性能大杀器epoll
C10K 单机同时处理 1万个请求(并发连接 1 万)的问题,最早由 Dan Kegel 在 1999 年提出。那时的服务器还只是 32 位系统,运行着 Linux 2.2 版本(后来又升级到了 2.4 和 2.6,而 2.6 才支持 x86_64),只配置了很少的内存(2GB)和千兆网卡。在这样的系统能实现C10K问题吗?
这在当年看似十分难以实现的问题,在当下epoll这个性能大杀器实现了我们单机并发10K的梦想。

C10K
怎么实现单机并发 1W 条连接呢?我们先来算一笔账,对于一台 通用型g6 (2核 8G 25 Gbit/s) 的 ECS 来说。假设每条连接分配100KB内存,100Kbit带宽。1w 条连接也完全满足需求 1G内存,1000Mbit。硬件满足需求,那么看软件。
- 每一条连接创建一个线程吗?
64 位的 Linux 为每个线程的栈分配了 8MB 的内存,还预分配了 64MB 的内存作为堆内存池。单个线程的创建消耗过高,所以我们没有足够的内存创建上万级别的线程。
其次请求的切换,是Linux在内核中切换线程实现的。时间片用尽、调用阻塞方法都会导致线程切换,一次上下文的耗时在几十纳秒,但是短时间上万次的切换,会导致CPU大量的时间都浪费在切换线程上。
总上所述,每条连接创建一个线程是不合理的。(同理创建进程就更不合理了)
I/O 模型优化
这里就需要用到 多路复用/非阻塞 的IO框架模型了,那么什么是多路/非阻塞。 通俗来讲就是就是将很多的IO事件都收集起来统一管理,这样一个线程就可以做到分别运行不同的IO事件,哪个准备好了运行哪个。没有准备好的就先放在一边。
IO 事件的类型非常多,比如: 1、标准输入文件描述符可读。2、标准输出文件描述符可写。3、新的连接建立成功。4、一个IO事件等待超过了10秒
IO 事件是如何产生的
简单的说,事件只有两种即读事件和写事件。读事件表示IO有消息到达需要处理,写事件 表示IO可以发送数据了(TCP的写缓冲区可写数据)。
在网络的视角,从三次握手开始。客户端发出SYN,服务端回复SYN+ACK。完成握手后,客户端即产生了写事件。如果缓冲区太小假设只有1M,而我们要发送的数据时2M,那么会先写入1M后,等待缓冲区空闲后,再次产生写事件。
同样四次挥手,当主动关闭方发送一个FIN,被动关闭方就会产生一个读事件。
目前磁盘的异步IO技术还不成熟,它绕过了 PageCache 性能损失很大。所以当下的事件驱动,主要就是指网络事件。
IO 类型
事件如何通知
目前有两种 IO事件的通知方式水平触发和边缘触发
水平触发:只要文件描述符可以非阻塞的执行IO,就会触发通知,也就是应用程序可以随时随地的检查文件描述符的状态,并根据其状态产生相应的动作。边缘触发:只有文件描述符的状态发生改变时,才发出一个通知,这时候应用程序需要尽可能多的执行IO操作,直到无法继续读写,才可以停止。如果 I/O 没执行完,或者因为某种原因没来得及处理,那么这次通知也就丢失了。
IO 调用方式分哪几类
非阻塞: 当应用程序调用阻塞 I/O 完成某个操作时,应用程序会被挂起,等待内核完成操作阻塞: 当应用程序调用非阻塞 I/O 完成某个操作时,内核立即返回,不会把 CPU 时间切换给其他进程,应用程序在返回后,可以得到足够的 CPU 时间继续完成其他事情。
非阻塞IO+水平触发
select
select 用法
- 声明select函数
int select(int maxfd, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout);
返回:若有就绪描述符则为其数目,若超时则为0,若出错则为-1maxfd 表示的是待测试的描述符基数,它的值是待测试的最大描述符加 1。
- 设置描述字符集合
分别是读描述符集合 readset、写描述符集合writeset 和 异常描述符集合 exceptset,这三个分别通知内核,在哪些描述符上检测数据可以读,可以写和有异常发生。
void FD_ZERO(fd_set *fdset); #FD_ZERO 用来将这个向量的所有元素都设置成 0;
void FD_SET(int fd, fd_set *fdset); #FD_SET 用来把对应套接字 fd 的元素,a[fd]设置成 1;
void FD_CLR(int fd, fd_set *fdset); #FD_CLR 用来把对应套接字 fd 的元素,a[fd]设置成 0;
int FD_ISSET(int fd, fd_set *fdset); #FD_ISSET 对这个向量进行检测,判断出对应套接字的元素 a[fd]是 0 还是 1。其中 0 代表不需要处理,1 代表需要处理。
最后一个参数是 timeval 结构体时间。
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
};超时事件,如果全是0,则立马返回不等待(基本没有这么用的)、非0值等待一段时间后返回,可以用作超时、NULL一直监听等待有返回。
- select 程序例子
refer:https://github.com/froghui/yolanda/blob/master/chap-22/nonblockingserver.c
while (1) {
...
if (select(maxfd + 1, &readset, &writeset, &exset, NULL) < 0) {
error(1, errno, "select error");
}
// 处理监听套接字事件
if (FD_ISSET(listen_fd, &readset)) {
...
}
// 处理已建立好连接上的套接字事件
for (i = 0; i < maxfd + 1; ++i) {
int r = 0;
if (i == listen_fd)
continue;
if (FD_ISSET(i, &readset)) {
r = onSocketRead(i, buffer[i]);
}
if (r == 0 && FD_ISSET(i, &writeset)) {
r = onSocketWrite(i, buffer[i]);
}
if (r) {
buffer[i]->connect_fd = 0;
close(i);
}
}
...
}select 缺点
1、在 Linux 系统中,select 所支持的文件描述符的个数是有限的,默认最大值为 1024。(当然就不能做到 c10K 了) 2、应用程序每次调用 select 时,还需要把文件描述符的集合,从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
c10K 还好一点,当c10M时,并发1 千万连接。若每个 socket 是 4 字节,那么 1 千万连接就是 40M 字节。这样,每收集一次事件,就需要从用户态复制 40M 字节到内核态。而且,高性能 Server 必须及时地处理网络事件,所以每隔几十毫秒就要收集一次事件,性能消耗巨大。
poll
poll用法
- 声明poll函数
int poll(struct pollfd *fds, unsigned long nfds, int timeout);
返回值:若有就绪描述符则为其数目,若超时则为0,若出错则为-1和select不同,poll每次检查完,不会修改之前的传入值,这样就不需要每次检查完毕还需要重置带检测的套结字。poll 还有一个相比select的好处,对请求出错有更友好的检测。
- poll 服务端程序例子
refer: https://github.com/froghui/yolanda/blob/master/chap-21/pollserver.c
poll缺点
还是同select一样,需要将用户空间的套结字复制到内核态。消耗内存资源。
非阻塞IO + 边缘触发
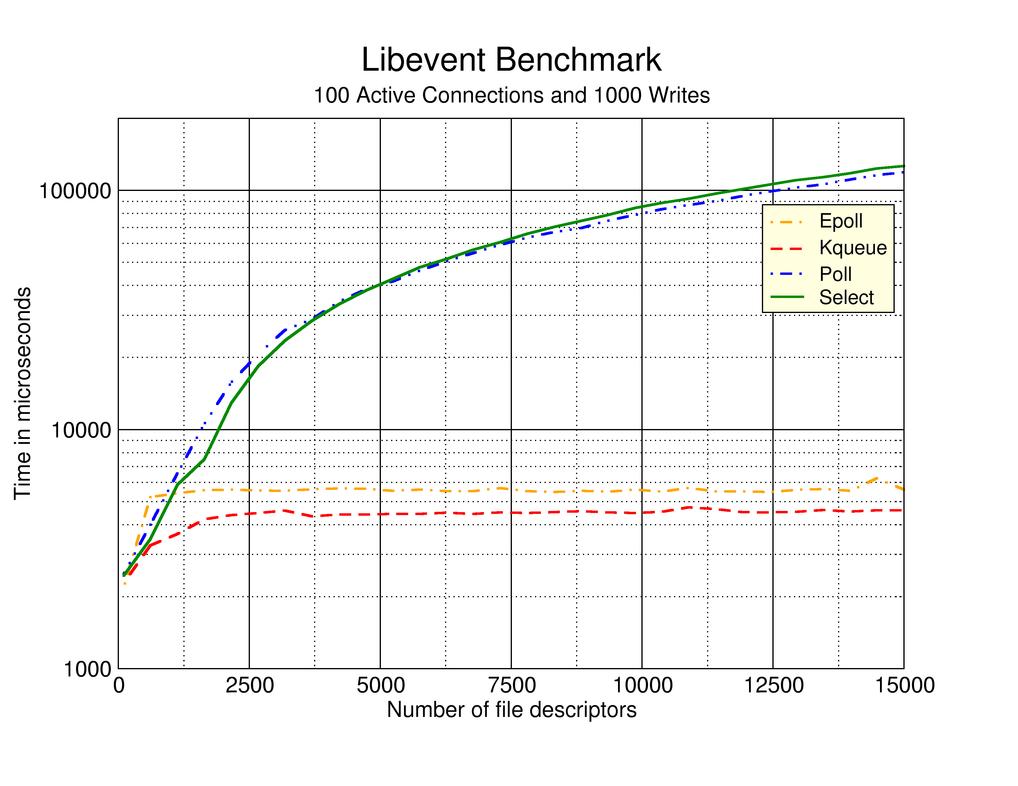
首先看看上面的图,随着文件描述符的增多,poll和select的性能越来越差,而epoll和kqueue却几乎没有什么变化。为什么呢?
解答上面的疑问之前需要知道 五中最常见的 IO 模型。阻塞IO (blocking I/O)、非阻塞IO (nonblocking I/O)、IO多路复用 (I/O multiplexing )、事件驱动IO (signal driven I/O (SIGIO)) 、异步IO (asynchronous I/O (the POSIX aio_functions)) 。具体的网上的例子太多了,图也太多了,这里就不再赘述了。可以参考下这篇文章。各种IO复用模式之select,poll,epoll,kqueue,iocp分析
这5种IO模型如下图,越靠右,性能越强。当然还有更厉害的性能大杀器 AIO (比epoll 更强),这个之后再介绍。很可惜,真正强大的AIO 是 windows 的IOCP(windows服务器有人用吗?你懂得)。而Linux aio 系列函数是由 POSIX 定义的异步操作接口,可惜的是,Linux 下的 aio 操作,不是真正的操作系统级别支持的,它只是由 GNU libc 库函数在用户空间借由 pthread 方式实现的,而且仅仅针对磁盘类 I/O,套接字 I/O 不支持。自出现就备受社区诟病。但是Linux作为最常用的应用服务器,epoll也就是Linux下最常见的性能杀器。
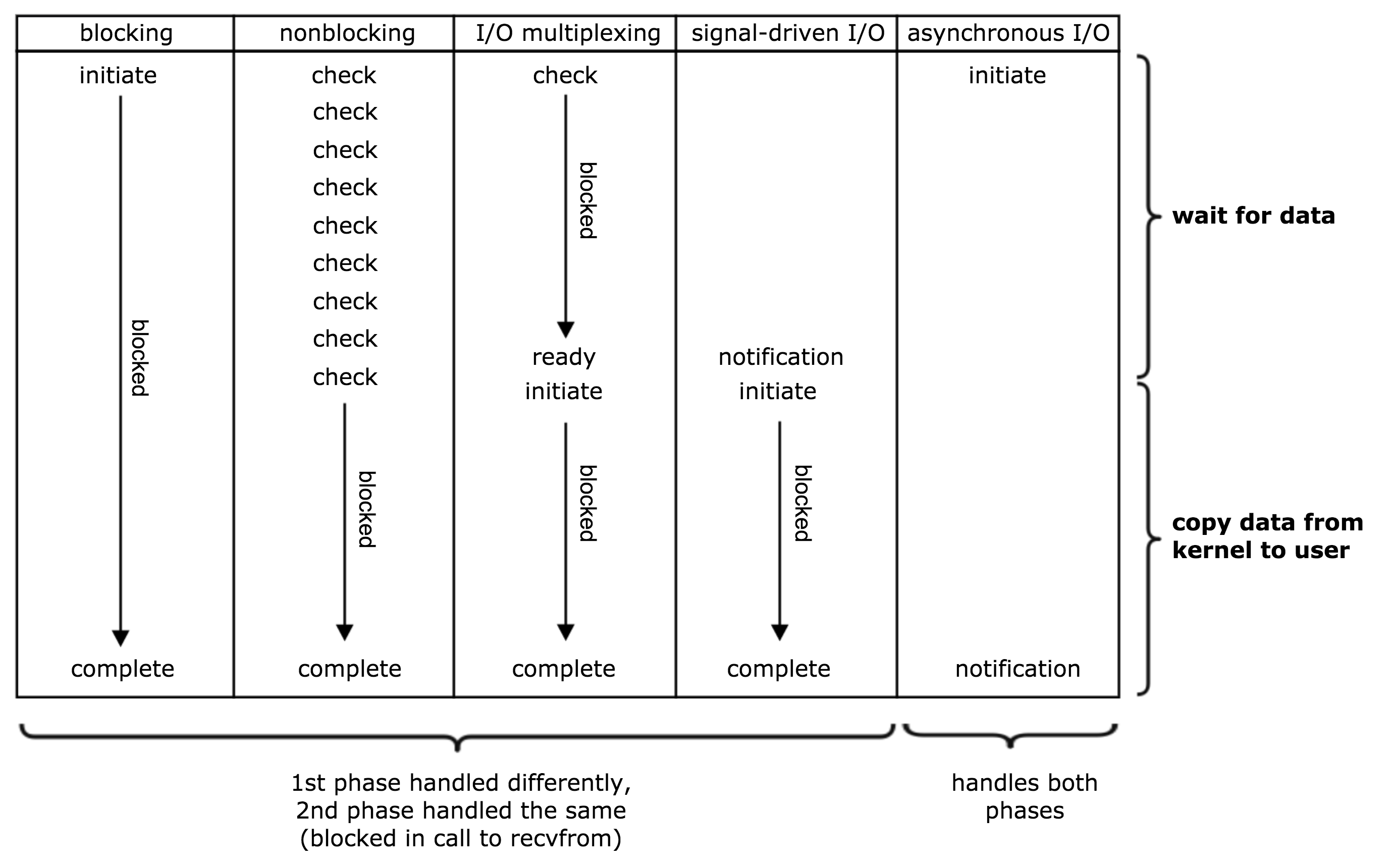
noblocking+I/O mutiplexing(IO多路复用+非阻塞IO) 就是kqueue、epoll、select、poll的实现。 不过epoll 和 kqueue 比 select 和poll 强大的多。
Q:为什么 epoll、kqueue 比 select、poll
A: 因为epoll他们无轮询。他们用callback取代了。想想看,当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数或者直接告诉应用层具体哪些套接字处于活跃状态了,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。
epoll
使用 epoll 进行网络程序的编写,需要三个步骤,分别是 epoll_create,epoll_ctl 和 epoll_wait。
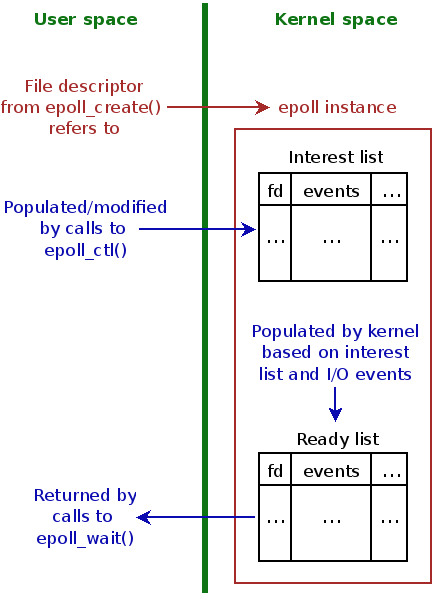
epoll_create
int epoll_create(int size);
int epoll_create1(int flags);
返回值: 若成功返回一个大于0的值,表示epoll实例;若返回-1表示出错关于这个参数 size,在一开始的 epoll_create 实现中,是用来告知内核期望监控的文件描述字大小,然后内核使用这部分的信息来初始化内核数据结构,在新的实现中,这个参数不再被需要,因为内核可以动态分配需要的内核数据结构。每次将 size 设置成一个大于 0 的整数就可以了。
epoll_ctl
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
返回值: 若成功返回0;若返回-1表示出错参数
- epfd:epoll_create 返回的句柄
- op: 添加、删除、修改文件描述符。
- fd: 注册事件的文件描述符
- epoll_event: 注册的事件类型
epoll_event:
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};- EPOLLIN:表示对应的文件描述字可以读;
- EPOLLOUT:表示对应的文件描述字可以写;
- EPOLLRDHUP:表示套接字的一端已经关闭,或者半关闭;
- EPOLLHUP:表示对应的文件描述字被挂起;
- EPOLLET:设置为 edge-triggered,默认为 level-triggered。
epoll_wait
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
返回值: 成功返回的是一个大于0的数,表示事件的个数;返回0表示的是超时时间到;若出错返回-1.调用者进程被挂起,等待内核的IO事件分发
参数:
- epfd:epoll句柄
- epoll_event: 返回用户空间需要处理的epoll事件列表,是个数组。
- maxevents: 返回的最大事件值
- timeout:超时时间
实例
int main(int argc, char **argv) {
int listen_fd, socket_fd;
int n, i;
int efd;
struct epoll_event event;
struct epoll_event *events;
listen_fd = tcp_nonblocking_server_listen(SERV_PORT);
efd = epoll_create1(0);
if (efd == -1) {
error(1, errno, "epoll create failed");
}
/* 注册event事件,事件可读,边缘触发 */
event.data.fd = listen_fd;
event.events = EPOLLIN | EPOLLET;
/* 添加事件 */
if (epoll_ctl(efd, EPOLL_CTL_ADD, listen_fd, &event) == -1) {
error(1, errno, "epoll_ctl add listen fd failed");
}
/* Buffer where events are returned */
events = calloc(MAXEVENTS, sizeof(event));
while (1) {
n = epoll_wait(efd, events, MAXEVENTS, -1);
printf("epoll_wait wakeup\n");
for (i = 0; i < n; i++) {
if ((events[i].events & EPOLLERR) ||
(events[i].events & EPOLLHUP) ||
(!(events[i].events & EPOLLIN))) {
fprintf(stderr, "epoll error\n");
close(events[i].data.fd);
continue;
}
// 处理监听套接字
else if (listen_fd == events[i].data.fd) {
struct sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int fd = accept(listen_fd, (struct sockaddr *) &ss, &slen);
if (fd < 0) {
error(1, errno, "accept failed");
} else {
make_nonblocking(fd);
event.data.fd = fd;
event.events = EPOLLIN | EPOLLET; //edge-triggered
if (epoll_ctl(efd, EPOLL_CTL_ADD, fd, &event) == -1) {
error(1, errno, "epoll_ctl add connection fd failed");
}
}
continue;
} else {
socket_fd = events[i].data.fd;
printf("get event on socket fd == %d \n", socket_fd);
while (1) {
char buf[512];
// 处理读事件
if ((n = read(socket_fd, buf, sizeof(buf))) < 0) {
// 读出错,关闭套接字
if (errno != EAGAIN) {
error(1, errno, "read error");
close(socket_fd);
}
break;
} else if (n == 0) {
close(socket_fd);
break;
} else {
for (i = 0; i < n; ++i) {
buf[i] = rot13_char(buf[i]);
}
if (write(socket_fd, buf, n) < 0) {
error(1, errno, "write error");
}
}
}
}
}
}
free(events);
close(listen_fd);
}这里会把每个套结字处理为非阻塞模式。
void make_nonblocking(int fd) {
fcntl(fd, F_SETFL, O_NONBLOCK);
}epoll ,非阻塞IO + IO多路复用 + 边缘触发,造就了C10K,C100K 的问题解决。
工作模型调整
以Nginx为例,Nginx是典型的1个主Master进程 + 多个Worker进程。
- 主进程执行 bind() 和 listen() 后,创建多个子进程。
- 每个子进程中通过都通过 accept() 或 epoll_wait() ,来处理相同的套接字。
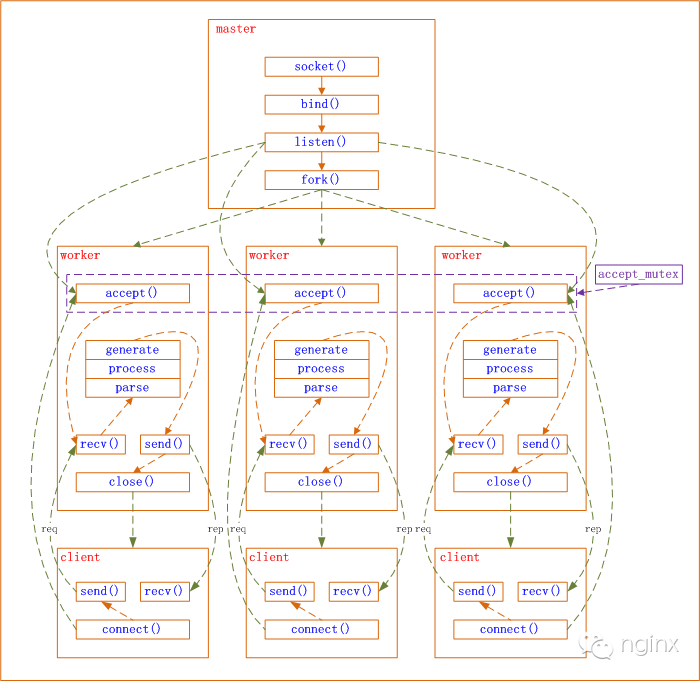
而这里面就需要用到epoll来作 IO 分法器。从而设计出基于套接字的事件驱动程序。
这样的模型被称为主从模型(master-worker) 或 反应堆模型(reactor),这样的技术核心思想有2点。 1、存在一个无限循环的事件分发线程或进程(Nginx是进程)。而事件分发的背后正是epoll这样的IO分发技术。
2、所有的IO操作可以抽象为事件,每个事件都有一个回调函数来处理。worker 进程上有已建立好的套接字、可读、可写的套接字。这一个个都是事件,通过事件分发并调用相应的回调函数被触发。
代码参考:https://github.com/froghui/yolanda/blob/master/chap-29/epoll-server-multithreads.c
//连接建立之后的callback
int onConnectionCompleted(struct tcp_connection *tcpConnection) {
printf("connection completed\n");
return 0;
}
//数据读到buffer之后的callback
int onMessage(struct buffer *input, struct tcp_connection *tcpConnection) {
printf("get message from tcp connection %s\n", tcpConnection->name);
printf("%s", input->data);
struct buffer *output = buffer_new();
int size = buffer_readable_size(input);
for (int i = 0; i < size; i++) {
buffer_append_char(output, rot13_char(buffer_read_char(input)));
}
tcp_connection_send_buffer(tcpConnection, output);
return 0;
}
//数据通过buffer写完之后的callback
int onWriteCompleted(struct tcp_connection *tcpConnection) {
printf("write completed\n");
return 0;
}
//连接关闭之后的callback
int onConnectionClosed(struct tcp_connection *tcpConnection) {
printf("connection closed\n");
return 0;
}
int main(int c, char **v) {
//主线程event_loop
struct event_loop *eventLoop = event_loop_init();
//初始化acceptor
struct acceptor *acceptor = acceptor_init(SERV_PORT);
//初始tcp_server,可以指定线程数目,这里线程是4,说明是一个acceptor线程,4个I/O线程,每一个I/O线程
//tcp_server自己带一个event_loop
struct TCPserver *tcpServer = tcp_server_init(eventLoop, acceptor, onConnectionCompleted, onMessage, onWriteCompleted, onConnectionClosed, 4);
tcp_server_start(tcpServer);
// main thread for acceptor
event_loop_run(eventLoop);
}这里设置了很多Callback回调函数,会在客户端建立连接之后依次执行这些回调函数。
event_loop_init():创建一个事件循环器acceptor_init(SERV_PORT): 初始化acceptor线程,bind、listentcp_server_init(): 创建线程池,传入回调函数,分别对应了连接建立完成、数据读取完成、数据发送完成、连接关闭完成几种操作,通过回调函数,让业务程序可以聚焦在业务层开发tcp_server_start(tcpServer): 开始监听,acceptor主线程,开启多个线程,同时把tcpServer作为参数传给channel对象event_loop_run(eventLoop): 调用dispatcher来进行事件分发,分发完回调事件处理函数
Linux 内核参数的调优
打开的最大文件描述符
Linux 下默认的最大文件描述符是1024个,也就是一个应用程序最多打开1024个文件描述符。如果连接数过多,会导致Socket/File:Can't open so many files
➜ ulimit -n
1024
➜ sudo echo "fs.file-max = 1000000" >> /etc/sysctl.conf
➜ sudo sysctl -p发送缓冲区的自动调节
Socket编程时是可以可以在send函数中设置发送缓冲区大小的,而这个应该设为多少才合适呢?答案是不要设置!不要设置!不要设置!
正确的操作是让操作系统自己动态的改变 发送缓冲区大小(默认就是操作系统自己控制的,但是应用程序一旦自己设置了缓冲区大小,自动调节功能就失效了)
➜ sysctl -a | grep tcp_moderate_rcvbuf
net.ipv4.tcp_moderate_rcvbuf = 1refer : 就是要你懂TCP–性能和发送接收Buffer的关系
C10M 的仰望
C10K、C100K、C1000K 都可以凭借强大的epoll解决问题。但是对性能的追求是永无止境的,同时并发1百万可能操作系统已经达到极限了,前面说到C10K的问题在于IO阻塞、频繁的CPU上下文切换、套接字从应用层到内核的反复拷贝。那 C10M 的瓶颈是什么呢?
究其根本,还是 Linux 内核协议栈做了太多太繁重的工作。从网卡中断带来的硬中断处理程序开始,到软中断中的各层网络协议处理,最后再到应用程序,这个路径实在是太长了,就会导致网络包的处理优化,到了一定程度后,就无法更进一步了。
要解决这个问题,最重要就是跳过内核协议栈的冗长路径,把网络包直接送到要处理的应用程序那里去。这里有两种常见的机制,DPDK 和 XDP。
DPDK:是用户态网络的标准。它跳过内核协议栈,直接由用户态进程通过轮询的方式,来处理网络接收。
XDP(eXpress Data Path),则是 Linux 内核提供的一种高性能网络数据路径。它允许网络包,在进入内核协议栈之前,就进行处理,也可以带来更高的性能。
比较牛的开源项目就是 iqiyi 的DPVS了,DPVS 是基于 DPDK 的高性能 Layer-4负载均衡器。它源自Linux虚拟服务器 LVS 及其修改阿里巴巴/LVS 。
refer:
- [-] https://cloud.tencent.com/developer/article/1373483
- [-]https://plantegg.github.io/2019/09/28/%E5%B0%B1%E6%98%AF%E8%A6%81%E4%BD%A0%E6%87%82TCP–%E6%80%A7%E8%83%BD%E5%92%8C%E5%8F%91%E9%80%81%E6%8E%A5%E6%94%B6Buffer%E7%9A%84%E5%85%B3%E7%B3%BB/
- [-] https://time.geekbang.org/column/intro/214
- [-] https://time.geekbang.org/column/article/81268
- [-] https://zhuanlan.zhihu.com/p/43720867