eBPF超乎你想象
eBPF是一种起源于Linux内核的革命性技术
eBPF 是什么?

在过去,如果想让应用程序处理网络数据包是不可能的,因为应用程序运行在Linux的用户空间,它是不能直接访问主机的网络缓冲区,这里由内核管理和保护。内核保证了进程隔离,进程只能通过系统调用(syscall)来获取自己的网络数据包信息。
1992 年的 USENIX 会议上,The BSD Packet Filter: A New Architecture for User-level Packet Capture ,第一次提到 BSD Packet Filter (简称BPF)这个概念,这篇论文带来了一个革命性技术。正如其名称他是包过滤相关的技术,其基本原理是用户态定义 BPF 字节码来定义过滤表达式,然后传递给内核,再由虚拟机解释运行。
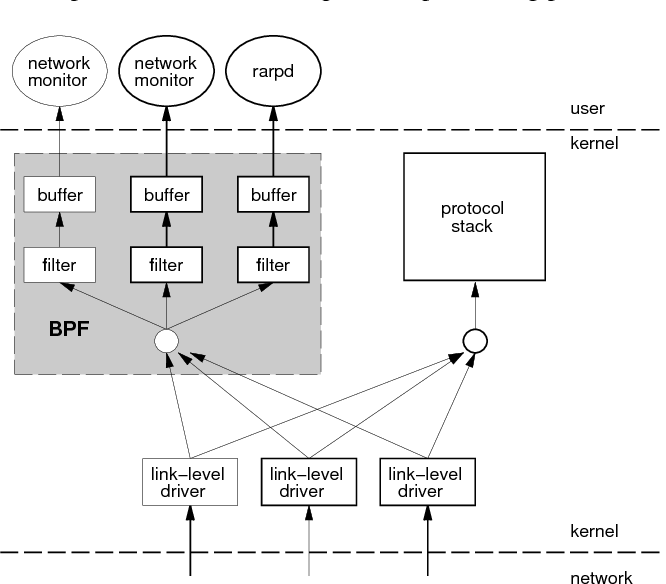
有了 BPF 之后,应用程序不再需要 syscall,数据包不需要在内核空间和用户空间之间来回交互传递。而是我们将代码直接交给内核,让内核自己执行,这样就可以让代码全速运行,效率更高。
我们使用的 tcpdump 主要通过 libpcap 实现,而libpcap 就是基于 eBPF 。执行下面的命令,导出 tcpdump 所灌入内核的 BPF 程序。如下的 tcpdump 命令,可以直接过滤出IP地址包含 1.1.1.1 和 2.2.2.2 的数据包。
tcpdump -d 'ip src 1.1.1.1 or ip src 2.2.2.2'
(000) ldh [12] # 找到以太网类型字段
(001) jeq #0x800 jt 2 jf 6 # 判断是否为以太网
(002) ld [26] # 判断IP头部
(003) jeq #0x1010101 jt 5 jf 4
(004) jeq #0x2020202 jt 5 jf 6
(005) ret #262144
(006) ret #0
| |
Linux 利用 socketopt 中的 SO_ATTACH_FILTER、SO_DETACH_FILTER 来执行系统调用,具体可参考 socket manual page。
在2013年,为了研究新的 SDN 方案,Alexei Starovoitov 为 BPF 做了一次革命性的更新,将 BPF 扩展为一个通用的虚拟机,也就是eBPF (extended Berkeley Packet Filter)。eBPF 不仅扩展了寄存器的数量,还在 4.x 内核中将原本单一的数据包过滤事件逐步动态扩展到内核态函数、用户态函数、跟踪点、性能事件(perf_events)以及安全控制领域。
eBPF 使得BPF不再局限于网络栈,而是成为内核的一个顶级系统。
在内核社区的开发讨论中,通常还是使用BPF这个缩略词,而很多文档中也更倾向于使用 eBPF,但其实他们的含义是一样的,还有一种 cBPF(classic BPF)的叫法,这个是为了区别 eBPF 和 cBPF ,不过当前 cBPF 已经基本废弃,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码透明的转换成 eBPF 再执行。
随着内核版本的发展,eBPF 迎来了蓬勃的发展,由于 eBPF 无需修改内核源码和重新编译内核就可以扩展内核的功能,Cilium、Katran、Falco 等一系列基于 eBPF 优化网络和安全的开源软件项目也逐渐诞生。
应用场景有哪些?
eBPF 程序类型决定一个 eBPF 程序可以挂载的事件类型和事件参数,这意味着,内核中不同事件会触发不同类型的 eBPF 程序。
$ sudo bpftool feature probe | grep program_type
eBPF program_type socket_filter is available
eBPF program_type kprobe is available
eBPF program_type sched_cls is available
eBPF program_type sched_act is available
eBPF program_type tracepoint is available
eBPF program_type xdp is available
eBPF program_type perf_event is available
eBPF program_type cgroup_skb is available
eBPF program_type cgroup_sock is available
eBPF program_type lwt_in is available
eBPF program_type lwt_out is available
...
根据具体功能和应用场景的不同,这些应用程序大概分为三类:跟踪类、网络类、其他类型。
跟踪类 eBPF 程序
跟踪类 eBPF 程序主要用于系统提取跟踪信息,进而为监控、追踪、性能优化等提供数据支撑。这类eBPF 程序的类型包含 BPF_PROG_TYPE_KPROBE 、 BPF_PROG_TYPE_TRACEPOINT、BPF_PROG_PERF_EVENT、BPF_PROG_TYPE_RAW_TRACEPOINT、BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE、BPF_PROG_TYPE_TRACING。
BCC 工具集就属于这类。
apt install bcc-tools
网络类 eBPF 程序
网络类 eBPF 程序对网络数据包进行过滤和处理,进而实现网络观测、过滤、流量控制以及性能优化各种丰富的功能。
- XDP 程序
XDP (eXpress Data Path,高速数据路径) 程序的类型定义为 BPF_PROG_TYPE_XDP ,他在网络驱动程序刚收到数据包时触发执行,由于无需经过复杂的内核网络协议栈,XDP 程序可以用来实现高性能的网络处理方案,常用于 DDos 防御,防火墙,4层负载均衡等场景。
XDP 程序在处理网络数据包之后,需要根据 eBPF 程序执行结果,决定数据包的去处。
https://www.iovisor.org/technology/xdp
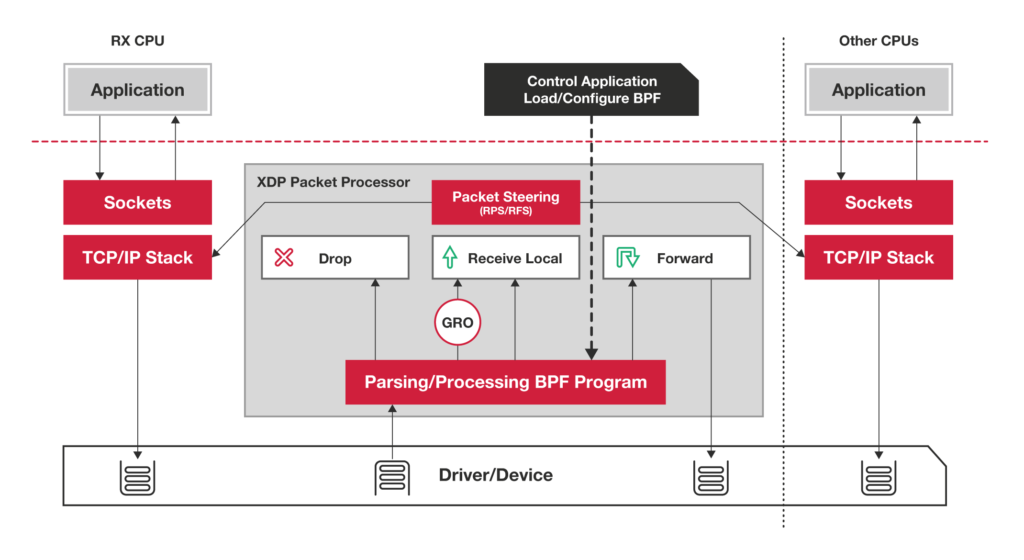
一般生产环境中的 XDP 程序运行过程是需要网卡驱动支持,甚至卸载模式的XDP 程序运行在特定的网卡固件上,不再消耗主机的CPU资源。
通常来说,XDP 程序通过 ip link 命令加载到具体的网卡上,加载格式为:
| |
或者通过 BCC 提供的库函数,在一套代码中管理整个 XDP 的生命周期。
- TC 程序
TC 程序的类型定义为 BPF_PROG_TYPE_SCHED_CLS 和 BPF_PROG_TYPE_SCHED_ACT ,分别作为 Linux 流量控制的分类器和执行器。Linux 流量控制通过网卡队列、排队规则、分类器、过滤器以及执行器实现了对网络流量的整形调度和带宽控制。
TC 原理介绍:TC 流量控制
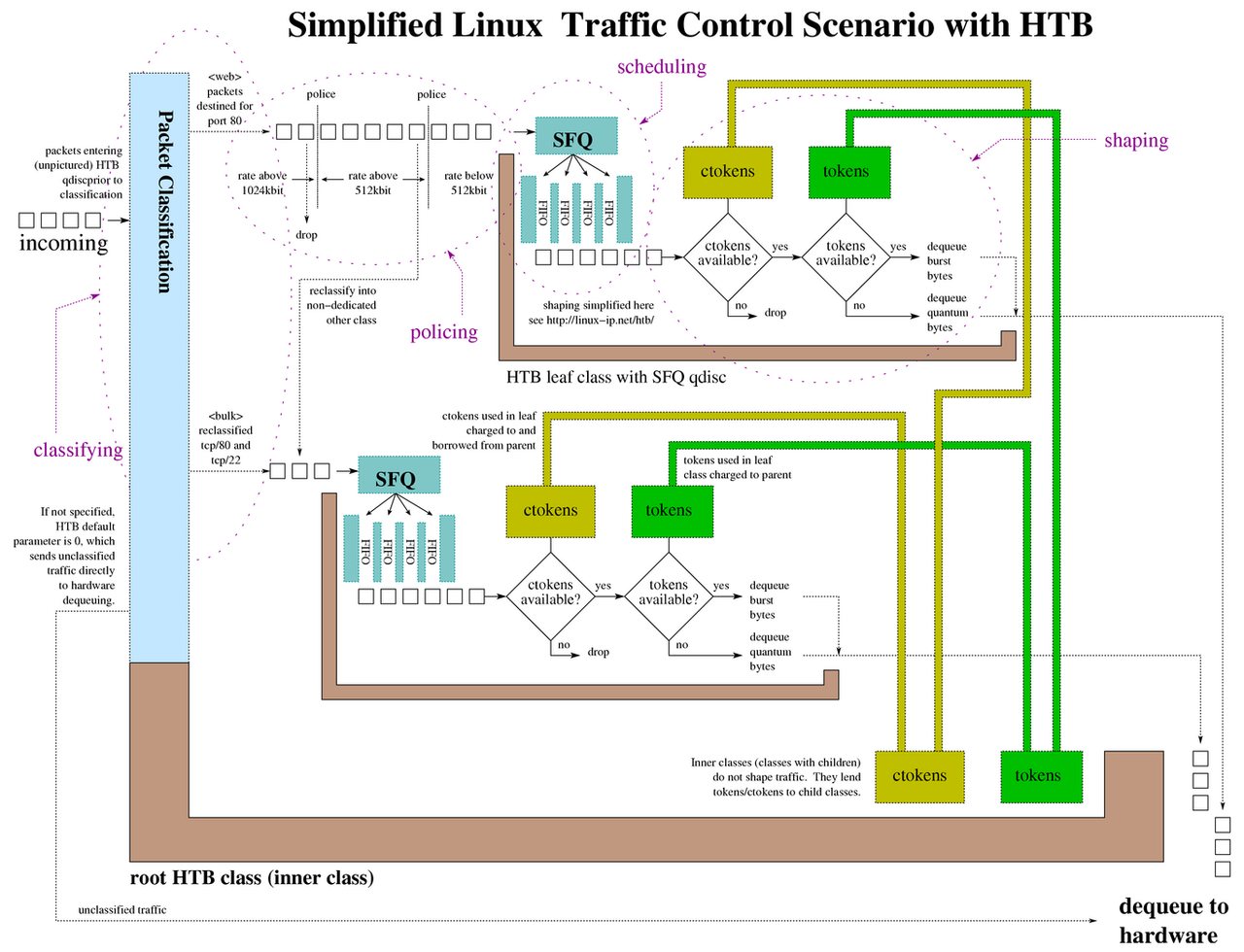
http://linux-ip.net/articles/Traffic-Control-HOWTO/
对于接收的网络包,TC 程序在网卡接收之后,协议栈处理(包括IP层处理和iptables等)之前执行;
对于发送的网络包,TC 程序在协议栈处理(包括IP层处理和iptables等)之后、数据发送到网卡队列之前执行。
Kernel 4.1 引入了一个特殊的 qdisc,叫做 clsact。它为TC提供了一个可以加载BPF程序的入口。kernel 4.4 时,iproute2 引入了 direct-action 模式。传统的 TC 使用需要 filter 和 action 两个 module。但是因为 bpf 本身的功能比较丰富,可以将二者合二为一。
| |
套接字程序
套接字程序用于过滤、观测或重定向套接字网络包,如上介绍的 tcpdump 实现等。
其他类 eBPF 程序
其他类型的 eBPF 程序包括不常使用的 LWT 轻量级隧道实现类的
eBPF program_type lwt_in is available
eBPF program_type lwt_out is available
eBPF program_type lwt_xmit is available
Linux 安全审计策略相关的 LSM
eBPF program_type lsm is NOT available
| 项目 | 类别 | 说明 |
|---|---|---|
| Katran | 网络四层负载均衡 | Facebook 开源的高性能 4层负载均衡器。Katran 是一个 C++ 库和eBPF 程序,用于建立一个高性能的四层负载均衡转发平台,利用XDP基础设施,在网络包没有进入Linux 内核buffer队列时就进行了过滤和修改 |
| Cilium | 网络\安全\观测 | Isovalent 开源项目,提供由 eBPF 驱动的网络、安全和可观测性。Cilium 作为一款 Kubernetes CNI 插件,从一开始就是为大规模和高度动态的容器环境而设计,并且带来了 API 级别感知的网络安全管理功能。最Cool Kubernetes网络方案Cilium入门 |
| Calico | 网络 | 流行的 Kubernets 网络插件,基于 eBPF 实现了高性能数据平面 |
| Bymblebee | 调度 | 基于 OCI 镜像构建,运行和分发 eBPF 程序的项目。支持自动将数据导出为指标和日志 |
| kubectl-trace | 调度 | 将 bpftrace 程序调度到kubernetes集群的kubectl插件,简化了bpftrace 程序的管理 |
| KubeArmor | 安全 | 容器运行时安全监测和策略执行项目,底层会把安全策略应用到LSM,从而限制容器内的可疑行为。 |
| Falco | 安全 | Sysdig 开源的运行时安全监控项目,可根据预定的安全规则进行告警 |
eBPF 软件开发
eBPF 运行原理
eBPF 是一个运行在内核中的虚拟机,提供了一种可以在内核中运行“沙盒”程序的能力。可以用来安全、高效地扩展内核的能力而无需修改内核源代码或加载内核模块。
eBPF程序是事件驱动的,当内核运行到特定hook点时会触发执行。预定义的hook点包括系统调用、函数进入/退出、内核tracepoints、网络事件等等。如果预定义的hook点不存在,还可以通过创建kprobe和uprobe的方式挂载eBPF程序。
eBPF 在内核运行时主要由 5 个模块组成:

eBPF 辅助函数 :提供一系列用于 eBPF 程序与内核模块交互的函数
eBPF 验证器 :用于保证 eBPF 程序的安全,验证器会保证程序不包含不可达指令,不会执行无效指令
寄存器、程序计数器、512 Byte 栈:寄存器用于存储函数调用和 eBPF 程序返回值和函数入参。
即时编译器:将 eBPF 字节码编译成本地的机器指令
BPF 映射:用于提供大块存储,这些存储可被用户空间程序访问
BCC \ bpftrace \ libbpf
- BCC
BCC工具全称 BPF Compiler Collection (BCC)(https://github.com/iovisor/bcc),是 eBPF 的一种前端。可以直接在 python/Go/Lua/Rust等语言嵌入 C 语言写的 BPF 程序,并帮忙产生 BPF bytecode 和 load 进入 kernel 挂载 kprobe、tracepoints 等上面执行。利用这个库可以从底层获取操作系统性能信息,网络性能信息等许多与内核交互的信息。
BCC **通常用在开发复杂的 eBPF 程序中,其内置的各种小工具也是目前应用最为广泛的 eBPF 小程序。**不过,BCC 也不是完美的,它依赖于 LLVM 和内核头文件才可以动态编译和加载 eBPF 程序。
- bpftrace
bpftrace是Linux中基于eBPF的高级追踪语言,使用LLVM作为后端来编译eBPF字节码脚本,并使用BCC与Linux BPF系统交互。它允许开发者用简洁的DSL(Domain Specific Language)编写eBPF程序,并将它们保存为脚本,开发者可以执行这些脚本,而不必在内核中手动编译和加载它们。
bpftrace 通常用在快速排查和定位系统上,它支持用单行脚本的方式来快速开发并执行一个 eBPF 程序。
- libbpf
libbpf 是从内核中抽离出来的标准库,用它开发的 eBPF 程序可以直接分发执行,这样就不需要每台机器都安装 LLVM 和内核头文件了。不过,它要求内核开启 BTF 特性,需要非常新的发行版才会默认开启(如 RHEL 8.2+ 和 Ubuntu 20.10+ 等)。
追踪原理
探针是用于捕获事件数据的检测点,eBPF在实现追踪时使用的探针主要包括,内核静态探针(Tracepoints),内核动态探针(Kprobes),用户静态探针(USTD),用户动态探针(uprobes)
内核静态探针:tracepoints
tracepoints是内核开发人员在内核代码中的埋点,是开发者在内核源代码中散落的一些hook,开发者可以依托这些hook实现相应的追踪代码插入。通常比较稳定:能够保证不同内核版本间的兼容性。
tracepoint如何编写:
tracepoint definition:sched.h - include/trace/events/sched.h - Linux source code (v5.12.6) - Bootlin
The tracepoint statement:exec.c - fs/exec.c - Linux source code (v5.12.6) - Bootlin
| |
Example:
bpftrace -e ‘tracepoint:syscalls:sys_enter_openat { printf("%s %s\n”, comm, str(args->filename)); }’
Example:
| |
args是一个指针,指向该tracepoint的参数。这个结构时由bpftrace根据tracepoint信息自动生成的。
可以用 bpftrace -lv tracepoint:syscalls:sys_enter_openat 查看
更多内建函数参考:https://www.brendangregg.com/BPF/bpftrace-cheat-sheet.html
内核动态探针: kprobe & kretprobe
kprobes允许开发者在几乎所有的内核指令中以最小的开销设置动态的标记或中断。通过kprobes,你可以动态在内核函数执行前设置断点,甚至几乎可以在任何内核代码地址处设置断点,并且指定在断点被执行时要执行的处理函数。kprobe生效原理:
创建并设置kprobe回调函数,调用时触发bpf程序执行。
把目标地址替换成breakpoint指令(e.g., int3 on i386 and x86_64).
当程序指令执行到breakpoint指令时,执行kprobe handler
bpf指令被执行,执行完成后返回到原来的目标地址。
当unload kprobe时把目标地址恢复到原状。
eBPF 与网络
网络层面eBPF能做的事情从网卡(如卸载到硬件网卡中的 XDP 程序)到网卡队列(如 TC 程序)、封装路由(如轻量级隧道程序)、TCP 拥塞控制、套接字(如 sockops 程序)等内核协议栈,再到同属于一个 cgroup 的一组进程的网络过滤和控制,甚至到用户态上层网络协议。
内核网络:
如对 Linux 网络丢包问题来说,释放最核心的 SKB(Socket Buffer)数据结构是问题切入点。查询内核 SKB 文档,你可以发现,内核中释放 SKB 相关的函数有两个:
第一个,kfree_skb ,它经常在网络异常丢包时调用;
第二个,consume_skb ,它在正常网络连接完成时调用。
https://github.com/feiskyer/ebpf-apps/blob/main/bpftrace/dropwatch.bt
TCP 追踪:
tools/tcpaccept: 跟踪TCP被动连接 (accept()).
tools/tcpconnect: 跟踪TCP主动的连接 (connect()).
tools/tcpconnlat: 跟踪TCP主动连接的延迟(connect()).
tools/tcpdrop: 跟踪内核的TCP包的丢包细节.
tools/tcplife: 跟踪TCP session(生命周期指标汇总).
tools/tcpretrans: 跟踪TCP重传.
tools/tcprtt: 跟踪TCP来回的耗时.
tools/tcpstates: 跟踪TCP session状态的改变.
tools/tcpsubnet: 按子网汇总和聚合TCP发送情况.
tools/tcpsynbl: 显示TCP SYN backlog的情况.
tools/tcptop: 按主机汇总TCP send/recv吞吐情况.
tools/tcptracer: 跟踪TCP 建立/关闭连接的情况 (connect(), accept(), close()).
tools/tcpcong: 跟踪TCP套接字拥塞控制状态持续时间.
openssl 加解密
代码地址:https://github.com/kiosk404/openssl_tracer
追踪 OpenSSL 加解密:
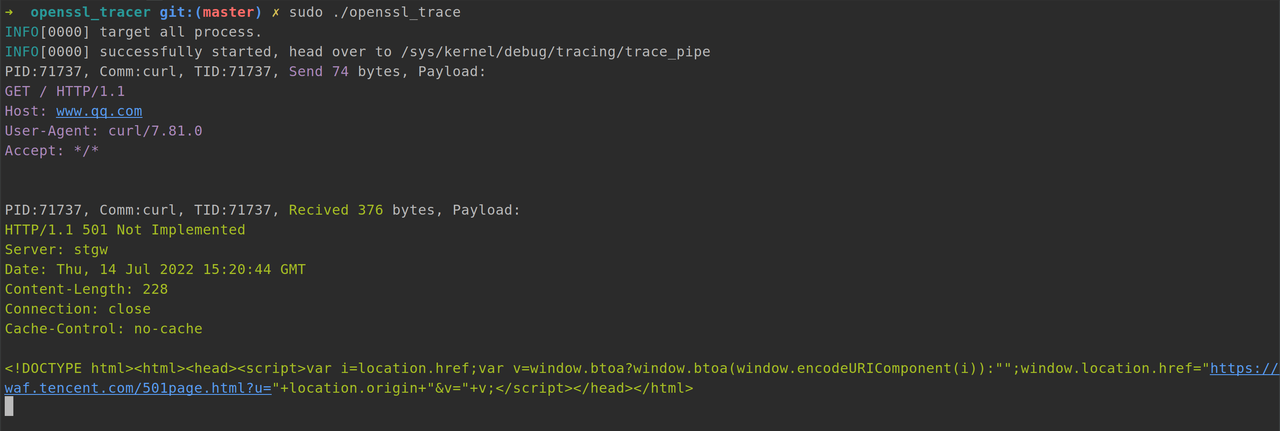
移动端网络:
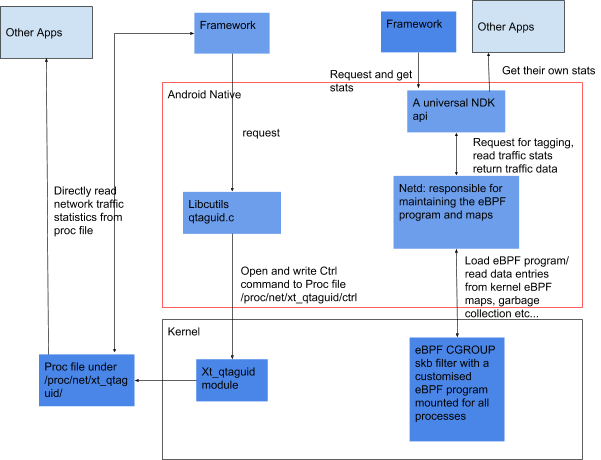
eBPF 网络流量工具可结合使用内核与用户空间实现来监控设备自上次启动以来的网络使用情况,它提供了额外的功能(如套接字标记、分离前台/后台流量,以及按 UID 划分的防火墙),以根据手机状态阻止应用访问网络。从该工具收集的统计数据存储在称为 eBPF maps 的内核数据结构中,并且相应结果由 NetworkStatsService 等服务用来提供自设备上次启动以来的持久流量统计数据。
eBPF 和 Golang
![]()
编程语言本身会对 eBPF 追踪造成影响。按照其运行原理大致可分为三类:
第一类是 C、C++、Golang 等编译为机器码后再执行的编译型语言。这类编程语言开发的程序,通常会编译成 ELF 格式的二进制文件,包含了保存在寄存器或栈中的函数参数和返回值,因而可以直接通过二进制文件中的符号进行跟踪。
第二类是 Python、Bash、Ruby 等通过解释器语法分析之后再执行的解释型语言。这类编程语言开发的程序,无法直接从语言运行时的二进制文件中获取应用程序的调试信息,通常需要跟踪解释器的函数,再从其参数中获取应用程序的运行细节。
第三类类是 Java、.Net、JavaScript 等先编译为字节码,再由即时编译器(JIT)编译为机器码执行的即时编译型语言。同解释型语言类似,这类编程语言无法直接从语言运行时的二进制文件中获取应用程序的调试信息。跟踪 JIT 编程语言开发的程序是最困难的,因为 JIT 编译的状态只存在于内存中。
幸运的是 Golang 这种编译型语言是追踪起来最方便的。
在跟踪内核的状态之前,需要利用内核提供的调试信息查询内核函数、内核跟踪点以及性能事件等。
类似地,在跟踪应用进程之前,也需要知道这个进程所对应的二进制文件中提供了哪些可用的跟踪点。
| |
一个简单的追踪过程:
| |
使用 bpftrace 查看可跟踪列表:
| |
追踪:
| |
默认函数参数保存在栈上,通过 sarg0 到 sargx,以此取到函数入参。 从 go.1.17 开始,参数不再保存在栈里,而是保存在寄存器中,关于这一点在 Go internal ABI specification 中有详细的描述:
amd64 architecture The amd64 architecture uses the following sequence of 9 registers for integer arguments and results: RAX, RBX, RCX, RDI, RSI, R8, R9, R10, R11
但是 bpftrace 也有相应的缺陷。
复杂类型(用户自定义结构体/指针/引用/通道接口等)在 golang 中目前无法追踪,但是 C 语言就不一样了,结构体搬过来即可。golang 中比较适用的场景在函数的调用次数,函数延迟,函数返回值等;
基于 uprobe 需要被跟踪的程序带有符号表(not stripped),且 eBPF 需要特权用户,一般场景下都会限制适用范围。
跟踪调用栈
如下所示:
| |
不过跟踪 Golang 代码时经常会导致程序崩溃,尤其是有多协程场景下。
在 Github Golang 的官方项目的 issue 里可以看到相关的解释。

Golang 进程在 GC 和调度的时候是栈地址是会变化的,而 BPF 在使用 uretporbe 的时候需要提前指定好符号表中的栈地址,这时候就会导致进程崩溃了。目前看在 golang 下是无解的。
修改对应参数。
通过内核源码中,我们可以看到,BPF 辅助函数中有 bpf_probe_write_user 函数,可支持修改内核空间或用户空间的地址,这些函数会进行安全性检查,并禁止缺页中断。

eBPF 程序并不能随意调用内核函数(部分TCP 拥塞控制的内核函数已经支持直接调用),因此,内核定义了一系列的辅助函数,用于 eBPF 程序与内核其他模块进行交互。
可以使用
bpftool feature probe查询当前系统支持的辅助函数列表。
eBPF 代码:
| |
被修改的代码:
| |
执行后效果(该代码需要在 go1.17 以下版本运行):
正常情况下,上述代码运行结果 ebpfDemo 的第一个入参应该是 100,但是执行 ebpf 程序后,demo 执行的 第一个入参是 2022
| |
Golang eBPF 开发
BCC、libbpf 以及内核源码,都主要使用 C 语言开发 eBPF 程序,而实际的应用程序可能会以多种多样的编程语言进行开发。所以,开源社区也开发和维护了很多不同语言的接口,方便这些高级语言跟 eBPF 系统进行交互。这里的 Go 开发库只负责用户态程序,完成 eBPF 程序的编译、加载、事件挂载、以及 BPF 映射的交互。内核态的 eBPF 程序必须是 C 语言开发。
| Go 开发库 | 使用说明 | 依赖环境 |
|---|---|---|
| cilium/ebpf | Cilium 和 Cloudflare 开源的 eBPF 开发库,不依赖外部的其他库,纯 Go 实现 | 内核版本 大于 4.4 |
| iovisor/gobpf | BCC 库的 Go 语言版本,底层依赖 BCC 完成 eBPF 程序的动态编译和加载过程 | 需要安装 BCC 库 libbcc ,并需要 LLVM |
| aquasecurity/libbpfgo | Libbpf 的 go 语言绑定,底层依赖 libbpf 完成 eBPF 程序的管理功能。 | 需要安装 libbpf |
https://www.ebpf.top/post/ebpf_go/
eBPF 的未来战场: Cloud Native
ebpf 官网的 projects 可以看到很多 ebpf 的火热项目都和 Cloud Native 相关

Pixie
https://docs.px.dev/using-pixie/using-live-ui/
有了 Pixie,开发人员可以通过一个 shell 命令查看其所有应用程序的指标、事件、日志和跟踪。使用 Pixie,您无需添加检测代码,设置临时仪表板即可查看正在发生的情况,这将为你节省宝贵的时间。Pixie 是一个本地的 Kubernetes 程序,其 Pixie Edge 模块(PEM)部署为 DaemonSet。
其主要的功能有:
自动监控:一旦部署,pixie 会收集来自各种协议、系统指标和网络级别数据的所有应用请求(包括 ssl加解密、应用程序CPU热力图分析、分布式 bpftrace 脚本、日志动态记录)。其中运用了大量的 ebpf 技术
完全可编写脚本:可以自定义分析。
集群内边缘计算:k8s 内的数据存储和计算

Pixie 提供了动态化日志输出能力。
在传统的系统,如果缺少日志打印、需要重新 修改 -> 编译 -> 部署 。Pixie 允许动态捕获函数参数、返回值和延迟。