docker 容器技术基础
docker 容器是随着PaaS技术的普及随之诞生的,Docker公司推出了docker并通过“容器镜像”解决了容器打包的根本性难题。而容器本身没有价值,有价值的是“容器编排技术”。Docker项目则通过容器技术解决了应用打包的根本性难题。
为什么在开头就放出了 “容器本身没有价值” 的大话呢?
因为容器本身只是一个沙盒技术,其使用Cgroups和Namespace技术创建出来一个隔离环境,而docker项目之所以能得到如此之高的关注也是因为他解决了应用打包和发布这个困扰运维人员的多年的技术难题。能够把应用装到集装箱内方便搬来搬去才是PaaS的最理想状态。
Docker本身所用到的隔离技术也并不是什么黑科技,都是把已有的功能翻出来拼装了一下而已。容器的本质是一个“单进程”模型,本质是一个特殊的进程而已
Docker 容器技术由 Namespace、Cgroups、rootfs 三种技术构建出,其中Namespace、Cgroups 构建了容器的动态视图(称为 运行时),rootfs构建了容器的静态视图。
容器技术
Namespace
Namespace是Linux很早版本就实现的一个系统调用,他可以实现新创建一个进程的时候,为这个进程创建一个沙盒,比如让新的进程以为自己是1号PID进程,或者是让自己以为自己有一个新的网卡等等。
Linux创建新进程的时候有一个可选参数,加上 CLONE_NEWPID 就可以让创建的进程拥有一个全新的进程空间,在宿主机的真实进程空间,其PID还是那个PID,但是新进程自己认为自己是当前空间里的1号进程。他们无法看到真实的进程空间。也无法看到其他Namespace里的进程空间。
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
类似的参数还有
CLONE_NEWNS: 用于指定Mount Namespace (挂载点)CLONE_NEWUTS: 用于指定UTS Namespace (HOSTNAME和DOMAIN)CLONE_NEWIPC: 用于指定IPC Namespace (共享内存、信号量和消息队列)CLONE_NEWPID: 用于指定PID Namespace (进程号)CLONE_NEWNET: 用于指定Network Namespace (网络)CLONE_NEWUSER: 用于指定User Namespace (用户)
用户可以在**/proc/$pid/ns**文件下看到本进程所属的Namespace的文件信息。
比如使用 docker run -it busybox /bin/sh 启动一个容器,然后在另外一个终端看到
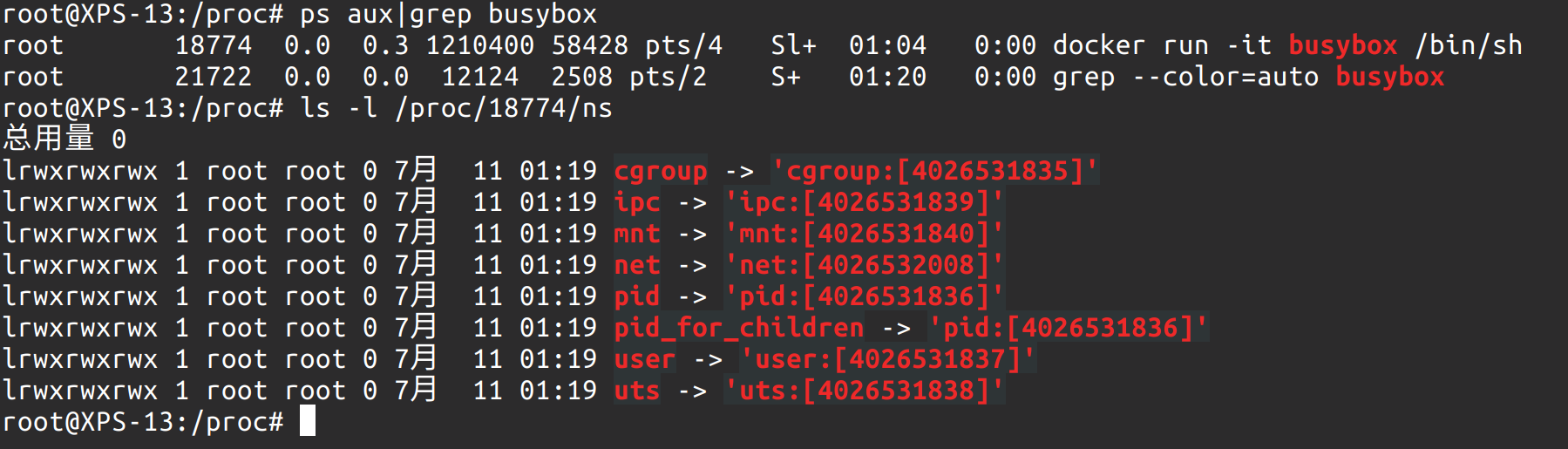
同样,Linux也提供了其他系统调用,可以让其他进程加入到一个Namespace中,int setns(int fd, int nstype);,这也为之后的联盟式容器创造了可能。即多个进程使用相同的Namespace。系统调用int unshare(int flags);也为相同Namespace分家提供了技术支持。
所以,Docker容器这个听起来高端大气的概念,只不过是在创建容器进程时,指定了这个进程一组Namespace参数而已。
比如我们启动了一个容器。可以使用 docker exec -it xxxxx /bin/bash 进入到这个容器中。
| |
每一个进程的所有Linux Namespace,都在/proc/[pid 进程号]/ns 下有一个虚拟文件,并且链接到真实的Namespace上。这样其他进程就可以加入一个已经存在的Namespace中。这也为了之后的pod(联盟式容器)打下基础。如 docker run -it -net container:25836f0da751 busybox ifconfig。这就是起一个容器,但是network namespace 用和 258xx 这个容器用一个。
Namespace的问题
既然容器技术只是一个特殊的进程被隔离而已,那么其缺点就很明显了,那就是容器的**“隔离不彻底”**。
第一,容器既然是运行在宿主机上的一种特殊进程,那么多个进程还是共享同一个操作系统的内核(注意这里是Linux 内核 ,Mac和Windows上的容器首先是运行在Docker Machine上的,说白了运行在Linux虚拟机上)
第二,容器并不是所有资源都可以Namespace化的,典型的不能被Namespace的例子就是:时间
第三,由于避免不了多个容器共享宿主机内核的事实,那么就意味着容器的越狱比虚拟机简单的多了,一些危险的系统调用需要被监管加固
正是上述的问题,Docker的安全性会很差,一般不会直接把Docker暴露在公网上。
Refer:
Cgroups
上面提到容器只是一个特殊的进程而已,那么这个容器进程和宿主机上其他的普通进程是平等的。如果容器进程可以占用宿主机全部资源的话,这显然不符合沙盒技术的特征。而Cgroups则正是 Linux 内核中用来限制资源的功能。
Cgroups 的本质是给进程挂上钩子 (hooks) ,当Task的运行涉及到某个资源的时就触发钩子上所携带的subsystem检测。最终进行资源限制和优先级分配。
Cgroups全称是 Linux Control Group, 他最主要的作用就是限制一个进程组能够使用的资源上限,包括CPU,内存,磁盘,网络带宽等
Cgroups 给用户直接暴露出来的操作接口是文件系统,即以文件和目录的方式组织在操作系统的 /sys/fs/cgroups 路径下,在这个路径下有很多诸如 cpuset、cpu、memory 这样的子目录。这些就是当前操作系统下可以被限制的资源类型。
| |
怎么样去限制一个进程的资源呢?需要在这些目录之下再创建一个目录,如进入 /sys/fs/cgroup/cpu 目录下。创建目录 container 。这样一个目录,操作系统会自动在这个目录下生成子系统对应的资源限制文件。

这下,我们创建一个死循环,将CPU吃满,记录该进程的PID。向 container 组里的 cfs_quota 文件写入 2ms,这意味着每 100ms 内的单位时间内,被该控制组限制的进程只能使用2ms的CPU时间,即只能用到2%的计算力。
| |
打开htop指令可以看到刚才的死循环只有2%的CPU占用。
实验完成后可以使用
cgdelete -r cpu:container删除
这样就可以理解 Linux Cgroups 的设计,其限制进程的方式也是简单粗暴,为一个子目录系统上添加一组资源限制文件的组合即可。在docker容器中,也可以直接通过命令来查看。
docker run -it --cpu-period=100000 --cpu-quota=20000 busybox /bin/sh

Cgroups 的问题 容器的Cgroups只是限制了某个进程的使用资源而已,而进程本身看到的资源还是宿主机的资源。
/proc 文件系统并不知道 Cgroups 给某个进程做了什么限制。这就会造成在容器中使用 top,free,df 等命令看到的全部是宿主机上的资源。这会给应用的运行带来非常大的困惑。
不过在生产环境,已经有 lxcfs 这样的技术可以修正这种偏差。
| |
其原理是把宿主机上的 /var/lib/lxcfs/proc/meminfo 文件挂载到容器的 /proc/meminfo 位置。
refer: https://cuisongliu.github.io/2019/03/docker/lxcfs/
镜像
Namespace 和 Cgroups 使这个特殊的进程看到的是隔离环境,而且使用的资源也被限制。那么这样还有一个点,就是进程看到的文件系统是什么呢?这里没有新的技术,还是最开始提到的Mount Namespace技术,拥有这项技术,可以给容器挂载一个全新、独立的文件系统。
挂载完成之后使用 chroot 指令, 使得新的挂载点成为进程的 / 路径。一般为了让这个容器的根目录更为真实,一般会给进程容器的根目录下挂载一个完整操作系统的文件系统。比如 Ubuntu19.04 的ISO。而这个挂载在容器根目录上的、用来给容器进程提供隔离后执行环境的文件系统就是 rootfs(根文件系统)
这里我再来强调一遍,容器是一个特殊的进程而已!!!rootfs只是操作系统所包含的文件、配置和目录,并不包含内核,内核是宿主机的内核。所以说 rootfs只是操作系统的驱壳,并没有操作系统的灵魂
不过正是rootfs的存在,才有了容器作为PaaS的基础,一致性!开发的程序连同操作系统的整个目录环境被打包封装在一个集装箱里。真正的依赖库都放在了这个rootfs的/var/lib/xxx 里。
还没完,虽然这个时候已经解决了大部分问题,但是每个容器创建的时候都需要一个rootfs未免也太浪费空间了,Docker的解决方法是提出 layer 的概念。用户每制造出来一个镜像就生成一个层。
Linux操作系统又提供了一种联合文件系统(Union File System)的能力。 UFS 提供的能力是将多个目录挂载到同一个目录下,使得多个目录合并。
假设有两个目录A和B
| |
创建目录C,并且将两个目录挂载到一个公共的目录C
| |
以Docker容器为例,这个挂载点就是在 /var/lib/docker/overlay2 下。不出意外,这个下面拥有一个完整的ubuntu操作系统
| |
同时也可以看到,对应的操作系统挂载信息里面的overlay信息。可以看到最终多个目录被联合挂载到/var/lib/docker/overlay2/3734ddb66fee5ad2339503f830d7d073f8179c98ccd74d3ce11077d7605f5ba1/merged 上,而这个merged会最终呈现一个文件系统。
| |
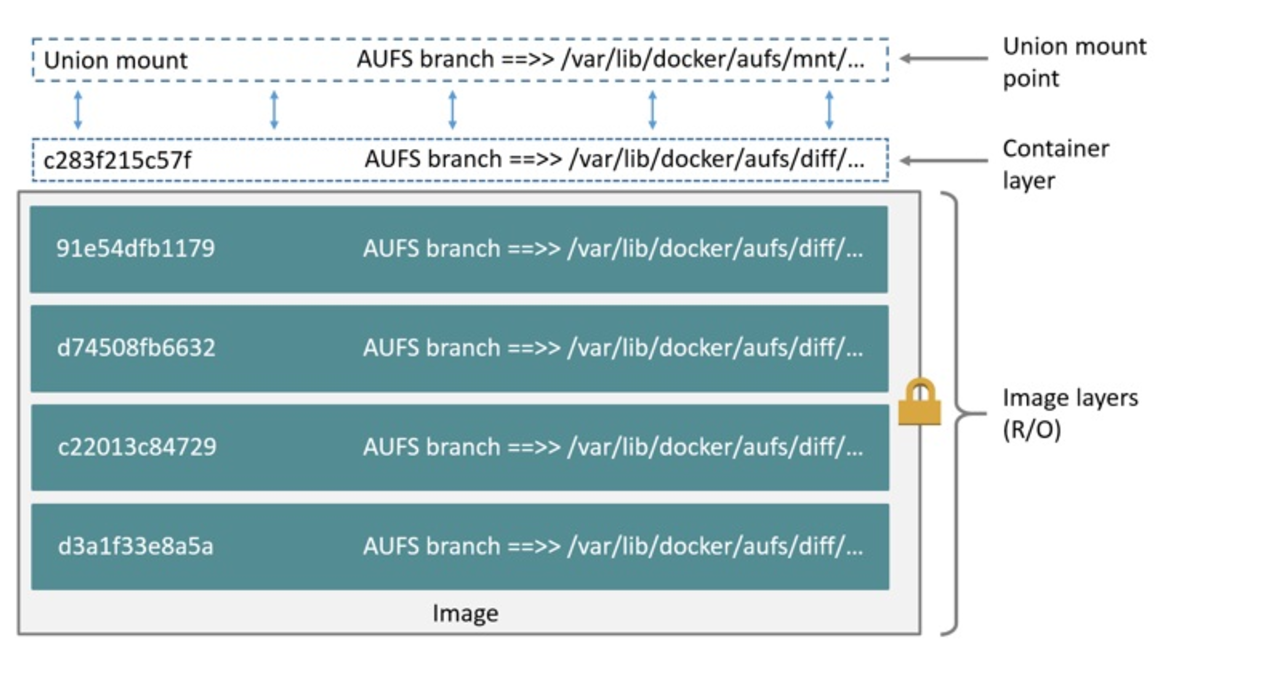
最下面的几层只读。上层的可写。而最上层是可读写。
所以在运行容器的时候,只需要拉取不存在的 image layer。镜像一般完全拉下来的化需要3,4百M,一般的大厂都是采用 p2p 下载镜像,如 阿里的蜻蜓 p2p 下载。
制作Docker镜像
使用 golang 编写一个web应用。准备一个main.go
| |
制作Dockerfile 文件。
| |
制作镜像在当前目录执行docker build -t hello .
run 起来该容器docker run -p 8000:8000 hello
上传到 docker hub
在docker hub 上创建一个 docker 账号使用 docker login 登录
| |