一个 goroutine;
2、有两个存储 G 的队列,一个是局部调度器P维护的本地队列,一个是全局G队列,新创建的G会先保存P的本地队列,如果本地队列满了,会存放到全局队列中;
3、G只能运行在M中,一个M必须持有一个P,M会从P的本地队列中弹出一个可执行的G,如果P的本地队列为空,就会从全局队列或者其他MP组合中偷取一个可执行的G来执行;
4、一个M调度G的过程中是一个循环机制;
5、当M执行的G发生阻塞操作或者发生了系统调用,M就会阻塞,如果当前还有要执行的G, runtime 会把这个线程M从P摘除,然后再创建一个新的操作系统线程(如果有空闲线程就复用空闲线程)来服务这个P;
6、当M系统调用(或阻塞)结束时,这个G会尝试获取一个空闲的P执行,并放入到这个P的本地队列,如果获取不到P,那么这个G加入到全局G里,这个M会加入到空闲线程列表中;
调度器生命周期
要想理解调度器的生命周期,必须得知道 M0 和 G0这两个概念。
- M0
M0 是启动程序后的编号为0的主线程,这个M对应的实例会在全局变量 runtime.m0中,M0 负责执行初始化操作和启动第一个G,在之后的M0就和其他的 M 一样了。
- G0
G0 是每次启动一个 M 都会创建的第一个 goroutine, G0 仅用于负责调度的G,G0 不指向任何可执行的函数,每个M都会有一个 G0.在调度或系统调用时都会使用G0 的栈空间,全局变量的 G0 是 M0 的 G0 。
可视化 GMP 过程
func main() {
//创建trace文件
f, err := os.Create("trace.out")
if err != nil {
panic(err)
}
defer f.Close()
//启动trace goroutine
err = trace.Start(f)
if err != nil {
panic(err)
}
defer trace.Stop()
//main
fmt.Println("Hello World")
}运行程序
$ go run main.go
Hello World运行结束之后,得到一个 trace.out 文件,然后用工具打开
$ go tool trace trace.out
2022/03/27 21:51:23 Parsing trace...
