理解协程
协程 在如今在高并发场景下最容易提到的一个技术,协程即能暂停执行以在之后恢复的函数。。下面是关于 GCC11 编辑器 对协程的介绍 ( A coroutine is a function that can suspend execution to be resumed later. Coroutines are stackless: they suspend execution by returning to the caller and the data that is required to resume execution is stored separately from the stack. )
试想以下场景,百万级别的高并发场景下,如何实现用户访问静态资源的Web服务,需要的工作如下
- 通过网络调用远程服务来进行身份验证
- 检查Memcache中是否存在相关的资源
- 将请求的资源从磁盘中读取数据放入 HTTP Body的 Buffer中
- 再将访问记录插入到MySQL数据库中。
那么都有哪些技术呢?
- 多进程?进程是操作系统资源分配(内存,显卡,磁盘)的最小单位。多进程面临着 CPU 寄存器和程序计数器等上下文的切换。
- 多线程?线程是执行调度(即cpu调度)的最小单位(cpu看到的都是线程而不是进程)。计算机的cpu物理核数是同时可以并行的线程数量(cpu只能看到线程,线程是cpu调度分配的最小单位) 一个进程可以有一个或多个线程,线程之间共享进程的资源。
如果使用阻塞API写同步代码将最简单,但是一个线程同一时间只能处理一个请求,也就是每新建一个链接就需要新创建一个线程去处理,而CPU在处理越来越多的请求时,会切换线程来服务其他的线程,这样的做法能满足我们高并发的需求吗?
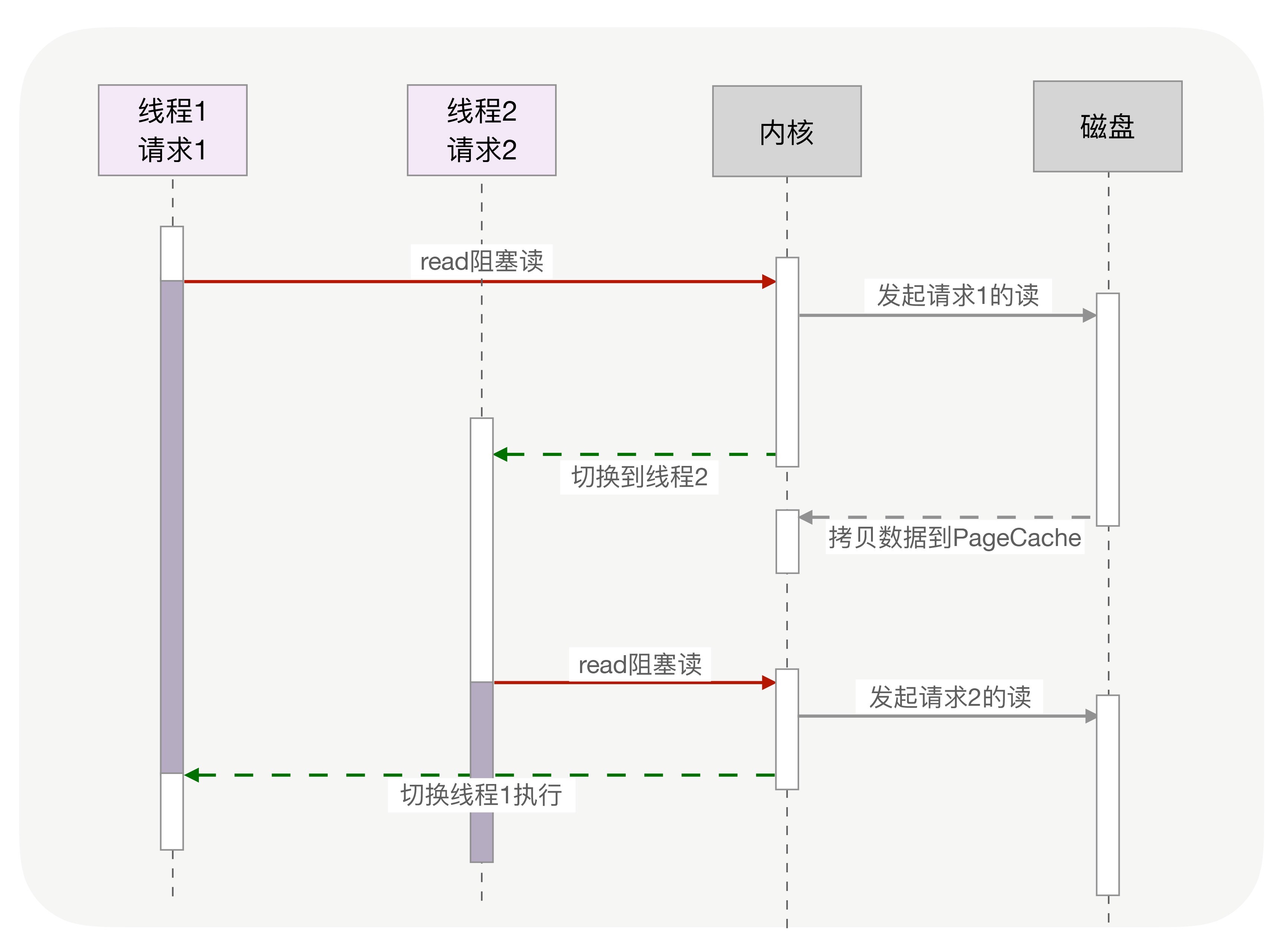
