操作系统知识汇总
最常见的指标有可能是最容易遗漏和忽视的,以前面试的过程中经常被问到一些问题定位排查的运维问题,但是一些经常耳熟能详的名词被深究问下去就不知所以了。 比如:1. 系统负载如何查看?系统负载高的原因都有可能是哪些? 什么是系统负载? 2. swap 是什么?为什么kubernetes建议禁用 swap 等。
下面做一些总结
CPU 性能篇
平均负载
平均负载是指单位时间内,系统处于 可运行状态 和 不可中断状态 的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
可运行状态的进程 :是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。
不可中断状态的平均进程数 :正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程。
举个例子:进程读取的磁盘设备是一个远程的NFS,若网络出现异常,则读取数据的进程将处于D状态。
常见的 CPU 指标排查工具, top、mpstat、pidstat、uptime
mpstat是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标
# -P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据
$ mpstat -P ALL 5
Linux 5.4.0-81-generic (XPS-13) 2022年02月05日 _x86_64_ (8 CPU)
09时07分33秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
09时07分34秒 all 1.98 0.00 9.64 0.00 0.00 1.85 0.00 0.00 0.00 86.53
09时07分34秒 0 0.95 0.00 7.62 0.00 0.00 7.62 0.00 0.00 0.00 83.81pidstat是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
$ pidstat -u 1 3
Linux 5.4.0-81-generic (XPS-13) 2022年02月05日 _x86_64_ (8 CPU)
09时10分01秒 UID PID %usr %system %guest %wait %CPU CPU Command
09时10分02秒 0 1129 10.89 4.95 0.00 0.00 15.84 2 Xorg
09时10分02秒 65534 1451 0.00 0.99 0.00 0.00 0.99 1 dnsmasq
09时10分02秒 1000 2222 8.91 1.98 0.00 0.00 10.89 3 budgie-wm上下文切换
CPU 上下文切换,是保证 Linux 系统正常工作的核心功能之一,一般情况下不需要我们特别关注。但过多的上下文切换,会把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降。
举个例子:一个进程从磁盘上读取文件,需要经历以下几个步骤。1. 进程调用read函数,这次系统调用,进程从用户态切换到内核态。2. 内核将文件从磁盘copy至PageCache 3. 内核态将文件从PageCache Copy至用户态缓冲区并从内核态退出至应用态。
过程进行了2次上下文切换,上述上下文切换的成本并不小,虽然一次切换仅消耗几十纳秒到几微秒,但高并发服务会放大这类时间的消耗。
常见的上下文切换排查工具, vmstate、pidstat、dstat
vmstat是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数。
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b 交换 空闲 缓冲 缓存 si so bi bo in cs us sy id wa st
0 0 1892716 501456 451344 7964228 0 1 22 53 0 9 4 9 87 0 0
0 0 1892716 442916 451344 8022548 0 0 16 0 4518 9028 5 11 84 0 0
cs(context switch)是每秒上下文切换的次数。in(interrupt)则是每秒中断的次数。r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。b(Blocked)则是处于不可中断睡眠状态的进程数。
pidstat 加上 -w 参数,可以显示自愿上下文切换和非自愿上下文切换。(查看线程的上下文切换时添加参数 -t)
$ pidstat -w
Linux 5.4.0-81-generic (XPS-13) 2021年08月28日 _x86_64_ (8 CPU)
17时08分16秒 UID PID cswch/s nvcswch/s Command
17时08分16秒 0 1 0.28 0.05 systemd
17时08分16秒 0 2 0.02 0.00 kthreadd
- 自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
- 非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
CPU 使用率
CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比。
常见的CPU使用率查看工具:top、perf、ps
top: 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况perf: Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
# -g开启调用关系分析,-p指定php-fpm的进程号21515
$ perf top -g -p 21515僵尸进程
僵尸进程表示进程已经退出,但它的父进程还没有回收子进程占用的资源。短暂的僵尸状态我们通常不必理会,但进程长时间处于僵尸状态,就应该注意了,可能有应用程序没有正常处理子进程的退出。
解决僵尸进程的方法。既然僵尸进程是因为父进程没有回收子进程的资源而出现的,那么,要解决掉它们,就要找到它们的根儿,也就是找出父进程,然后在父进程里解决。
# -a 表示输出命令行选项
# p表PID
# s表示指定进程的父进程 (如下图是查看 Nginx worker进程 父进程的方法)
$ pstree -aps 1090
systemd,1 splash
└─nginx,1086
└─nginx,1090守护进程
守护进程(daemon)是生存期长的一种进程,没有控制终端。它们常常在系统引导装入时启动,仅在系统关闭时才终止。UNIX系统有很多守护进程,守护进程程序的名称通常以字母“d”结尾:例如,syslogd 就是指管理系统日志的守护进程。
MEM 性能篇
内存分配与回收
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()。
- 对小块内存(小于 128K),C 标准库使用 brk() 来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。
- 大块内存(大于 128K),则直接使用内存映射 mmap() 来分配,也就是在文件映射段找一块空闲内存分配出去。
当这两种调用发生后,其实并没有真正分配内存。这些内存,都只在首次访问时才分配,也就是通过缺页异常进入内核中,再由内核来分配内存。
整体来说,Linux 使用 伙伴系统(buddy system) 来管理内存分配。伙伴系统也一样以页为单位来管理内存,并且会通过相邻页的合并,减少内存碎片化(比如 brk 方式造成的内存碎片)。在内核空间,Linux 则通过 slab 分配器 来管理小内存。你可以把 slab 看成构建在伙伴系统上的一个缓存,主要作用就是分配并释放内核中的小对象。
系统也不会任由某个进程用完所有内存。在发现内存紧张时,系统就会通过一系列机制来回收内存,比如下面这三种方式:
- 回收缓存,比如使用 LRU(Least Recently Used)算法,回收最近使用最少的内存页面;
- 回收不常访问的内存,把不常用的内存通过交换分区直接写到磁盘中;
- 杀死进程,内存紧张时系统还会通过 OOM(Out of Memory),直接杀掉占用大量内存的进程。
操作系统中内存的类型
- 文件页: 系统释放掉可以回收的内存,比如缓存和缓冲区,就属于可回收内存。它们在内存管理中,通常被叫做
文件页(File-backed Page)。 - 脏页:大部分文件页,都可以直接回收,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。
- 匿名页: 应用程序动态分配的堆内存
swap
Swap 就是把一块磁盘空间或者一个本地文件(以下讲解以磁盘为例),当成内存来使用。
有新的大块内存分配请求,但是剩余内存不足。这个时候系统就需要回收一部分内存(比如前面提到的缓存),进而尽可能地满足新内存请求。这个过程通常被称为直接内存回收。
除了直接内存回收,还有一个专门的内核线程用来定期回收内存,也就是 kswapd0。为了衡量内存的使用情况,kswapd0 定义了三个内存阈值(watermark,也称为水位),分别是页最小阈值(pages_min)、页低阈值(pages_low)和页高阈值(pages_high)。剩余内存,则使用 pages_free 表示。
kswapd0 定期扫描内存的使用情况,并根据剩余内存落在这三个阈值的空间位置,进行内存的回收操作。
- 剩余内存小于页最小阈值,说明进程可用内存都耗尽了,只有内核才可以分配内存。
- 剩余内存落在页最小阈值和页低阈值中间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值为止。
- 剩余内存落在页低阈值和页高阈值中间,说明内存有一定压力,但还可以满足新内存请求。
- 剩余内存大于页高阈值,说明剩余内存比较多,没有内存压力。
- 对文件页的回收,当然就是直接回收缓存,或者把脏页写回磁盘后再回收。
- 对匿名页的回收,其实就是通过 Swap 机制,把它们写入磁盘后再释放内存。
Linux 提供了一个 /proc/sys/vm/swappiness 选项,用来调整使用 Swap 的积极程度。但是即便设置为0也不是关闭 swap 的意思,真正的关闭swap需要设置 swapoff -a 和在 /etc/fstab 中注释掉swap分区的挂载。
swapd 占用 CPU 过高怎么办?
场景: 本人打开 chrome 浏览器,大约10个tab,新打开 bilibili 网站时,笔记本的电脑的CPU呼呼的转,瞬间电脑卡死了,终端很难调起来。另外chrome浏览器直接卡崩溃了。
下意识的以为是一些后台更新程序占用CPU导致的,
执行 htop 看到 chrome 进程耗CPU 140% 稍微有些高,但我是8核CPU。140% 应该不算什么。其余可能就 vmware 的虚拟机进程耗费CPU稍微高一些了。
执行 mpstat 命令。这下知道是什么原因了。系统进程耗费CPU高?另外 iowait 也不高
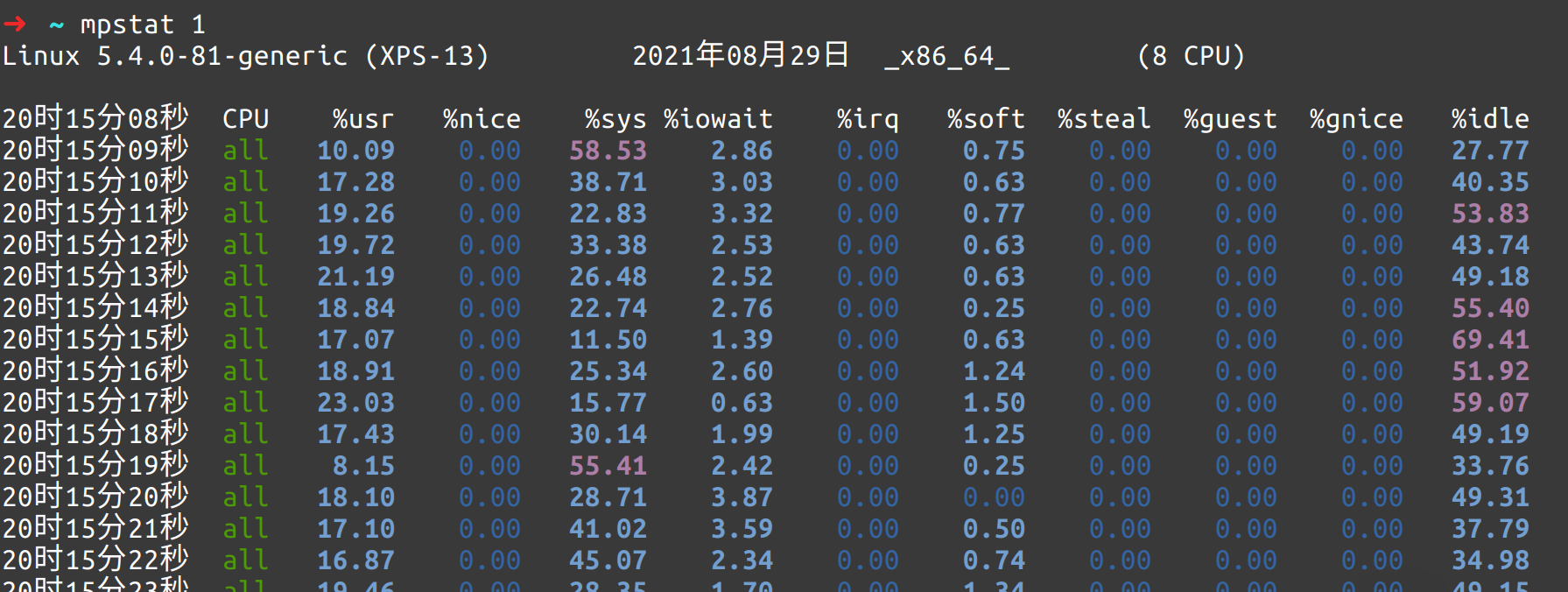
执行 pidstat -u 1 ,看到了是什么进程在耗费CPU,罪魁祸首就是 swapd 进程。
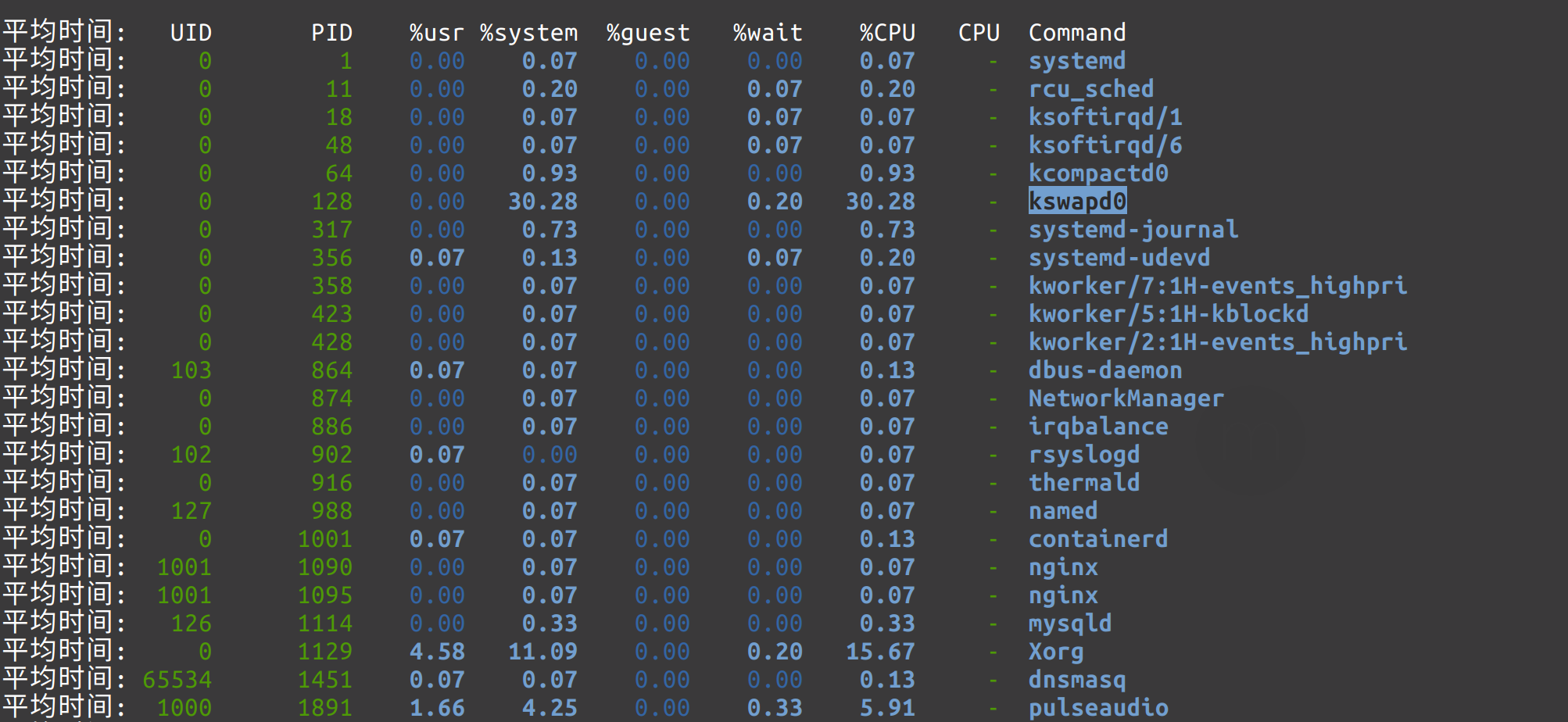
原来 swap 已经满了。但是,可以看到我的空闲内存还有 4个G , 但这并不影响操作系统把swap用满,我猜测是 chrome 浏览器长时间不用,相关的匿名页给我换进swap里了,突然猛的打开chrome浏览器,又是播放 4K 视频,就给我卡死了。

即便我的 swapness 设置的是 0 ,
$ cat /proc/sys/vm/swappiness
0查看swap中都是哪些进程在用的内存。
for file in /proc/*/status ; do awk '/VmSwap|Name|^Pid/{printf $2 " " $3}END{ print ""}' $file; done | sort -k 3 -n -r | head解决方式,直接关了swap 。不过我执行了下面的命令,电脑直接卡死重启了。。。。
swapoff -a && swapon -aIO 性能篇
要介绍 IO 性能的相关问题,需要先知道Linux 的文件系统是怎样工作的。
同 CPU、内存一样,磁盘和文件系统的管理,也是操作系统最核心的功能。
- 磁盘为系统提供了最基本的持久化存储。
- 文件系统则在磁盘的基础上,提供了一个用来管理文件的树状结构。
文件系统,本身是对存储设备上的文件,进行组织管理的机制。组织方式不同,就会形成不同的文件系统。
一个操作系统由 引导块(Boot Blocks)、超级块(Super Blocks)、索引节点(Index List)和数据块(Data)组成。
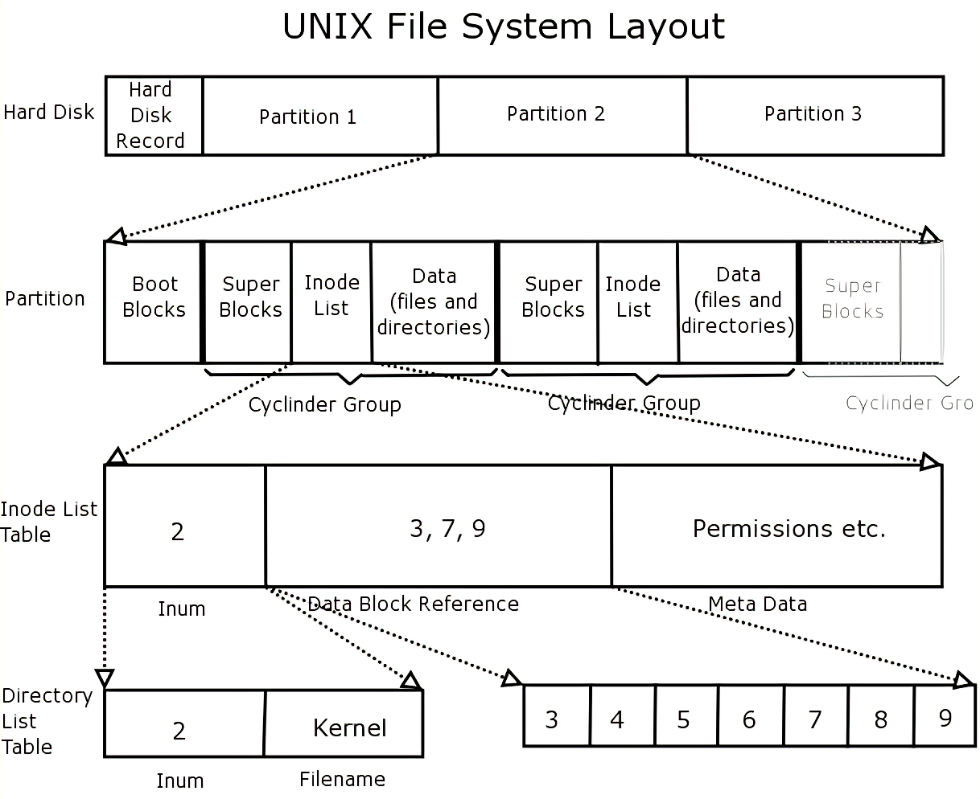
其中我们超级块是存储文件系统的元数据,我们无需关心, Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。它们主要用来记录文件的元信息和目录结构。这个是重点。
- 索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
- 目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
目录项、索引节点、逻辑块以及超级块,构成了 Linux 文件系统的四大基本要素。不过,为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,只需要跟 VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
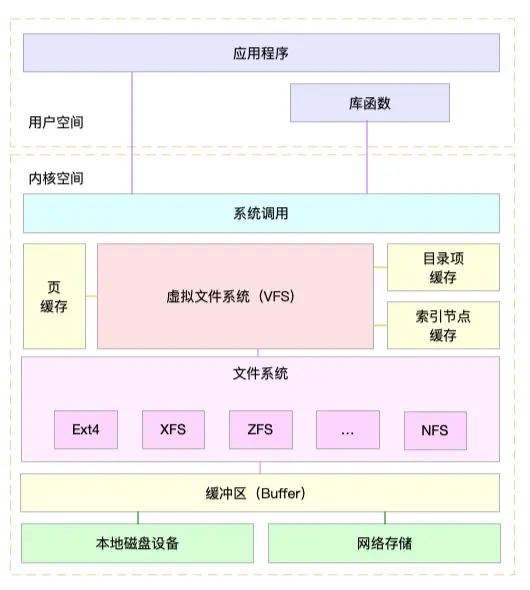
把文件系统挂载到挂载点后,你就能通过挂载点,再去访问它管理的文件了。VFS 提供了一组标准的文件访问接口。这些接口以系统调用的方式,提供给应用程序使用。
回到之前的问题,磁盘IO会有什么情况的瓶颈呢?
IOPS
IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。 常见的磁盘IO的性能问题都和这个有关。过多的IO读写可能会导致读写变缓慢。
使用命令 iotop 可以观察到整体系统的io情况,也可以看到是哪个进程的io占比比较高。
$ iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 7.85 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
15055 be/3 root 0.00 B/s 7.85 K/s 0.00 % 0.00 % systemd-journald