2022/03/27 21:51:23 Splitting trace...
2022/03/27 21:51:23 Opening browser. Trace viewer is listening on http://127.0.0.1:61794通过浏览器打开 http://127.0.0.1:61794 网址,点击 view trace 。

点击 Goroutine 可视化的数据条,可以看到一些详细的信息。一共有两个G在运行,一个是特殊的G0,是每个M必须有的一个初始化的G,还有一个G1 是 main goroutine 在一段时间内处于可运行和运行的状态。
具体场景
场景一:创建G
一个协程内创建另一个协程,新协程优先在原本协程的本地队列中(局部性)
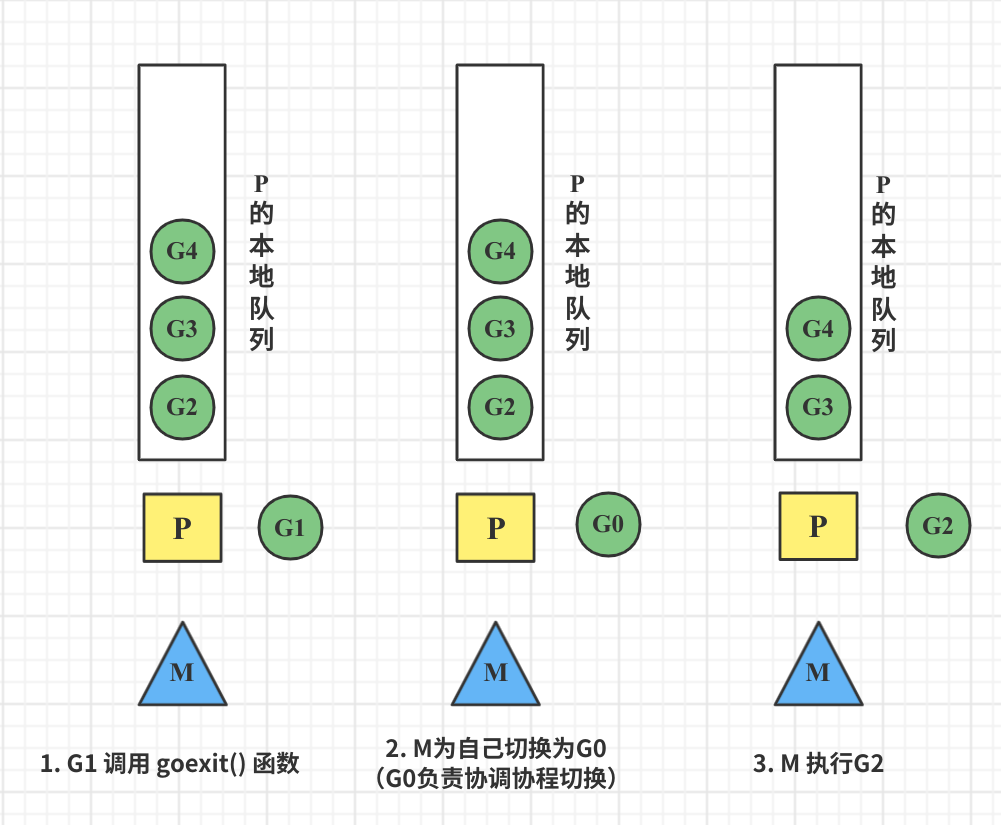
场景二:G执行完毕
协程G1运行完成后(函数 goexit),M上运行的 goroutine 切换 G0 ,G0 负责调度协程的切换(函数:schedule)。从P的本地队列取 G2 ,从G0 切换到 G2,并开始运行 G2 协程(函数:execute)。实现了线程 M1 的复用。
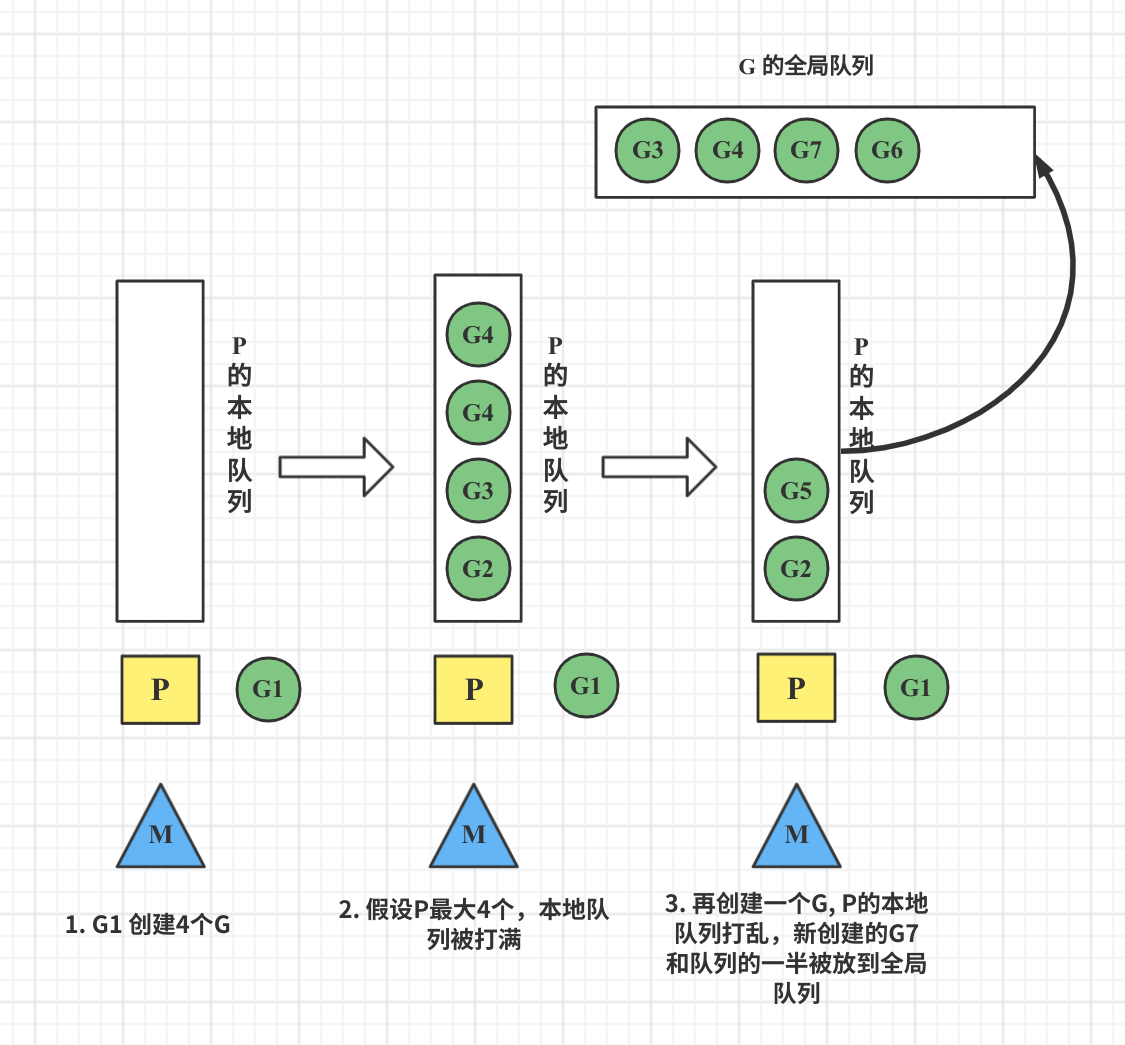
场景三:连续创建多个G导致本地队列满
当一个 Goroutine 中创建了大量的 G 时,会将本地的队列 P 打满,这时需要执行负载均衡策略,会将当前 P1 中的本地队列里的G顺序打乱,并将其P中当前一半的G,还有新创建的G转移到全局队列。
场景四:唤醒正在休眠的M
在创建 G 时,运行的 G 会尝试唤醒其他空闲的 P 和 M 组合去执行。假定 G2 唤醒了 M2,M2 绑定了 P2,并运行 G0,但 P2 本地队列没有 G,M2 此时为自旋线程(没有 G 但为运行状态的线程,不断寻找 G)。
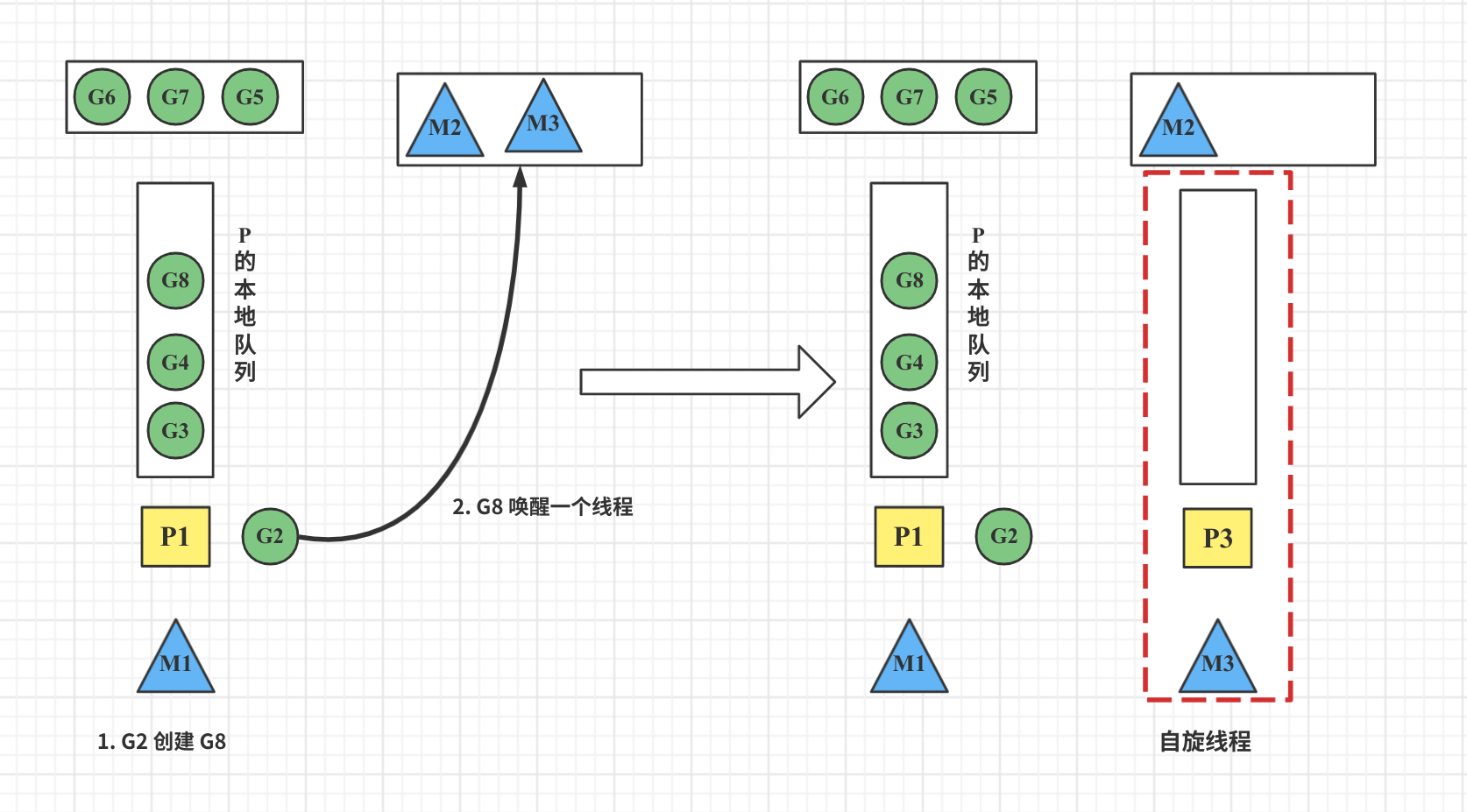
场景五:被唤醒的M从全局获取G
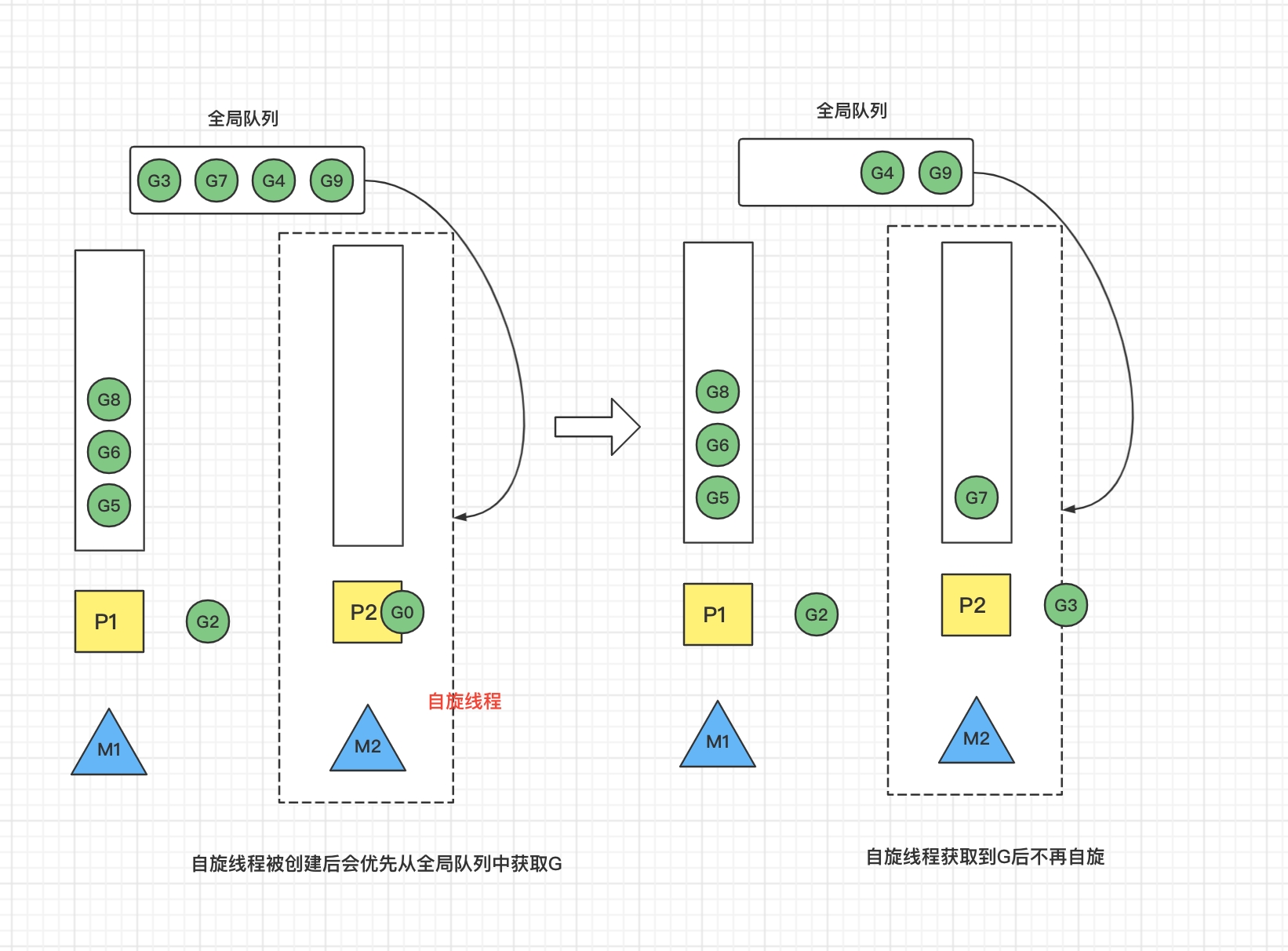
M2 尝试从全局队列 取一批 G 放到 P2 的本地队列(函数:findrunnable())。M2 从全局队列取的 G 数量符合下面的公式:
n = min(len(GQ)/GOMAXPROCS + 1, len(GQ/2))假定我们场景中一共有 4 个 P(GOMAXPROCS 设置为 4,那么我们允许最多就能用 4 个 P 来供 M 使用)。所以 M2 只从能从全局队列取 1 个 G3 移动 P2 本地队列,然后完成从 G0 到 G3 的切换,运行 G3。此时这个线程退出自旋状态。
场景六:偷取G情况
假设 G2 一直在 M1 上运行,经过 2 轮后,M2 已经把 G7、G4 G9 从全局队列获取到了 P2 的本地队列并完成运行,全局队列和 P2 的本地队列都空了。此时全局队列中没有G,那么M2就需要开始 working stealing (偷取),从其他有G的P拿一半G过来,放到自己的P本地队列里。
场景七: 自旋线程的最大限制
假设 M1 和 M2 都在正常运行 G,M3 和 M4 没有goroutine 可以运行,那么 M3 和 M4 处于 自旋状态,他们会不断的寻找 goroutine。
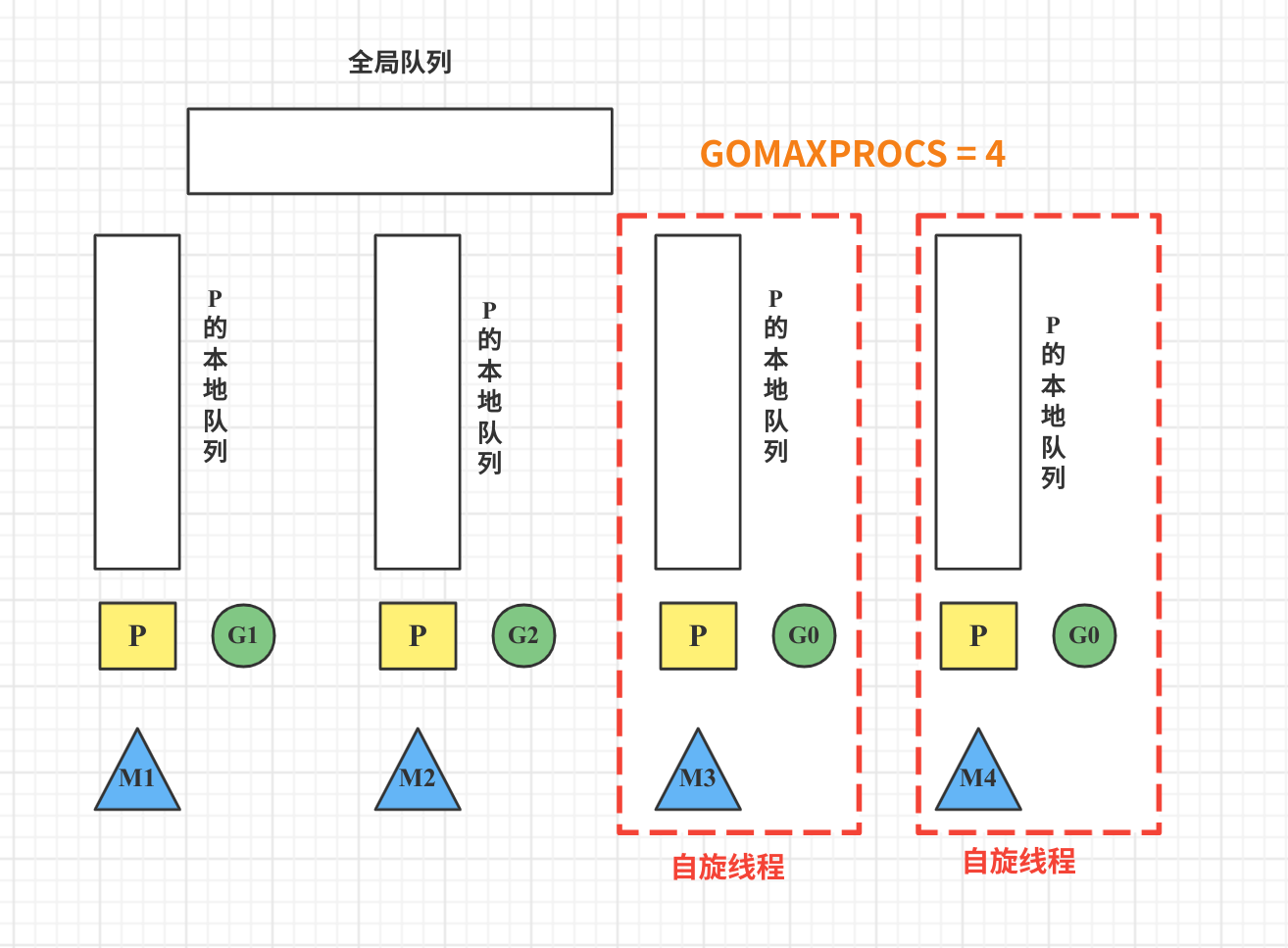
为什么要让 m3 和 m4 自旋,自旋本质是在运行,线程在运行却没有执行 G,就变成了浪费 CPU. 为什么不销毁现场,来节约 CPU 资源。因为创建和销毁 CPU 也会浪费时间,我们希望当有新 goroutine 创建时,立刻能有 M 运行它,如果销毁再新建就增加了时延,降低了效率。当然也考虑了过多的自旋线程是浪费 CPU,所以系统中最多有 GOMAXPROCS 个自旋的线程,多余的没事做线程会让他们休眠。
场景八:G发生阻塞系统调用
假设在 N:M 模型中,假设 M3 处于自旋,还有休眠队列中的 M4 。此时 M1 上的 G4 创建一个 G5 并且 G4 进行了 阻塞的系统调用 ,M1和P1 立即解绑,如果P1 上有空闲的P列表,P1会立刻唤醒一个M和他绑定。否则P1会加入到空闲的P列表,等待M来获取可用的P。
场景九:G发生非阻塞系统调用
上述场景,假设 G4 创建 G5 进行的是非阻塞系统的调用,此时的M1和P1解绑,但是M1会记住P1,然后G4进入系统调用的状态(但是是非阻塞的),当G4 和 M1 退出系统调用时,会尝试获取P1,如果无法获取,则获取空闲的P,如果依然没有,则4 会被标记为可运行状态,加入到全局队列。M1会因为没有P的绑定变为可休眠状态。
参考: