认识eBPF
eBPF 是从 BPF(Berkeley Packet Filter)技术扩展而来,最初就是为了实现快速包过滤而实现的一门技术,因为可以直接在内核中执行,避免了向用户态复制每一个数据包,从而极大提升了包过滤的性能。后来由于这个思路非常受到欢迎,在各个场景都需要内核态的快速开发,使得BPF不再限于网络栈,而是内核的一个顶级子系统。即成了现在的 eBPF 。
![]()
eBPF 背景
1997 年,Linux 2.1.75 首次引入了 BPF 技术,将高性能的 BSD 包过滤机制 BPF 带入Linux
2014年,为了研究新的 SDN 1方案,BPF被扩展为一个通用的虚拟机,也就成了现在 eBPF 的雏形。
2015年,BCC(BPF Compiler Collection)提供了一系列的基于 eBPF 的工具和库函数,大大简化了 eBPF 程序的开发和运行。
2016年,Linux 4.7 - 4.10 带来了跟踪点,perf 事件、XDP 以及 cgroups 的支持,丰富了 eBPF 的事件源。
2017年,BPF 成为内核的独立子模块,大型互联网公司开始利用 eBPF 用于跟踪、DDos 防御、4层负载均衡等。
直到今天,eBPF 已然成为内核社区最活跃的子模块之一。
认识 eBPF
eBPF 如何工作
eBPF 不像一般的程序启动后即运行。他需要事件触发才会执行,这些事件包括 系统调用、内核追踪点、内核函数、用户态函数的调用退出、网络事件 等等。借助于内核态插桩(kprobe)和用户态插桩(uprobe),eBPF 可以在内核和用户态应用的任意位置进行插桩。
当然 eBPF 也不是无所不能的。
为了安全考虑,它要保证内核的安全,只有经过验证代码才会被执行,诸如无限循环、会导致内核崩溃、执行时间很长的程序会被 验证器拒绝执行。
eBPF不能随意调用内核函数,一般只能调用在 API 定义的辅助函数。
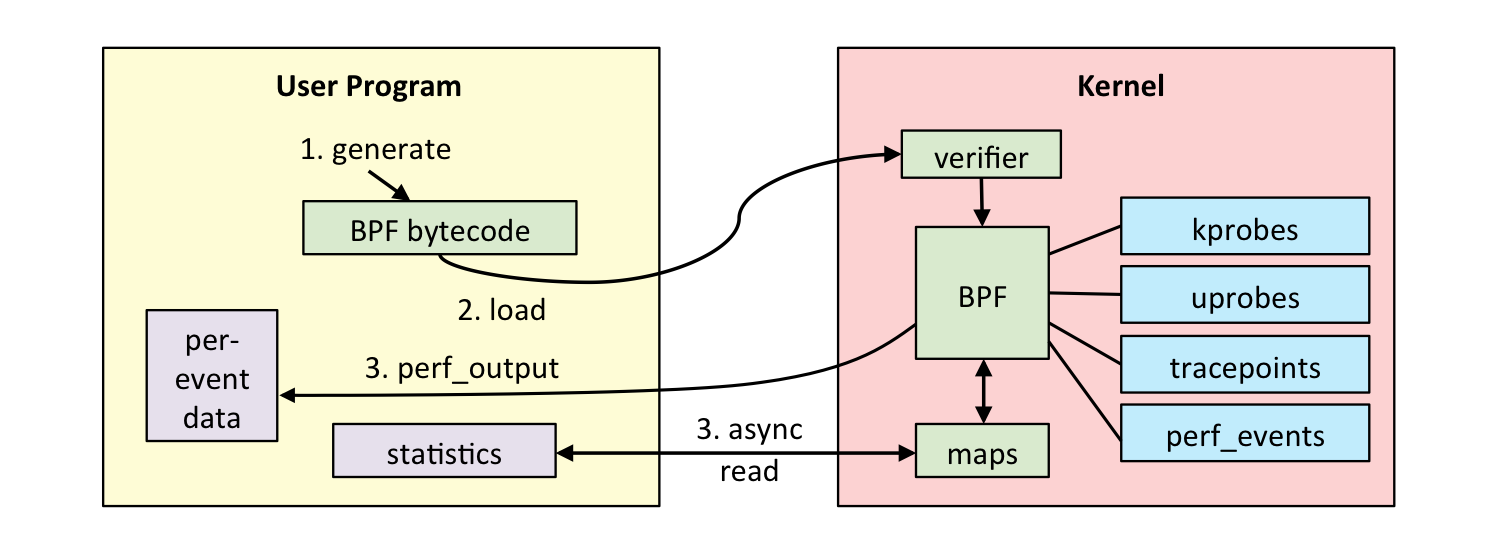
eBPF 的开发和执行过程如下:
- 第一步:使用 C 语言开发一个 eBPF 程序;
- 第二步:借助 LLVM 把 eBPF 程序编译成 BPF 字节码;
- 第三步:通过bpf系统调用,把BPF字节码提交给内核;
- 第四步:内核验证并运行 BPF 字节码,把相应状态保存在BPF映射中;
- 第五步:用户程序通过 BPF 映射查询 BPF 字节码的运行状态;
准备环境
- Ubuntu 22.04 (内核版本 5.15.0-27-generic)
- C 语言程序编译工具 make
- eBPF 工具集 BCC 和依赖的内核头文件
- libbpf 库
- eBPF 程序管理工具 bpftool
$ sudo apt install make clang llvm libelf-dev bpfcc-tools \
libbpfcc-dev linux-tools-$(uname -r) linux-headers-$(uname -r)第一个eBPF 程序
第一个eBPF程序从 BCC 开始。BCC 是一个 BPF 编译器集合,包含用于构建 BPF 程序的编程框架和库,并提供了大量的可以直接使用的工具,使用BCC的好处就是把上述 eBPF 执行过程通过内置框架进行抽象,并提供了 C、Python等编程语言接口。
案例:追踪打开文件的系统调用。
追踪文件打开事件的应用场景是 eBPF 的一个非常有用的场景,1. 比如追踪自定义配置文件加载情况; 2. 查看是否存在频繁或周期性打开某文件的情况; 3. 分析 /proc、/sys 等虚拟文件系统在性能追踪上的应用;4. 分析 K8S、Docker 等 cgroup 相关操作。