无论是多进程还是多线程都有以下问题。
- 资源消耗的问题: 比如 64 位Linux为每个线程的栈分配了8MB 的内存,C库还预分配了64MB的内存池,在同时存在数十万的连接情况下没有足够的内存开启如此之多的线程。
- 上下文切换:CPU资源消耗,当调度到阻塞的方法时,内核为了让CPU充分工作,也会切换到其他的线程执行 进程的切换会有很多寄存器,堆栈的切换,也会造成缓存命中率差,线程虽然切换会轻量一些,但还是会存在部分私有数据和寄存器数据的切换。一次的切换成本也会在几十纳秒到几微秒间。
那么该怎样实现高并发?如果将本来应该由内核实现的请求切换工作,交给用户态的代码完成就能实现切换成本的降低,异步化改造依赖IO多路复用机制和非阻塞,然而写异步化代码很容易出错。异步化改造需要将阻塞的函数通过非阻塞的系统调用拆分成2个函数,第一个函数显式调用,第二个函数多路复用的调用。所以异步化改造程序是很复杂的。
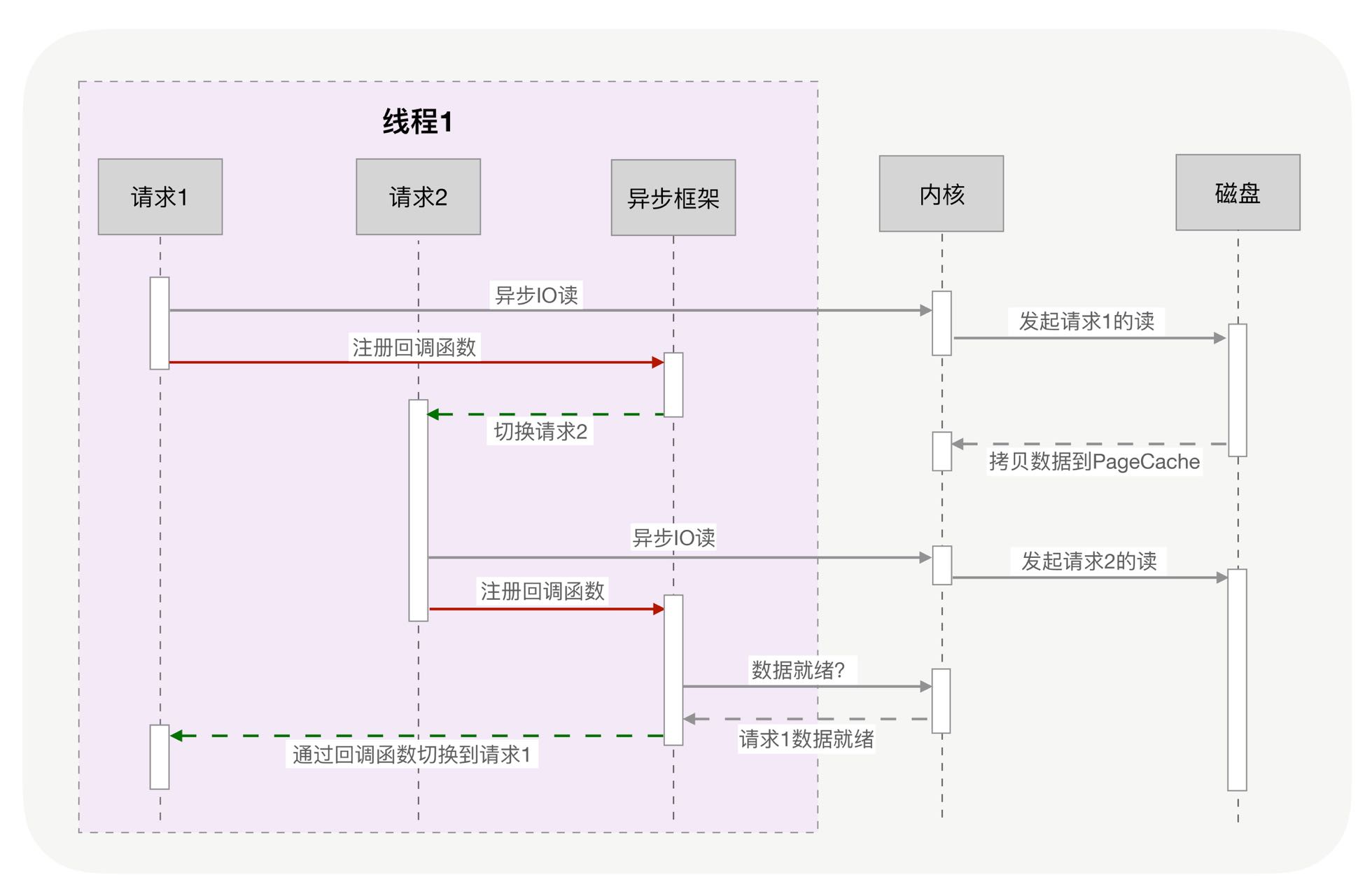
协程
协程出现了,在异步化之上包了一层外衣,这就是异步框架。协程与异步编程的相似的地方在于他们都使用了非阻塞的系统调用与内核交互。把切换请求的实现放到了用户态。不同的地方在于协程把异步化中的两段函数封装成了一个“阻塞的协程函数”。这也是对用户友好的编程格式。函数在执行时,调用的协程无感知的放弃执行权,由协程框架切换到准备就绪的其他协程上。当这个函数满足执行条件时,协程框架再选择合适的时机,切换回它所在的协程执行。
本质
协程不需要什么“回调函数”,它允许用户调用“阻塞的函数”,即用同步编程的方式去写业务逻辑。解决了异步化通过大量的回调函数来完成请求函数的切换的复杂编程方式。
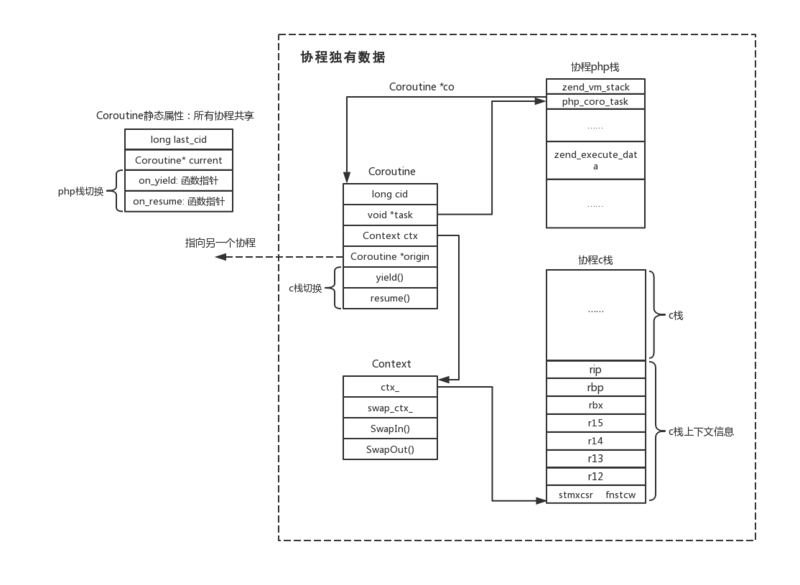 实际上,**用户态的代码协程切换和内核协程切换的原理是一样的**,内核通过管理CPU的寄存器来切换线程,而协程的切换是将内核的工作移到了协程框架实现而已,创建协程时,会从进程的堆中分配一段内存作为协程的栈。线程的栈有8MB,而协程的栈只有几十KB,并且C库的内存池也不会为协程预分配内存,因为它感知不到协程的存在。这样以来协程需要的内存空间就十分少了,几十万的并发也不需要很多的内存消耗
实际上,**用户态的代码协程切换和内核协程切换的原理是一样的**,内核通过管理CPU的寄存器来切换线程,而协程的切换是将内核的工作移到了协程框架实现而已,创建协程时,会从进程的堆中分配一段内存作为协程的栈。线程的栈有8MB,而协程的栈只有几十KB,并且C库的内存池也不会为协程预分配内存,因为它感知不到协程的存在。这样以来协程需要的内存空间就十分少了,几十万的并发也不需要很多的内存消耗当然:栈缩小了,就尽量不要在协程中使用递归函数了
由此可见,协程就是用户态的线程。协程框架在用户空间做了线程切换等内核要做的事情。另外协程封装了所有阻塞的系统调用,例如sleep()函数会让当前的线程休眠,而线程一旦休眠,协程也就无法执行了。(协程是工作于线程之上的)。这就需要内核来唤醒sleep函数,协程化改造之后,sleep()函数只会让当前的协程休眠,由协程框架在指定时间后唤醒协程。
**所以协程的高性能就是建立在所有的切换由用户态代码实现,这就要求协程的生态是完整的,要覆盖所有组件。**如果一个协程框架没有考虑到如sleep()函数的协程化改造,就会造成线程休眠,线程休眠就会造成在线程之上的协程也伴随着休眠。
协程+线程
实际上面对当下服务器动辄几百核的多核CPU架构,线程也就需要和协程结合起来使用,因为协程的载体是线程。而CPU的执行对象是线程,线程在同一时刻只能拥有一颗CPU,那么好的设计是开启更多的线程,然后将协程分布在这些线程之上,这样就能充分的利用CPU资源。
除此之外,为了让协程获得更多的CPU时间,只要所在线程的优先级调高即可,甚至可以将CPU绑定到某个CPU上,增加协程执行时命中CPU的缓存几率。(要知道CPU的三级缓存SRAM是要比内存DRAM快很多的,如果多个线程频繁在不同的CPU切换来切换去就会造成缓存命中率低下,TLB根本起不到作用)
很多的协程库只提供了创建、挂起、恢复执行的基本方法,并没有协程框架的概念出现,这就需要业务在代码中自行实现调度协程。在协程的运行条件不满足需求时,多路复用框架会将它挂起,并根据优先级策略选择另一个协程执行。也就是不只是选择协程库,还需要结合IO多路复用的协程框架,这样就可以加快开发的速度。
比如OpenResty中的cosocket,cosocket = coroutine + socket ,cosocket利用lua的协程特性支持,又结合了Nginx事件机制。遇到网络I/O就会交出控制权(yield),把网络事件注册到Nginx的事件监听表中,并把权限重新交给Nginx,当有Nginx事件达到触发条件,会唤醒对应的协程继续处理(resume)
golang协程
Go在语言级别支持了协程(Goroutine)来实现高并发。作为程序员不必再考虑 像Python 那样引入一个异步协程库,利用其代码来实现异步协程化。
Goroutine天生对协程的完美支持,也让Goroutine传承了协程本身的优良特性。 Goroutine堆栈只有几十kb。如果某一线程之上的协程不幸发生阻塞,那么系统可以将其与协程移动到新的线程上执行,这一切不用程序员关心。多个协程之间通信的管道。信道可以防止多个协程访问共享内存时发生资源争抢的问题。(但是注意:多个goroutine 访问一个map时一定需要加锁!!)
在GO1.14之前golang的协程还是非抢占式调度.而在1.14之后,协程添加了一个重要的特性便是抢占式调度。
- 非抢占式调度
非抢占式的含义就是其他任务不会抢我的cpu,而是等待我主动让出去。别的goroutine才可以执行。而io等操作会主动让出去goroutine的执行权。如下:
func main() {
var a [20]int
for i := 0;i< 20;i++{
go func(i int) {
for {
a[i]++
}
}(i)
}
time.Sleep(time.Second)
fmt.Println(a)
}在1.13 版本下的Go SDK 执行
➜ go version
go version go1.13.14 linux/amd64
➜ go run main.go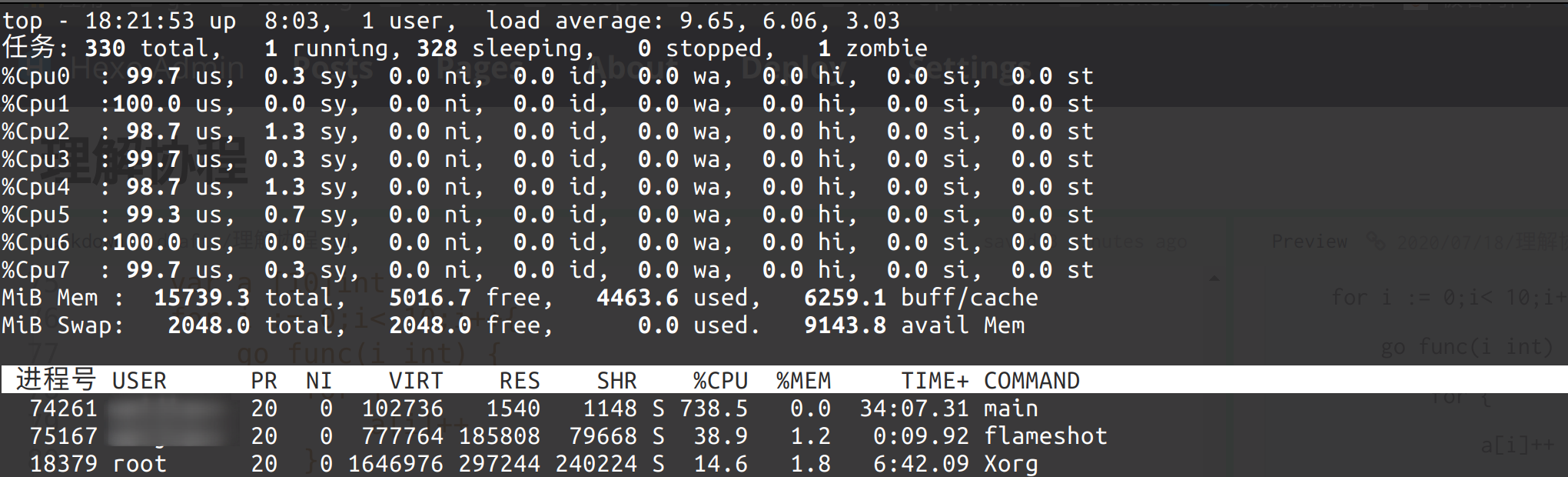
这个程序会卡住。因为main函数也是一个goroutine。而程序中对一个变量++ 是不会交出控制权的(io操作可以交出控制权,如fmt.println,一次IO系统调用等,或者手动交出控制权runtime.Gosched()),所以main也得不到运行了,可以看到这段程序死机了。可以看到,我是8核CPU,这个程序在执行时发生了死循环,占用CPU 738%(约等于800%)对应8个核。
- 抢占式调度
Go1.14 引入了基于系统信号的抢占式调度, 在抢占式情况下,如果一个goroutine运行时间过长,它就会被剥夺运行权。
➜ go version
go version go1.14.5 linux/amd64
➜ go run main.go
[223473156 204013472 207617086 235368900 147990153 216776090 245417848 278086836 299956269 268087158]这次用1.14 的go sdk可以看到程序快速的输出了最终的答案,抢占式下,一个goroutine不能一直占CPU不放。
垃圾回收器是需要stop the world的。如果垃圾回收器想要运行了,那么它必须先通知其它的goroutine合作停下来,这会造成较长时间的等待时间。考虑一种很极端的情况,所有的goroutine都停下来了,只有其中一个没有停,那么垃圾回收就会一直等待着没有停的那一个。(非抢占式存在这种情况,而抢占式不存在)
Golang GMP模型
Go 的调度器内部有三个十分重要的结构,M,P,G
- M 表示真正的内核OS线程,和POSIX里的thread差不多,真正干活的人。
- P 局部的调度器,使 go 代码在一个线程上跑,它是实现从N:1 (多个用户线程在一个内核线程上跑)到 N:M 映射的关键。由启动时环境变量 $GOMAXPROCS 或者是由runtime.GOMAXPROCS() 决定。这意味着在程序执行的任意时刻都只有 $GOMAXPROCS 个 goroutine 在同时运行。
- G 代表一个 goroutine,它有自己的栈,用于调度。理论上没有数量上限限制的。查看当前G的数量可以使用 runtime.NumGoroutine()
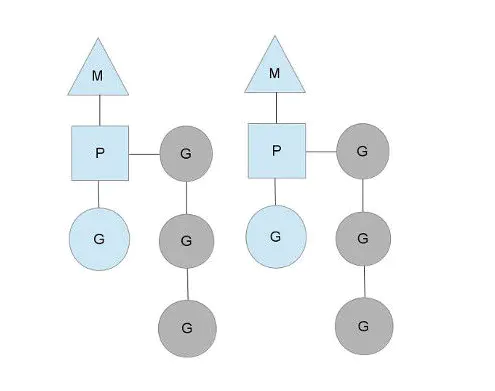
上图表示有两个物理线程M,每个M都拥有一个context(P),每一个P上又拥有一个正在运行的G和很多等待运行的G。 P 的总数量可以通过 GOMAXPROCS() 设置。它表示真正的并发量,即有多少个goroutine可以同时运行。 上面等待的(灰色)goroutine处于ready的就绪态。而每个P都维护着一个队列(runqueue)
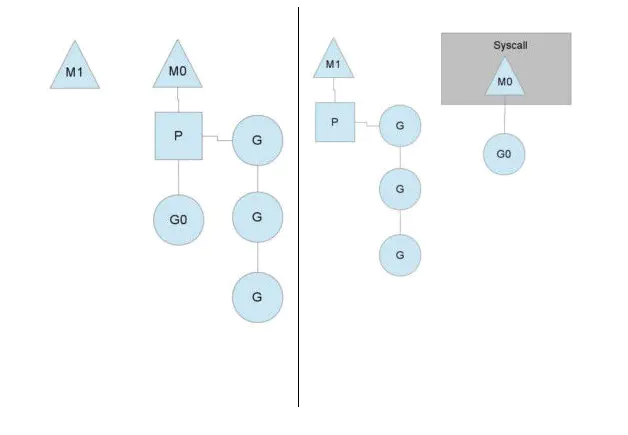
当一个OS线程M0陷入阻塞时(如上图),P转而在运行M1,图中的M1可能是正被创建,或者从线程缓存中取出。
当MO返回时,它必须尝试取得一个P来运行goroutine,一般情况下,它会从其他的OS线程那里拿一个P过来, 如果没有拿到的话,它就把goroutine放在一个global runqueue里,然后自己睡眠(放入线程缓存里)。所有的P也会周期性的检查global runqueue并运行其中的goroutine,否则global runqueue上的goroutine永远无法执行。
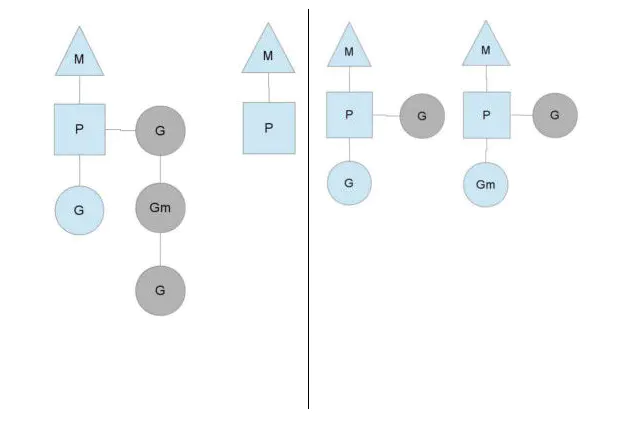
某一个P所分配的任务G很快被执行完了(分配不均),这就导致一个context P 闲着,如果 global runqueue 上没有 G 了,那么它会偷其他P 的G。一般偷的话会偷一半。确保每个OS线程都能得到充分的使用。
这段参考知乎 Golang 的 goroutine 是如何实现的? Yi Wang 的回答
GOMAXPROCS–性能调优
GOMAXPROCS 就是 go 中 runtime 包的一个函数。它设置了 P 的最多的个数。这也就直接导致了 M 最多的个数是多少,而 M 的个数就决定了各个 G 队列能同时被多少个 M 线程来进行调取执行! 故,我们一般将 GOMAXPROCS 的个数设置为 CPU 的核数,且需要注意的是:
go 1.5 版本之前的 GOMAXPROCS 默认是 1 go 1.5 版本之后的 GOMAXPROCS 默认是 Num of cpu
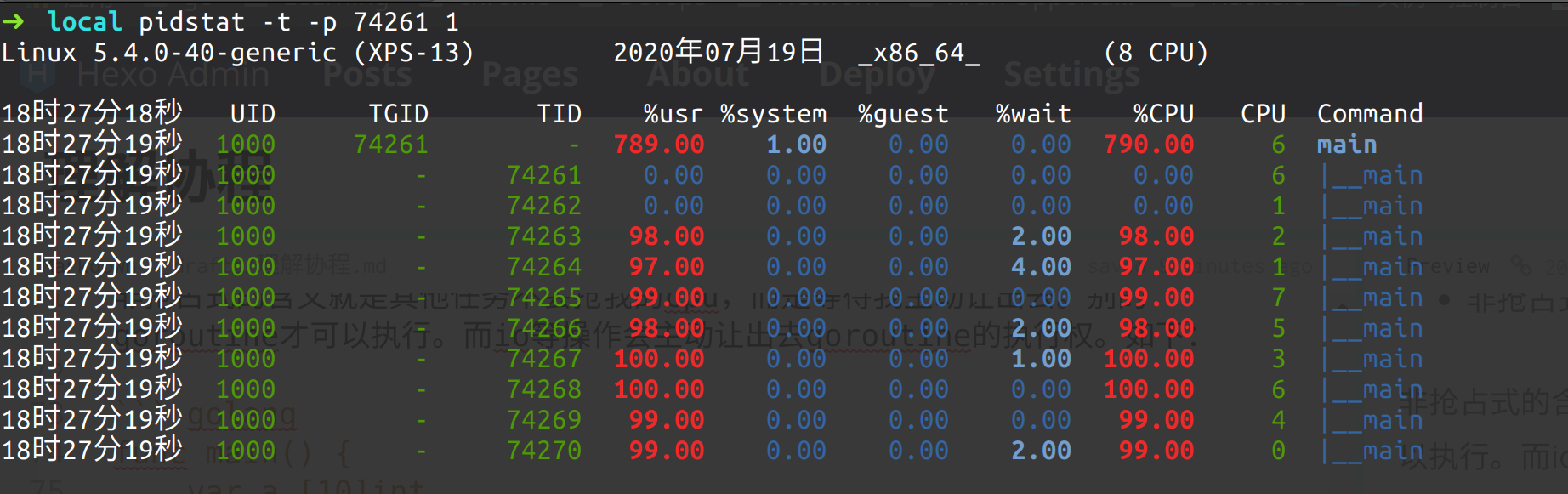
以刚才上面的代码为例。我是8核CPU,这里的线程却创建了10个线程,TID 为74261和74262 是空闲的。而实际跑的是8个线程,这对应了 20 个 G (goroutine)、10个M、8个P。
(如下图)
还有其他语言的异步协程库,比如python通过 syncio 包实现协程,而c++也有阿里大神多隆写的 libeasy 。但是都不如 go 的原生支持来的方便。