什么?DMA竟然可以作弊
好吧,其实是最近在刷 B 站的时候,偶然看到差评君的一个 vlog – 游戏厂商下场制裁DMA外挂,VT-d技术立大功?
视频链接放到末尾 ~
好吧,真的是有些落伍了,没想到当知道 DMA 可以作弊的时候,竟然是 DMA 的漏洞被堵上的时候。

前言: 为什么DMA能作弊?
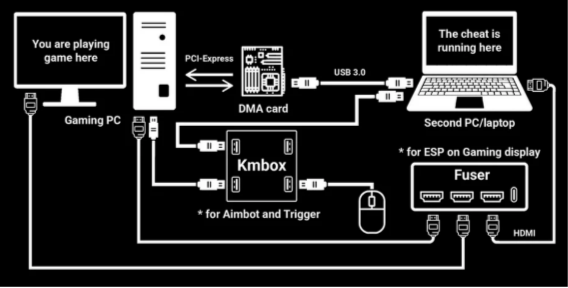
所谓DMA作弊,即利用DMA(Direct Memory Aceess直接内存访问)硬件进行作弊,他的特点是作弊者会有两台机器,A机器(游戏机器)的内存数据被直接在硬件层读取至B机器(作弊机器),随后在B机器上作弊的数据再投影到A机器上,搭配上Kmbox(可以理解为赋予自瞄与扳机功能)使得所有作弊行为都在A机器外部,让作弊者难以被检测。由于DMA硬件属于合法的科研硬件,所以无法直接在售卖层面上直接进行一刀切的打击。
上面的一段描述是摘抄自 CF 官方的一段 针对DMA外挂,新打击手段上线! , 是不是云里雾里的?没关系,我也不懂,下面分析一下。
基础知识回顾
进程内存布局
在理解DMA作弊之前,必须先掌握计算机系统的基础内存管理概念。当一个程序(例如一个游戏)被加载和执行时,操作系统会为其创建一个独立的虚拟地址空间。这个地址空间通常被划分为多个逻辑区域,包括:代码段(存储程序指令)、数据段(存储全局变量和静态变量)、堆(用于动态内存分配)、以及栈(用于函数调用和局部变量) 。
说一个基础知识:进程是资源分配的基本单位。 而进程操作的虚拟内存,进程是不能直接看到物理内存。
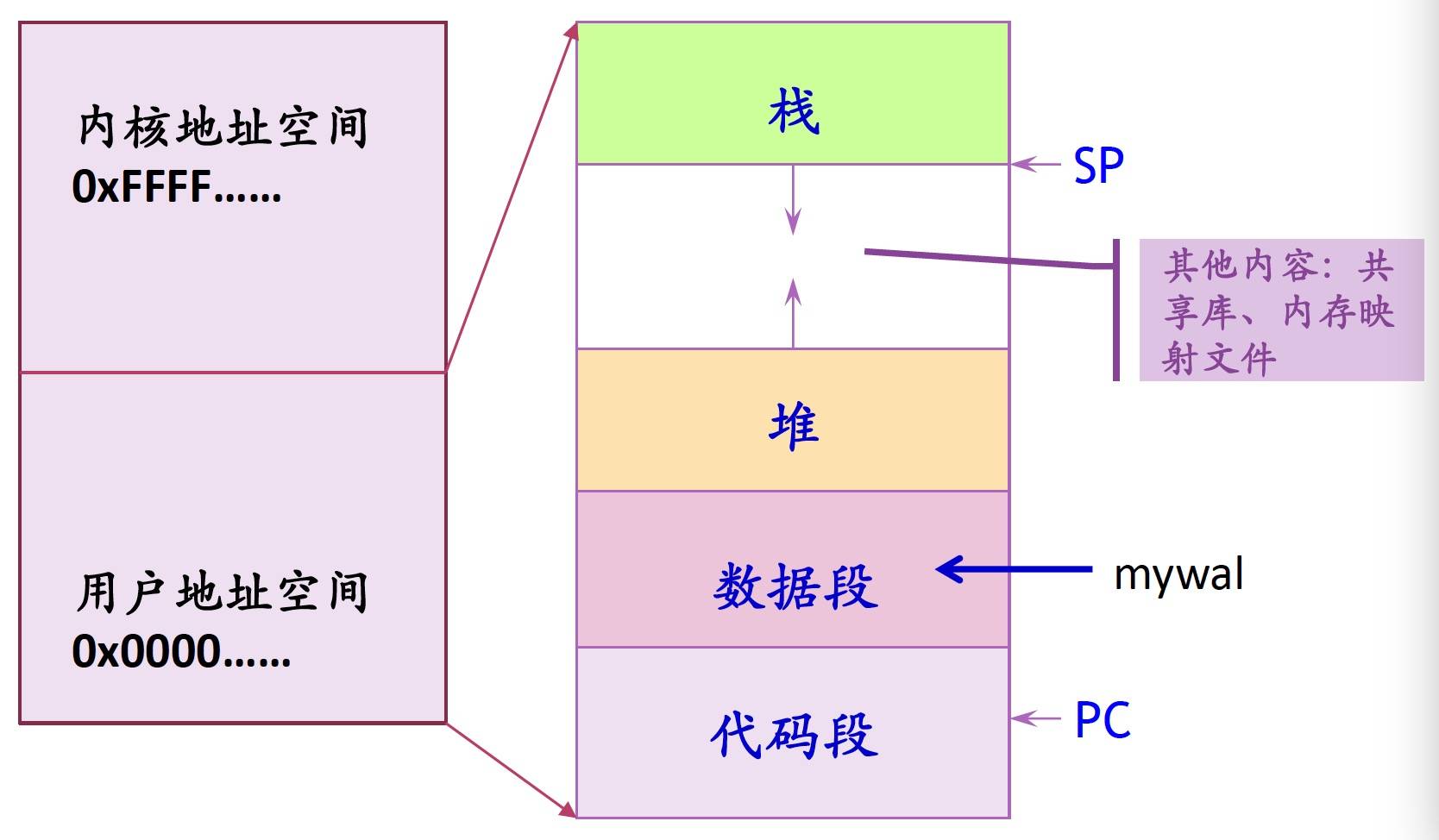
以下是我本地跑的 nginx 进程的内存分布(可以在 /proc/{PID}/task/{TID}/maps 下面看到),这里明显可以看到。
其内存分配最开始(最下面的是低地址)分别是
ELF可执行文件(
/home/work/nginx/sbin/nginx)数据段、代码段(属于ELF的一部分)
堆(heap)
共享库 (更靠近高地址的区域,比如
libc.so.6、libpcre.so.3等,用mmap单独映射的一片地址空间,通常在中高地址)栈(stack)
vdso、vsyscall
内核空间(用户态不可见)
$ ps aux|grep nginx
root 1556 0.0 0.0 636948 13532 ? Ss Aug17 0:00 nginx: master process /home/work/nginx/sbin/nginx
work 158960 0.0 0.0 637428 14036 ? S Aug23 0:15 nginx: worker process
work 158961 0.0 0.0 637428 13724 ? S Aug23 0:00 ...
$ cat /proc/1556/task/1556/maps
40a09000-40a29000 rw-p 00000000 00:00 0
59d51dcef000-59d51ddb1000 r--p 00000000 103:06 12217940 /home/work/nginx/sbin/nginx
59d51ddb1000-59d51e101000 r-xp 000c2000 103:06 12217940 /home/work/nginx/sbin/nginx
59d51e101000-59d51e1f2000 r--p 00412000 103:06 12217940 /home/work/nginx/sbin/nginx
59d51e1f2000-59d51e224000 r--p 00503000 103:06 12217940 /home/work/nginx/sbin/nginx
59d51e224000-59d51e24c000 rw-p 00535000 103:06 12217940 /home/work/nginx/sbin/nginx
59d51e24c000-59d51e992000 rw-p 00000000 00:00 0
59d543244000-59d543f44000 rw-p 00000000 00:00 0 [heap]
59d543f44000-59d544044000 rw-p 00000000 00:00 0 [heap]
7ac2ed800000-7ac2ed900000 rw-s 00000000 00:01 1283996 /dev/zero (deleted)
...
7ac312200000-7ac31229d000 r--p 00000000 103:06 7630248 /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.33
...
7ac312a9c000-7ac312a9d000 r--p 0002f000 103:06 7613546 /usr/lib/x86_64-linux-gnu/libcrypt.so.1.1.0
7ac312a9d000-7ac312a9e000 rw-p 00030000 103:06 7613546 /usr/lib/x86_64-linux-gnu/libcrypt.so.1.1.0
7ac312a9e000-7ac312aa6000 rw-p 00000000 00:00 0
7ac312aa6000-7ac312ab7000 r--p 00000000 103:06 7637238 /usr/lib/x86_64-linux-gnu/libtcmalloc.so.4.5.16
...
7ac312aec000-7ac312ca2000 rw-p 00000000 00:00 0
7ac312cb5000-7ac312cb6000 rw-s 00000000 00:01 5143 /dev/zero (deleted)
7ac312cb6000-7ac312cba000 rw-p 00000000 00:00 0
7ac312cba000-7ac312cbc000 r--p 00000000 00:00 0 [vvar]
7ac312cbc000-7ac312cbe000 r--p 00000000 00:00 0 [vvar_vclock]
7ac312cbe000-7ac312cc0000 r-xp 00000000 00:00 0 [vdso]
7ac312cc0000-7ac312cc1000 r--p 00000000 103:06 7619661 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ac312cc1000-7ac312cec000 r-xp 00001000 103:06 7619661 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ac312cec000-7ac312cf6000 r--p 0002c000 103:06 7619661 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ac312cf6000-7ac312cf8000 r--p 00036000 103:06 7619661 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ac312cf8000-7ac312cfa000 rw-p 00038000 103:06 7619661 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ffe39701000-7ffe39722000 rw-p 00000000 00:00 0 [stack]
ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]虚拟内存 vs 物理内存
那么为什么进程不能直接操作物理内存而是只能操作虚拟内存呢?
单片机是没有操作系统的,所以每次写完代码,都需要借助工具把程序烧录进去,这样程序才能跑起来。
另外,单片机的 CPU 是直接操作内存的「物理地址」。
现代操作系统需要运行多个软件,多个进程如果管理不善就会冲突,所以最好的办法就是视图隔离。即让操作系统为每个进程分配独立的一套「虚拟地址」,每个进程在隔离环境随便访问,由操作系统再将内存映射到物理内存上去。
于是,这里就引出了两种地址的概念:
- 我们程序所使用的内存地址叫做虚拟内存地址(Virtual Memory Address)
- 实际存在硬件里面的空间地址叫物理内存地址(Physical Memory Address)。
而 虚拟内存地址 -> 物理内存地址 的映射关系就是由 操作系统内核 保存和管理。
- 页表(Page Table)
内核会根据 mm_struct 建立 页表(page table),描述 虚拟地址 → 物理页框 的映射关系。
每个进程都有自己的页表(x86_64 下是多级页表,4 级/5 级)。
- 内存管理单元(MMU)
MMU 本质上是一个硬件单元,它的主要职责是管理虚拟内存和物理内存之间的映射关系。
CPU 需要执行程序加载进程的内存时。通过进程上下文切换将 CR3 寄存器 指向当前进程的页表根目录。注意:MMU 并不保存完整页表。
每次内存访问时,MMU 会:
- 查页表,把虚拟地址翻译成物理地址
- 如果页表项不在 TLB(快表)里,就触发 缺页异常,由内核加载对应的页表项。
- TLB(Translation Lookaside Buffer)
TLB 也是一个硬件单元,但它的功能更像一个高速缓存(Cache)。它存储的是最近被MMU使用过的、虚拟地址到物理地址的映射记录。
- MMU 内部的 TLB 会缓存最近使用的 虚拟页 → 物理页 映射,加快地址转换。
- 但 TLB 只是一小部分,完整的映射仍然在页表中,由内核维护。

这里有一个知识点:进程操作内存需要通过 MMU,而 MMU 提供了 内存保护 , 所以游戏进程中的数据正常是不会被其他进程所窥探。
内核态与用户态
为了保障系统的安全性和稳定性,CPU被设计成具有不同的权限等级。在Windows和Linux等操作系统中,最常见的两个权限等级是用户态(User Mode)和内核态(Kernel Mode) 。
- 用户态:这是大多数应用程序(包括游戏和作弊软件)运行的受限环境。用户态程序无法直接访问硬件、修改系统核心数据,或访问其他进程的内存。它们必须通过“系统调用”(System Call)来向内核请求服务,例如读写文件、网络通信或访问硬件 。
- 内核态:这是操作系统核心(内核)运行的特权环境。内核拥有对所有系统资源和硬件的完全控制权。当一个用户态程序发起系统调用时,CPU会从用户态切换到内核态,由内核完成请求,然后再切换回用户态 。
这种严格的权限分离使得传统的软件作弊器(运行在用户态)无法直接对抗高端的反作弊程序(通过驱动运行在内核态)。一个内核级的反作弊程序可以轻松地检测、甚至阻止用户态作弊软件的任何恶意行为。
游戏内存操作分析
游戏常用的内存结构
如前所述,游戏中的关键数据(如生命值、金币、坐标)通常被存储在动态分配的内存区域,其地址在每次游戏启动时都会发生变化 。对于作弊者而言,直接在物理内存中定位一个动态变化的地址是极其困难的。
所以对于一个初级的作弊手段来说,其还是从用户态的角度去操作游戏进程的虚拟内存。
等等!!不是说 MMU 可以保护内存吗?怎么外挂进程还操作上游戏进程的内存上了?
这里有2个途径:
- 使用
ptrace系统调用
经常搞程序开发的同学都知道,我们可以在 IDE 通过 DLV、gdb 来进行程序调试。
ptrace 系统调用是 GDB 这类调试器能够工作的基础,它的原理和 GDB 是一样的。
简单来说,ptrace(全称 “process trace”)是 Linux 提供的一个系统调用,它允许一个进程(通常是父进程或调试器)控制另一个进程(子进程或被调试进程)的执行。
这是最常见、最经典的方式。一个外挂程序可以调用 ptrace 系统调用,“附着”(attach)到游戏进程上。一旦附着成功,外挂就可以使用 ptrace 提供的其他功能(比如 PTRACE_POKEDATA)来直接读写游戏进程的内存。这种方式更像是一个调试器在工作。
- 案例:
这是一个 ptrace 的案例 https://github.com/skeeto/ptrace-examples
- 使用
/proc/<pid>/mem文件
/proc/pid/maps 的每一行表示一个虚拟内存区域(VMA),包含以下字段:
<起始地址>-<结束地址> <权限> <偏移量> <设备号> <索引节点号> <文件路径>这样,如果需要修改游戏中的健康值,通常关注 [heap] 或特定模块(如 xonotic-linux64-sdl)。
/proc/pid/mem 是一个伪文件,允许直接访问目标进程的虚拟内存。结合 /proc/pid/task/tid/maps,你可以确定要读取的内存区域地址,然后通过 pread 系统调用从 /proc/pid/mem 中读取数据。
- 案例:
https://github.com/ruial/linux-game-hack-example/ github上就有一个这样的入门级小项目。
这篇发布于 2019 年 7 月 20 日的《Game hacking on Linux》文章,以开源游戏Xonotic(Linux 平台)为实战案例,系统讲解了 Linux 环境下游戏修改(制作简单 “作弊” 功能)的完整流程,核心是实现 “无限生命值” 和 “无限弹药”,同时科普了游戏修改的底层原理与技术细节。
该项目利用了 Linux 系统下进程内存操作的技术,通过以下步骤实现作弊:
- 定位游戏进程的内存地址:通过解析 /proc/pid/maps 或使用调试工具(如 Cheat Engine)找到游戏中存储健康值和弹药值的内存地址。
- 读取内存:使用 Linux 系统调用(如 process_vm_readv)读取目标进程的内存数据,获取当前健康值和弹药值。
- 写入内存:使用 process_vm_writev 将健康值和弹药值设置为固定值(例如 150),从而实现“冻结”效果。
- 持续监控:通过循环不断写入固定值,确保健康值和弹药值不会减少。
unsigned long module_addr(pid_t pid, char *name) {
char cmd[200];
sprintf(cmd, "cat /proc/%d/maps | grep %s -m1 | cut -d '-' -f1", pid, name);
FILE *f = popen(cmd, "r");
char line[20];
fgets(line, 20, f);
pclose(f);
return strtoul(line, NULL, 16);
}通过获取模块的基地址,再结合预先确定的内存偏移量(如 game.h 中定义的 PLAYER_OFFSET_1 等),可以计算出玩家生命值、弹药数等具体数据在内存中的准确位置,为后续的内存读写操作提供基础。
数据扫描与修改原理
一般的游戏外挂程序修改游戏进程中的数据(比如血量),其技术原理可以分为两个主要步骤:定位数据和修改数据。
第一步:定位数据
这是最关键的一步。外挂程序需要知道游戏数据(比如角色的血量值)在内存中的确切位置。这个过程通常分为以下几个阶段:
1. 扫描内存
外挂程序会像一个侦探一样,在游戏的整个内存空间中寻找可能的线索。它会通过系统调用(例如 ReadProcessMemory 在 Windows 上,或我们之前讨论的 /proc/<pid>/mem 在 Linux 上),来读取游戏进程的内存数据。
这个过程通常是一个迭代的、逐步缩小的过程:
- 首次扫描:假设你的游戏角色当前血量是 100。外挂会扫描整个内存,找出所有值为 100 的内存地址。
- 多次筛选:你让角色受伤,血量变成了 80。外挂会再次扫描,但这次只在上次找到的地址中,筛选出那些值变为 80 的地址。
- 锁定地址:重复这个过程几次后,最终会锁定一个或几个最有可能的内存地址。这个地址就是你角色血量在内存中的位置。
2. 找到指针
找到血量的内存地址后,更高级的外挂还会继续追踪。因为这个地址可能只是一个临时地址,当游戏重启或加载新场景时,它可能会改变。
一个更稳定的方法是找到一个指向这个血量地址的指针。这个指针的地址通常是固定的。外挂会通过指针扫描的技术,找到一个固定的地址,它里面存储的值就是血量所在的地址。
第二步:修改数据
一旦外挂锁定了血量的内存地址(或者指向血量地址的指针),修改数据就变得相对简单了。
外挂程序会再次利用系统调用(例如 WriteProcessMemory 或 /proc/<pid>/mem),向这个特定的内存地址写入新的数据。
例如,如果血量在内存中的地址是 0x12345678,外挂就会向这个地址写入一个非常大的数值(比如 99999),从而实现“锁血”的效果。
这个过程就像是:
- 定位数据:你找到了一个朋友的住址。
- 修改数据:你直接去他家,把他的银行存折上的数字改成了 99999。
内存保护与防护机制
传统的软件作弊,无论是内存修改器还是DLL注入,都局限在操作系统的软件层面。这些工具必须在游戏进程的虚拟地址空间内工作,并受到操作系统权限等级的严格限制。
正如前面所说的,现代操作系统都采用虚拟内存技术,这是一种内存管理技巧,它为每个进程提供了一个连续的、私有的地址空间,创造了“拥有巨大内存”的假象 。这个虚拟地址空间(Virtual Address Space)与计算机实际的物理内存(Physical Memory,即RAM)是分开的。每个进程都只能看到自己的虚拟地址,而无法直接访问物理内存。
负责将虚拟地址转换为物理地址的是CPU内部的内存管理单元(MMU)。MMU通过一个被称为“页表”(Page Table)的数据结构来完成地址翻译。当一个程序访问一个虚拟地址时,MMU会查询该进程的页表,找到对应的物理页帧(Physical Frame),从而完成对物理内存的读写 。这种机制确保了进程之间的内存隔离,一个进程的错误或崩溃不会影响到整个系统。
腾讯的 Anti-Cheat Expert (ACE) 是一种专业游戏反作弊系统
- ACE 的核心检测机制
ACE 的反作弊策略基于以下几个核心方向,综合使用客户端和服务器端技术,结合人工智能(AI)和大数据分析:
- 内存保护与检测:
- 检测内存修改:ACE 监控游戏进程的内存区域,检测未经授权的读写操作。例如,作弊软件(如前文提到的 Xonotic 示例)通过 /proc/pid/mem 或 process_vm_writev 修改健康值或弹药值,ACE 会检测这些异常操作。
- 文件和进程扫描:
- 检测已知作弊工具:ACE 维护一个庞大的作弊样本数据库(包括工具如 Cheat Engine、Huluxia、Pancake Modifier),通过扫描进程列表或文件签名识别运行中的作弊软件。
- 与 /proc/pid/maps 的关联:ACE 可能检查 /proc/pid/maps 中的映射文件路径,检测是否加载了可疑的动态库(例如非官方的 .so 文件)或虚拟机相关的内存区域(如 VirtualAPP、Parallel Space)。
DMA 原理概述

DMA 是什么?
DMA,即直接内存访问,是计算机系统中一项至关重要的硬件功能。它允许某些硬件子系统(如显卡、网卡、磁盘控制器等)在不占用中央处理器(CPU)资源的情况下,直接与主系统内存(RAM)进行高速数据传输 。
在没有DMA技术的早期系统中,所有数据传输都必须由CPU亲自管理。这意味着CPU需要读取数据,将其存入寄存器,再写入到目标内存地址,这一过程效率低下且会完全占用CPU资源 。而有了DMA,CPU只需向一个特殊的硬件芯片——DMA控制器(DMAC)——发送一个指令,告知其数据传输的源地址、目的地址和数据量,之后DMA控制器便能自主地完成整个传输过程,而CPU则可以继续执行其他任务 。这种并行化的处理能力极大地提高了系统性能和吞吐量,在处理大量数据流(如视频渲染、网络通信)时至关重要 。
CPU 与 DMA 的区别
DMA控制器(DMAC)就像一个可以独立工作的“数据搬运工”。其工作流程大致遵循以下步骤 :
- 初始化:CPU通过总线向DMA控制器的寄存器写入传输所需的参数,包括源地址、目的地址、传输方向和字节数 。
- 总线请求与授权:DMAC向CPU发送一个总线请求(Bus Request),请求获得对系统总线的控制权 。
- 数据传输:一旦CPU授予总线控制权,DMAC便直接与内存进行通信,自主地进行数据读写。DMAC拥有自己的地址寄存器,能够自动递增地址,无需CPU干预 。
- 完成中断:当所有数据传输完成后,DMAC会向CPU发送一个中断信号,告知其任务已完成,并将总线控制权交还给CPU 。
在数据传输过程中,DMAC通常会采用不同的模式来优化性能。例如:
- 突发模式(Burst Mode):DMAC一次性获得总线控制权,连续传输整个数据块,直到传输完成才释放总线 。
- 周期窃取模式(Cycle Stealing Mode):DMAC在每次传输一个字节或一个字后便释放总线,再重新请求。这种模式虽然传输速度较慢,但不会长时间占用总线,使得CPU能够与DMA操作交替进行 。
洞察:合法技术与恶意滥用的边界
DMA技术本身是现代计算机架构中一个合法且必不可少的功能,它的核心价值在于提升系统效率。然而,其最根本的特性——直接且不受CPU和操作系统控制地访问物理内存——也为恶意攻击提供了完美的物理通道 。DMA作弊者利用的,正是这一原本用于性能优化的合法通道。传统的软件反作弊程序将一个PCIe设备对物理内存的访问视为正常的硬件行为,因为它们缺乏有效手段来判断这个硬件行为是源于合法的网卡驱动,还是恶意的DMA作弊卡。这种对合法通道的恶意滥用,解释了为什么DMA作弊能够如此隐蔽地绕过软件层面的防御。
DMA 作弊技术实现思路:硬件层面的降维打击
作弊架构:双PC分离
DMA作弊的核心优势在于其物理隔离。作弊者通常采用双PC架构:一台是专门用于游戏的“游戏PC”,另一台是运行作弊软件和进行内存分析的“作弊PC” 。两台PC通过一根高速数据线(通常是USB或HDMI)和一块定制的PCIe DMA卡连接起来 。
这种架构带来了巨大的防御优势:
- 软件隔离:作弊软件完全没有在游戏PC上运行。游戏PC上的反作弊程序无法扫描到任何作弊进程、注入的DLL或篡改的文件 。它所能看到的是一块正常的、由游戏PC操作系统驱动的PCIe设备。
- 硬件伪装:作弊PC上的软件通过DMA卡直接读取游戏PC的物理内存。一个常见的设置是,作弊PC上的软件将游戏PC内存中的玩家位置、敌方坐标等信息读取出来,然后通过视频信号合成器(KMbox)将作弊信息叠加到游戏画面上,实现“透视”功能 。
跨越鸿沟:从虚拟地址到物理地址的转换
如前文所述,DMA卡只能访问物理内存,而作弊者通过软件分析得到的却是虚拟地址 。这构成了DMA作弊的核心技术挑战:如何在外部硬件层面完成虚拟地址到物理地址的转换?
作弊者需要解决的关键问题是,DMA卡如何获取游戏PC的页表。在x86-64架构上,页表的基址存储在CR3寄存器中。作弊硬件必须能够读取这个寄存器,才能找到页表。一旦获取了页表基址,作弊软件便可以自己完成地址翻译的过程 。这个过程本质上是模拟了CPU的MMU功能,通过读取并解析多级页表,从一个进程的虚拟地址,一步步找到它所对应的物理地址 。
由于DMA卡对物理内存拥有完全的访问权限,它不仅可以访问游戏进程的内存,理论上还可以访问操作系统内核的内存空间。这种能力使得DMA作弊者能够轻松地获取页表数据,从而实现对任何进程内存的读写。
作弊固件与硬件伪装
为了进一步逃避检测,高端DMA作弊卡通常会使用自定义的固件。固件可以修改DMA卡在PCIe总线上的身份信息,即所谓的“配置空间寄存器”(Configuration Space Registers) 。这些寄存器包含了设备的供应商ID(Vendor ID)、设备ID(Device ID)、版本号等信息 。
通过自定义固件,作弊者可以轻易地将DMA卡伪装成一个合法的、常见的设备,例如:
- 网卡(NIC):由于网卡需要频繁地进行DMA操作以收发数据包,因此伪装成网卡可以很好地解释DMA卡的活动 。
- 声卡或存储控制器:同样,这些设备也具有合法的DMA访问权限 。
这种伪装使得反作弊软件难以通过黑名单机制来检测DMA卡。即使反作弊程序扫描到PCIe插槽上有一个可疑设备,它所看到的也是一个具有合法硬件ID和驱动的“无害”设备,从而无法将其标记为作弊工具 。
安全与防护
硬件层面防护
DMA (Direct Memory Access) 作弊之所以难以防范,是因为它完全绕过了操作系统的软件层保护,直接在硬件层面进行操作。而传统的反作弊系统主要在软件层面工作,因此无法检测到这种攻击。
为了对抗 DMA 作弊,反作弊厂商和硬件制造商(如英特尔和 AMD)开始利用一种特殊的硬件功能来反击,这就是你提到的 Intel VT-d。
什么是 Intel VT-d?
Intel VT-d(Virtualization Technology for Directed I/O)是英特尔处理器的一种硬件虚拟化技术。它的主要作用是让操作系统能够对连接到电脑上的外部设备(如网卡、声卡、DMA 设备等)进行更精细、更安全的控制。
你可以把 VT-d 想象成一个专为 DMA 设计的“门卫”。在没有 VT-d 的情况下,DMA 设备可以随意地在物理内存中读写数据。而有了 VT-d,所有 DMA 设备的访问都必须先经过这个“门卫”的检查和许可。
Intel VT-d 如何做到反作弊
面对DMA作弊对物理内存的直接威胁,最直接有效的防御手段是硬件层面的。IOMMU(Input/Output Memory Management Unit,输入/输出内存管理单元)就是为此而生。IOMMU的工作原理类似于CPU的MMU,但它是针对I/O设备的 。
IOMMU在DMA设备和物理内存之间增加了一层权限控制和地址翻译。它为每个DMA设备提供一个独立的I/O虚拟地址空间,并使用IOMMU页表将这些I/O虚拟地址映射到受限的物理地址上 。这意味着:
- 内存隔离:IOMMU确保一个DMA设备(例如显卡)只能访问它被授权访问的内存区域,而无法像DMA作弊卡那样随意读写整个物理内存 。
- 地址翻译:IOMMU同样可以进行地址翻译,将不连续的物理内存块映射到连续的I/O虚拟地址空间,简化驱动开发 。
VT-d 的核心功能是为每个外部设备(PCIe 设备)分配一个独立的IOMMU (Input/Output Memory Management Unit)。
这个 IOMMU 的作用就像是为每个设备创建了一个独立的页表。当一个 DMA 设备想要访问内存时,它提供的地址不再被当作物理地址,而是被当作虚拟地址。
当一个DMA作弊卡试图访问一个未被授权的物理地址时,IOMMU会拦截该请求并产生一个保护错误,从而阻止攻击 。在支持IOMMU的系统中,作弊者必须想办法绕过IOMMU的保护,这通常需要利用IOMMU配置不当的漏洞 。
这直接废掉了 DMA 外挂的“核心武器”。DMA 外挂不再能直接使用物理地址,它现在必须像一个正常的程序一样,通过一个页表(IOMMU 页表)来间接访问物理内存。