原理:由于文件打开,都少不了内核的系统函数调用,所以只需要跟踪 openat() 这个系统调用即可以跟踪所有的文件打开操作。如何跟踪系统调用呢?这就需要依赖 BCC 软件包了。BCC 是一个 BPF 编译器集合,其提供了大量可以直接使用的工具。具体可以参考 bcc Python (也可以使用 gobpf/bcc 😉)。下面的例子参考 geektime 的 bpf 例子
- 第一步:使用 C 语言开发一个 eBPF 程序
新建一个 hello.c 如下
int hello_world(void *ctx)
{
bpf_trace_printk("Hello, World !");
return 0;
}里面调用 bpf_trace_printk() , 这是最常见一个个 BPF 辅助函数,类似其他语言的 printf 。只不过由于 BPF 是运行在内核中的,他的输出并不是 stdout, 而是内核调试文件 “/sys/kernel/debug/tracing/trace_pipe”
- 第二步:使用 Python 和 BCC 库开发一个用户态程序
接下来创建一个 hello.py
#!/usr/bin/env python3
# 1) import bcc library
from bcc import BPF
# 2) load BPF program
b = BPF(src_file="hello.c")
# 3) attach kprobe
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 4) read and print /sys/kernel/debug/tracing/trace_pipe
b.trace_print()上面的代码中 1)和 2) 分别调用了 BPF 库,并且将 BPF 源代码导入。
调用了一个 attach_kprobe() , 传参分别是
do_sys_openat2()在系统调用openat()在内核中的实现,第二个 fn_name 是 BPF 源代码中定义的执行函数。读取了内核调试文件,并打印到了标准输出中。
- 第三步:执行 eBPF 程序
sudo python3 hello.py执行可以看到一个循环输出一堆字符,其实这就是本系统的打开文件的调用。如下图,此时我们执行一些 cat 命令能看到下图的输出(其实啥都不干,系统其他的打开文件操作已经够多了)
b' tracker-miner-f-1882 [004] d...1 10556.672069: bpf_trace_printk: Hello, World !'
b' cat-9888 [001] d...1 10556.672277: bpf_trace_printk: Hello, World !'
b' cat-9888 [001] d...1 10556.672306: bpf_trace_printk: Hello, World !'
b' cat-9888 [001] d...1 10556.672589: bpf_trace_printk: Hello, World !'
b' cat-9888 [001] d...1 10556.672664: bpf_trace_printk: Hello, World !'
b' zsh-9890 [001] d...1 10556.674391: bpf_trace_printk: Hello, World !'
...输出的格式可以由 “/sys/kernel/debug/tracing/trace_options” 来修改。cat-9888 表示进程的名字和 PID;[004] 是CPU的编号。其他的内容其实看不明白了。而且输出太随意了,所以需要再进一步改造。
进阶
最起码让输出变得更好看一些。因为 BPF 程序可以借助 BPF 映射进行数据存储,而用户程序也可以通过 BPF 映射,同运行在内核中的BPF程序进行交互。BCC 定义了一系列的 库函数和辅助函数,方便交互。
参考官方的说明 https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#2-bpf_perf_output
我们可以创建一个 BPF 表,将自定义事件推送到用户空间,这也是将内核态数据推送到用户空间的首选方案。
#include <uapi/linux/openat2.h>
#include <linux/sched.h> // 读进程名需要
// 定义数据结构
struct data_t {
u32 pid;
u32 uid;
u64 ts;
char comm[TASK_COMM_LEN];
char fname[NAME_MAX];
};
// 定义性能事件映射
BPF_PERF_OUTPUT(events);
// 定义性能事件映射
// refer https://elixir.bootlin.com/linux/latest/source/fs/open.c#L1196 for the param definitions.
int hello_world(struct pt_regs *ctx, int dfd, const char __user * filename,
struct open_how *how)
{
struct data_t data = { };
data.pid = bpf_get_current_pid_tgid();
data.uid = bpf_get_current_uid_gid();
data.ts = bpf_ktime_get_ns();
if (bpf_get_current_comm(&data.comm, sizeof(data.comm)) == 0) {
bpf_probe_read(&data.fname, sizeof(data.fname),
(void *)filename);
}
// 提交性能事件
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}上面以 bpf 开头的函数都是 eBPF 提供的辅助函数,比如 bpf_get_current_pid_tgid 用于获取进程的 TGID 和 PID。bpf_get_current_comm 获取进程名, bpf_probe_read 用于从指定指针处读取固定大小的数据。
解决了数据获取的问题,就剩下在 Python 用户态中使用 BCC 方法读取 eBPF 函数中的 BPF_PERF_OUTPUT 相对应的用户态辅助函数进行打印了。这个对应的函数是 open_perf_buffer() 。它需要一个回调函数,用于处理从 Perf 事件类型的 BPF 映射中读取到的数据。
#!/usr/bin/env python3
# Tracing openat2() system call.
from bcc import BPF
from bcc.utils import printb
# 1) load BPF program
b = BPF(src_file="trace_open.c")
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 2) print header
print("%-18s %-16s %-6s %6s %-16s" % ("TIME(s)", "COMM", "PID", "UID", "FILE"))
# 3) define the callback for perf event
start = 0
def print_event(cpu, data, size):
global start
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
printb(b"%-18.9f %-16s %-6d %-6d %-16s" % (time_s, event.comm, event.pid, event.uid, event.fname))
# 4) loop with callback to print_event
b["events"].open_perf_buffer(print_event)
while 1:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()上面的 3) 处 是一个回调函数,用于具体的打印细节,4) 处的 open_perf_buffer 定义了名为 “events” 的 Perf 事件映射,而后通过一个循环 perf_buffer_poll 读取映射内容,并执行回调函数输出。
这次的执行结果如下。已经比较清楚了。(ps: systemd-oomd 这个进程一直在读和内存相关的系统文件。)
IME(s) COMM PID FILE
0.046618023 systemd-oomd 599 133 /proc/meminfo
0.296788616 systemd-oomd 599 133 /proc/meminfo
0.297136447 systemd-oomd 599 133 /sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/memory.pressure
0.297288993 systemd-oomd 599 133 /sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/memory.current
0.297366262 systemd-oomd 599 133 /sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/memory.min
0.297454589 systemd-oomd 599 133 /sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/memory.low
0.297551363 systemd-oomd 599 133 /sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/memory.swap.current
0.297655740 systemd-oomd 599 133 /sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/memory.stat
...eBPF 的构成
一个完整的 eBPF 程序通常包含 用户态 和 内核态 两部分。其中,用户态负责 eBPF 程序的加载、事件绑定以及 eBPF 程序运行结果的输出汇总。内核态运行在 eBPF 虚拟机中,负责定制和控制系统的运行状态。
eBPF 在内核中运行时主要由 5 个模块组成:
- 模块一: eBPF 辅助函数。它提供了一系列用于 eBPF 程序与内核其他模块进行交互的函数。这些函数并不是任意一个 eBPF 程序都会调用,由 BPF 程序类型决定
- 模块二: eBPF 验证器。它用于保证 eBPF 程序安全,确保没有不可达指令和无效指令
- 模块三: 11个64位寄存器、一个程序计数器和512字节的栈组成的存储模块。这个模块用于控制 eBPF 程序的执行,其中,R0 寄存器用于存储函数调用和 eBPF 程序的返回值,这意味着函数调用只能有一个返回值,R1-R5 寄存器用于存储函数调用的参素,因此函数调用的参数最多不能超过5个;而 R10 是一个只读寄存器,用于从栈中读取数据。
- 模块四: 即时编译器。它将 eBPF 字节码编译成本地机器指令、以便更高效地在内核中执行
- 模块五:BPF 映射(map)。他用于提供大块的存储,这些存储可被用户空间程序用来访问。
eBPF 接口
BPF 系统调用
上面提到了 eBPF 由两部分组成 “用户态” 和 “内核态” 构成。而用户态进行交互必须通过 eBPF 系统调用。第一个参数 cmd 即便是操作命令。
#include <linux/bpf.h>
int bpf(int cmd, union bpf_attr *attr, unsigned int size);python bcc 代码执行时,本质上调用了 bpf 系统函数,cmd 是 BPF_PROG_LOAD (加载一个BPF程序), 第二个参数 bpf_attr 表示 BPF 程序的属性,比如上面程序中的 attach_kprobe 在属性的 prog_type 字段中对应的 BPF_PROG_TYPE_KPROBE。详细可以参考 eBPF 系统调用。
目前的 v5.15 支持 36 个BPF 命令 。
| BPF 命令 | 功能 |
|---|---|
| BPF_MAP_CREATE | 创建一个 BPF 映射 |
| BPF_MAP_LOOKUP_ELEM BPF_MAP_DELETE_ELEM BPF_MAP_UPDATE_ELEM BPF_MAP_LOOKUP_AND_DELETE_ELEM BPF_MAP_GET_NEXT_KEY | BPF 映射相关的操作命令,包括查找、更新、删除以及遍历 |
| BPF_PROG_LOAD | 验证并加载 BPF 程序 |
| BPF_PROG_ATTACH BPF_PROG_DETACH | 把 BPF 程序挂载到内核事件上 把 BPF 程序从内核事件上卸载 |
| BPF_OBJ_PIN | 把BPF程序映射挂载到 sysfs 中的 /sys/fs/bpf 目录中 (常用于保持 BPF 程序在内核中存储) |
| BPF_OBJ_GET | 从 /sys/fs/bpf 目录中查找 BPF 程序 |
| BPF_BTF_LOAD | 验证并加载 BTF 信息 |
BPF 辅助函数
上面是用户态程序的 BPF 系统调用格式,常被封装在 BCC 代码库里,下面是 内核态的 eBPF 程序。其作用是为了辅助 eBPF 程序与其他内核模块的交互,比如获取 UID、PID 、进程名一类的。但是并不是所有的辅助函数都可以在 eBPF 程序中被调用,不同类型的 eBPF 程序支持的辅助函数不同。可以使用bpftool feature probe 查看当前系统支持的辅助函数列表。这些辅助函数的详细定义可以输入 man bpf-helpers 查看。或者参考内核头文件 include/uapi/linux/bpf.h
常用的辅助函数其实在 BCC 软件包里也有提示,如 iovisor/vcc , 还可以在网上查找类似的用法。
| 辅助函数 | 功能描述 |
|---|---|
| bpf_trace_printk(const char *fmt, …) | 向调试文件系统写入调试信息 |
| bpf_map_lookup_elem(map, key) bpf_map_update_elem(map, key, value, flags) bpf_map_delete_elem(map, key) | BPF 映射操作函数,分别是查找、更新和删除 |
| bpf_probe_read(dst, size, ptr) bpf_probe_read_user(dst, size, ptr) bpf_probe_read_kernel(dst, size, ptr) | 从内存指针中读取数据 从用户空间内存指针中读取数据 从内核空间内存指针中读取数据 |
| bpf_probe_read_str(dst, size, ptr) bpf_probe_read_user_str(dst, size, ptr) bpf_probe_read_kernel_str(dst, size, ptr) | 从内存指针中读取字符串 从用户空间内存指针中读取字符串 从内核空间内存指针中读取字符串 |
| bpf_ktime_get_ns() | 获取系统启动以来的时长,单位 纳秒 |
| bpf_get_current_pid_tgid() | 获取当前线程的 TGID 和 PID |
| bpf_get_current_comm(buff, size) | 获取当前线程的任务名称 |
| bpf_get_current_task() | 获取当前任务的task结构体 |
| bpf_perf_event_output(ctx, map, flags, data, size) | 向性能事件缓冲区中写入数据 |
| bpf_get_stackid(ctx, map, flags) | 获取内核态和用户态的调用栈 |
其中 bpf_probe_read 开头的一系列函数是可以访问其他内核空间或用户空间的地址的。
而 eBPF 程序需要大块存储时,不能像其他常规代码一样去分配内存,必须是通过 BPF 映射来完成。
BPF 映射
BPF 映射用于提供大块的键值存储,可用于被用户空间的程序访问,进而获取eBPF 程序的运行状态。BPF 映射只能通过用户态程序的系统调用来创建。正是上文提到的 int bpf(int cmd, union bpf_attr *attr, unsigned int size); 这个函数,只不过其中有一个 cmd 是 BPF_MAP_CREATE 。
映射类型在内核头文件 include/uapi/linux/bpf.h 中的 bpf_map_type 定义,可以使用 bpftool feature probe | grep map_type 查看。
$ bpftool feature probe | grep map_type
eBPF map_type hash is available
eBPF map_type array is available
eBPF map_type prog_array is available
eBPF map_type perf_event_array is available
eBPF map_type percpu_hash is available
eBPF map_type percpu_array is available
...其实我们简单理解,eBPF 的数据结构需要放到一个 类似 Redis 的外部存储里。而事实上,BPF 映射也正是一个类似的数据结构。
| 映射类型 | 功能描述 |
|---|---|
| BPF_MAP_TYPE_HASH | 哈希表映射,用于保存 key/value 对 |
| BPF_MAP_TYPE_LRU_HASH | 哈希表,但拥有LRU功能 |
| BPF_MAP_TYPE_ARRAY | 数组映射,用于保存固定大小的数组 |
| BPF_MAP_TYPE_PROG_ARRAY | 程序数组映射,用于保存BPF程序的引用,适合尾调用(即调用其他 eBPF 程序) |
| BPF_MAP_TYPE_PERF_EVENT_ARRAY | 性能时间数组映射,用于保存性能事件跟踪记录 |
| BPF_MAP_TYPE_PERCPU_HASH BPF_MAP_TYPE_PERCPU_ARRAY | 每个 CPU 单独维护的哈希表和数组映射 |
| BPF_MAP_TYPE_STACK_TRACE | 调用栈跟踪映射,用于存储调用栈信息 |
| BPF_MAP_TYPE_ARRAY_OF_MAPS BPF_MAP_TYPE_HASH_OF_MAPS | 映射数组和映射哈希,用于保存其他映射的引用 |
| BPF_MAP_TYPE_CGROUP_ARRAY | CGROUP 数组映射,用于存储 cgroups引用 |
| BPF_MAP_TYPE_SOCKMAP | 套接字映射,用于存储套接字引用,特别是用于套接字的重定向 |
如果 eBPF 程序使用了 BCC, 那么预定义的宏可以极大简化 BPF 映射相关的操作。比如 c map apis 。除了创建之外,BPF 映射没有删除相关的命令,这是因为 BPF 映射 会在用户态程序关闭时自动删除,如果想要在用户态程序退出时保留映射,需要 BPF_OBJ_PIN 命令,将映射挂载到 /sys/fs/bpf 中。
BPF 类型格式 (BTF)
我们知道不同的内核版本,代码上肯定有细微的差别,比如 文件打开的系统调用,在 v.5.5 之前还是 do_sys_openat 而最新版的内核已经变成了 do_sys_openat2 函数,这显然违背了一次编译,永久执行的初衷。线上生产环境的内核数据结构的定义决定了eBPF 程序是否能正常执行。虽然我们线下安装了 linux-headers-$(uname -r) 内核头文件,但是线上环境一般是不会装的。
这就引入了 BTF (BPF Type Fromat) ,从 v5.2 开始,只要内核开启了 CONFIG_DEBUG_INFO_BTF ,在编译内核时,内核的数据结构会自动嵌入内核的二进制文件 vmlinux 中,可以通过 bpftool 工具导出头文件。
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h所以在开发 eBPF 程序时只需要引入一个 vmlinux.h 即可。除此之外, BTF 可以让 eBPF 程序在内核升级之后,不需要编译就可以直接运行。
解决了内核数据结果的定义问题,接下来的问题就是,如何让 eBPF 程序在内核升级之后,不需要重新编译就可以直接运行,eBPF的一次编译到处执行(Compile Once Run Everywhere,简称 CO-RE) 项目借助了BTF提供的调试信息,通过在 libbpf 中预定义不同内核版本中的数据结构的修改,解决了不同内核中数据结构的不兼容问题。
事件触发
eBPF 对应于内核的事件类型,犹如订阅同类消息事件,内核发现对应的事件,则通知订阅者处理。而 eBPF 程序的类型决定了一个 eBPF 程序可以挂载的事件类型和事件参数。这在内核头文件 include/uapi/linux/bpf.h 中的 bpf_prog_type 定义,不同版本的内核支持程度上略有差异。具体可以使用 bpftool feature probe | grep program_type 查看
$ bpftool feature probe | grep program_type
eBPF program_type socket_filter is available
eBPF program_type kprobe is available
eBPF program_type sched_cls is available
eBPF program_type sched_act is available
eBPF program_type tracepoint is available
eBPF program_type xdp is available
eBPF program_type perf_event is available
...按照具体的功能和应用场景区分,这些程序类型大致可以分为三类:
- 第一类:跟踪 ,即从内核和程序的运行状态中提取跟踪信息
- 第二类:网络,即对网路数据包进行处理过滤
- 第三类:安全,安全控制,BPF 扩展等
跟踪类 eBPF 程序
跟踪类 eBPF 程序主要是用于从系统中提取跟踪信息,进而为监控、排错、性能优化等提供数据支撑。比如前面的第一个程序案例,它是跟踪某个内核函数是否被某个进程调用了。
| 程序类型 | 功能描述 | 功能限制 |
|---|---|---|
| BPF_PROG_TYPE_KPROBE | 用于对特定函数进行动态插桩,根据函数位置的不同,又可以分为内核态 kprobe 和 用户态 uprobe | 内核函数和用户函数的定义属于不稳定API,在不同内核版本中使用时,可能需要调整eBPF代码的实现 |
| BPF_PROG_TYPE_TRACEPOINT | 用于内核静态跟踪点(可以使用 perf list 命令,查询所有的跟踪点) | 虽然跟踪点可以保持稳定性,但不如 KPROBE类型灵活, 不能按需增加新的跟踪点 |
| BPF_PROG_TYPE_PERF_EVENT | 用于性能时间 (perf_events) 跟踪,包括内核调用,定时器,硬件等各类性能数据 | 需要配合 BPF_MAP_TYPE_PERF_EVENT_ARRAY 或者 BPF_MAP_TYPE_RINGBUF 类型的映射使用 |
| BPF_PROG_TYPE_RAW_TRACEPOINT BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE | 用于原始跟踪点 | 不处理参数 |
| BPF_PROG_TYPE_TRACING | 用于开启 BTF 的跟踪点 | 需要开启 BTF |
BCC 软件包中有大量的工具就是借助这类事件跟踪实现的。

网络类 eBPF 程序
网络类 eBPF 程序主要用于对网络数据包的过滤和处理,进而实现网络的观测、过滤、流量控制以及性能优化。一般来说分为 XDP (eXpress Data Path, 高速数据路径) 程序、 TC (Traffic Control, 流量控制) 程序、套接字程序 以及 cgroup 程序。
XPD 程序对应的类型是 BPF_PROG_TYPE_XDP ,它在网络驱动程序刚刚收到数据包时触发执行,由于无需通过复杂的内核网络协议栈,所以 XDP 程序可以用来实现高性能的网络处理方案,常用于 DDos 防御、防护墙、4层负载均衡等
TC程序 对应的类型是 BPF_PROG_TYPE_SCHED_CLS 和 BPF_PROG_TYPE_SCHED_ACT ,分别用于流量控制的分类器和执行器。Linux 流量控制通过网卡队列、排队规则、分类器、过滤器以及执行器实现了网络流量的整形调度和带宽控制。
TC 相关BPF官方文档 https://docs.cilium.io/en/v1.8/bpf/#tc-traffic-control
TC 相关的其他博客文档 eBPF tc 子系统 、设计一个TC程序、深入理解 tc ebpf 的 direct-action 模式
套接字程序
套接字程序用于过滤、观测或重定向套接字网络包。可以将 eBPF 程序挂载到 套接字(socket) 、控制组(cgroup)以及网络命名空间(netns)等各位置上。
后面还有 cgroup 、安全审计、隧道解包相关的事件类型,这里不再赘述。
参考: