虚拟化-创建一个虚拟机
现如今,随着云计算技术的越来越成熟,我们在腾讯云、阿里云上购买的服务器本质上都是虚拟机,这就需要在一台物理服务器上虚拟化出更多的虚拟机,还要让这些虚拟机能够弹性伸缩,实现跨主机迁移。
而虚拟化技术正是这些能力的基石,而其中的核心技术就是 KVM 虚拟化技术。
虚拟化
虚拟化的本质是一种资源管理的技术,它可以通过各种技术手段把计算机的实体资源(如:CPU、RAM、存储、网络、I/O 等等)进行抽象和转换,让这些资源可以重新分割、排列与组合,实现最大化使用物理资源的目的。
服务器上的虚拟化软件,多使用 qemu ,其中 emu 是 emulator 模拟器的意思。单纯使用 qemu 采用的是完全虚拟化模式。但是完全虚拟化是非常低效的,所以要使用硬件辅助的虚拟化技术 Interl-VT,AMD-V,所以需要CPU 硬件开启这个标志位,一般是在 BIOS 里面设置。
当开启了标注位后,通过 KVM ,GuestOS 的指令不再用 Qemu 转译,直接运行,大大提高了速度。
CPU 虚拟化
为什么需要 CPU 虚拟化
X86 操作系统是设计在直接运行在裸硬件上的,x86 架构提供4个特权级别给内核(操作系统)来访问硬件,Ring 是指 CPU 的运行级别,Ring 0 是最高级别,依次到 Ring3。以 Linux x86 来说
- 操作系统(内核)需要直接访问硬件和内存,因此它的代码需要直接运行在最高级别 Ring 0 上,这样它就可以使用特权指令去控制中断,修改页表,访问设备。
- 应用程序的代码运行在 Ring 3 上,如果需要访问硬件,必须通过系统调用,执行系统调用的时候,CPU 的运行级别会从 Ring3 切换到 Ring0 ,并跳转到系统调用对应的内核代码位置执行,完成后从 Ring3 回到 Ring0。这个过程就是用户态到内核态的转换。
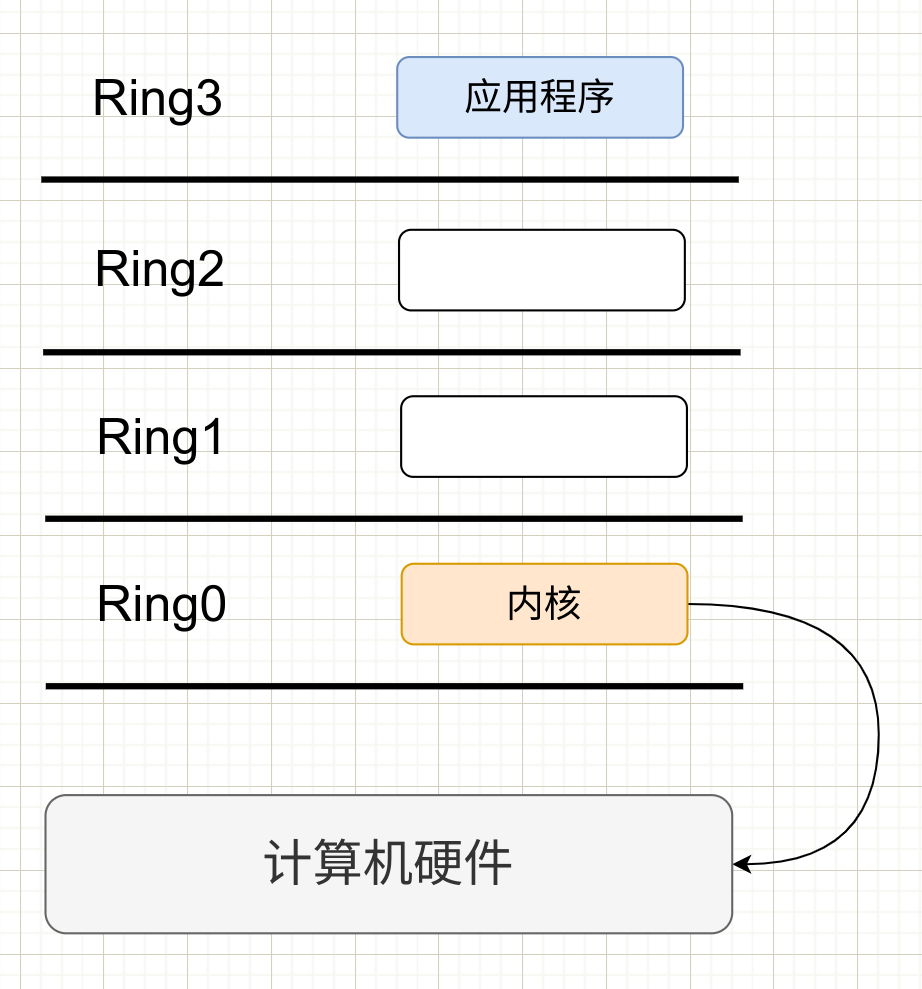
那么,虚拟化在这里就遇到了一个难题。由于宿主机的操作系统工作于 Ring0,VM 客户机操作系统就不能再工作在 Ring0 上了,但是 VM 客户机的内核操作系统不知道这一点,以前执行什么指令,现在还是执行什么指令。但是没有执行权限会出错。这时 VMM(虚拟机管理程序)就要开始工作了,虚拟机通过 VMM 实现 Guest CPU 对硬件的访问,根据原理有三种实现技术:
- 完全虚拟化
- 半虚拟化
- 硬件辅助的虚拟化
完全虚拟化
完全虚拟化(Full virtualization) 是基于二进制翻译的全虚拟化(Full Virtualization with Binary Translation)。客户操作系统运行在 Ring 1,他在执行特权指令时,会触发异常(CPU的机制,没权限的指令会触发异常),然后 VMM 捕获这个异常,在这个异常里面做翻译,模拟,最后返回到 VM 客户操作系统内,客户操作系统认为自己的特权指令工作正常,继续运行。但是这个性能损耗非常大。
本质上经历了 “异常捕获 (trap)” – “翻译(handle)” – “模拟(emulate)” 过程:
一种完全由软件模拟假的 CPU、内存、网络、硬盘等,让虚拟机认为自己是个真正的内核。缺点是慢,由于虚拟化软件一直在转译虚拟机的内核系统操作。

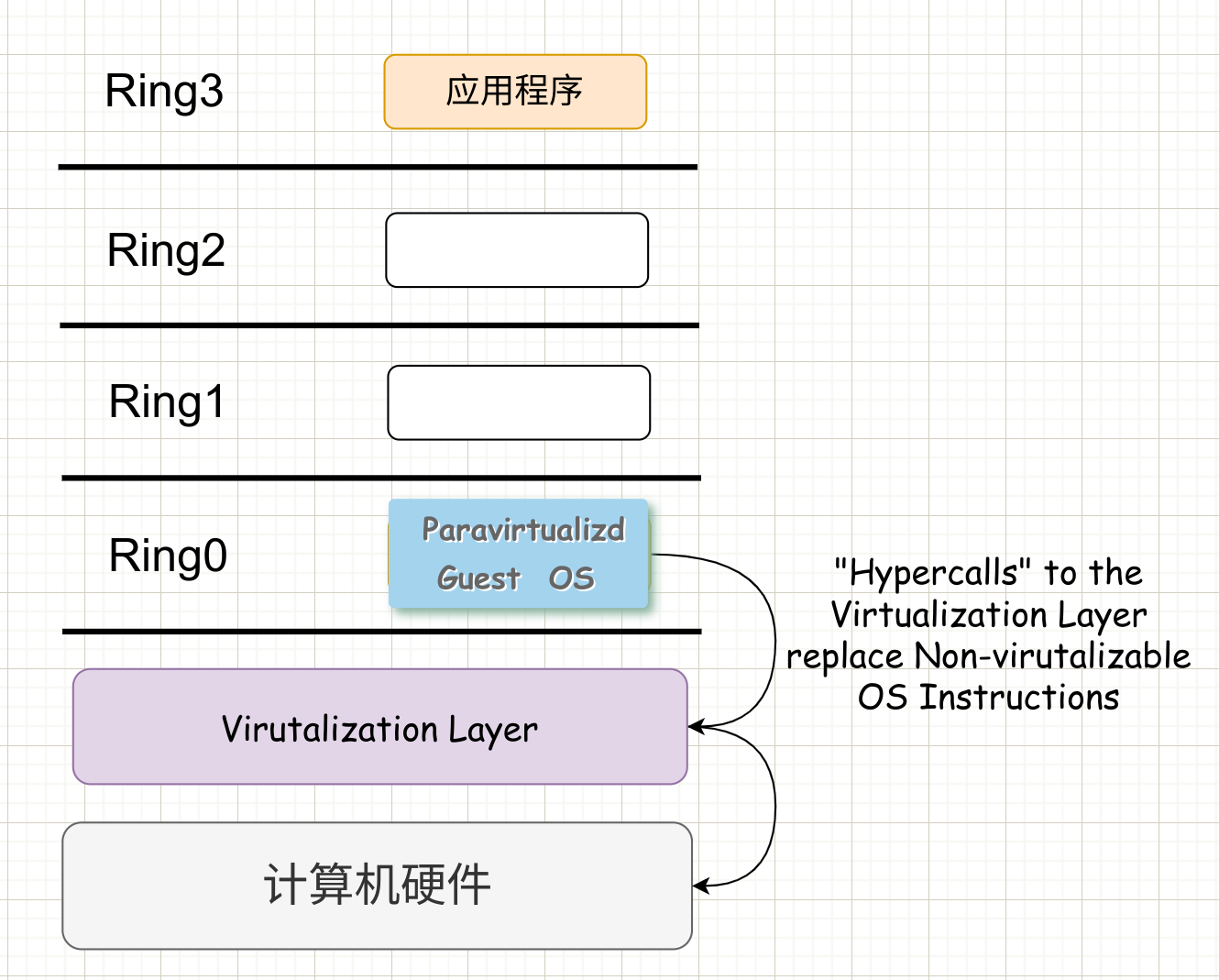
半虚拟化
半虚拟化(Paravirualization) 的思想是修改操作系统内核,替换掉不能虚拟化的指令,通过超级调用(hypercall)直接和底层的虚拟化层 hypervisor 来通信,hypervisor 同时也提供了超级调用接口来满足其他的内核操作,如内存管理、中断等。
这种做法省去了全虚拟化中的捕获和模拟,大大提高了效率。所以如 XEN 这种半虚拟化技术,客户机操作系统有一个专门的定制内核版本,就不会有捕获异常、翻译、模拟的过程了。这就是 XEN 这种半虚拟化架构的优势,也是为什么XEN只支持虚拟化Linux,无法虚拟化 windows 的原因。因为 微软 Windows 的不改内核代码,不支持hypercall。
本质上,用软件接口来代替实际的硬件的功能。比如,半虚拟化提供一组虚拟化调用,当在虚拟操作系统中的进程需要使用系统调用时,这个时候进程就会向虚拟机管理程序请求这组虚拟化的调用,来达到类似于系统调用的效果。
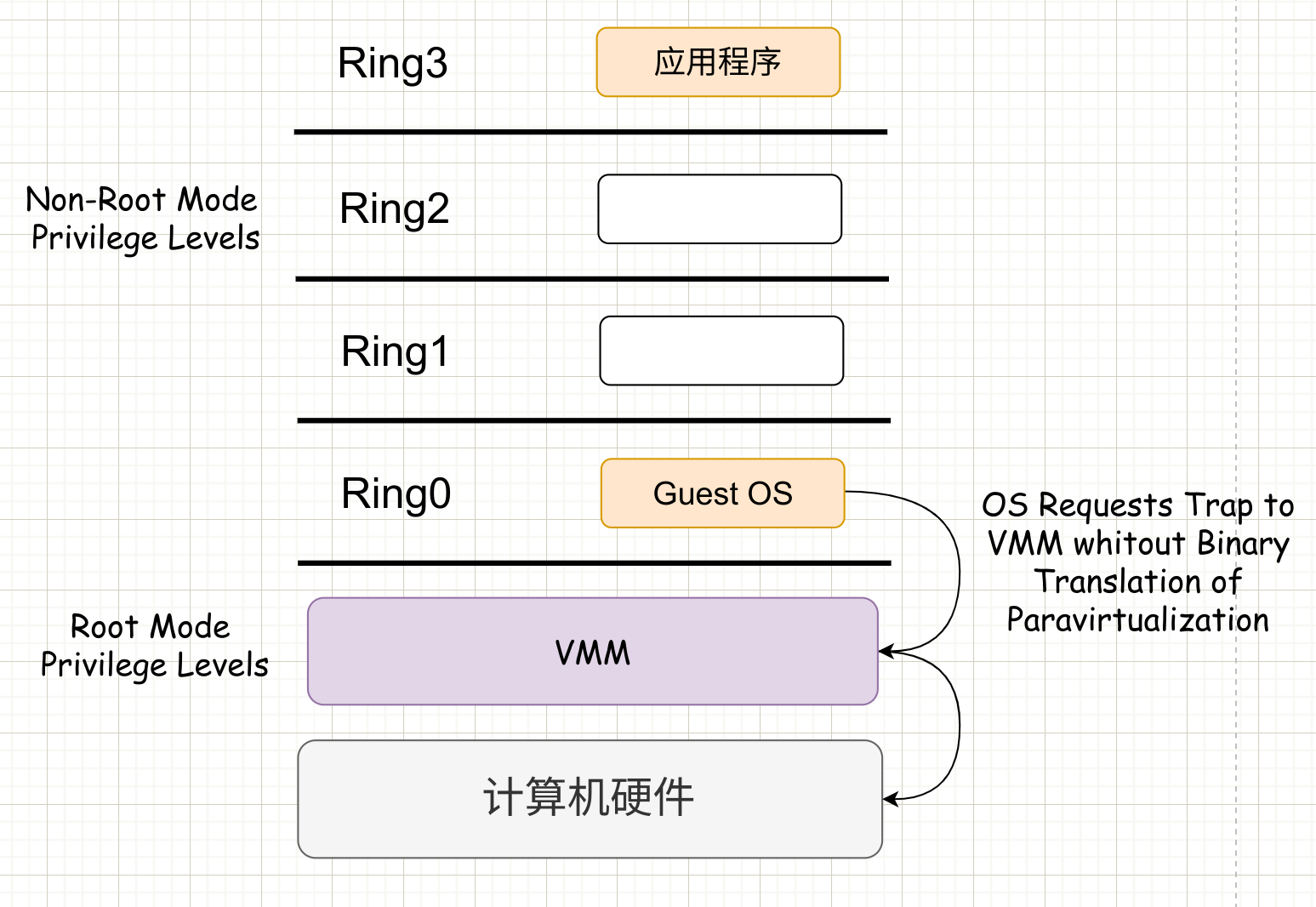
硬件辅助虚拟化
2005 年之后,CPU 厂商如 intel 和 AMD 开始支持了虚拟化,intel 引入了 Intel-VT(Virtualization Technology)技术。这种CPU支持 Ring 0-4 4个运行级别。有 VMX root operation 和 VMX non-root operation两种模式。
这样,VMM 可以运行在 VMX root operation模式下,客户 OS 运行在VMX non-root operation模式下。
这两种操作模式可以互相转换,运行在 VMX root operation 模式下的 VMM 通过显式调用指令切换到 VMX non-root operation 模式,硬件自动加载 Guest OS 的上下文,于是 Guest OS 获得运行,这种转换称为 VM entry。Guest OS 运行过程中遇到需要 VMM 处理的事件。例如外部的中断或缺页异常,或者主动调用 VMCALL 指令调用 VMM 的服务时(与系统调用类似),硬件自动挂起 Guest OS,切换到 VMX root operation 模式,恢复 VMM 的运行。这种转换称为 VM exit。VMX root operation 模式下的软件行为与在没有 VT-x 技术的处理器上的行为基本一致; 而在 VMX non-root operation 模式则有很大不同,最主要的区别是此时运行某些指令或遇到某些事件时,发生 VM exit。
本质上,硬件这层做了区分,这样的硬件辅助的全虚拟化性能呢高逼近半虚拟化,再加上全虚拟化不要修改客户机操作系统这一优势,硬件辅助虚拟化技术应该是未来的发展趋势。
| 全虚拟化 | 半虚拟化 | 硬件辅助虚拟化 | |
|---|---|---|---|
| 实现技术 | BT 和 直接执行 | Hypercall | 遇到特权指令切换到 root 模式下执行 |
| 客户操作系统修改/兼容性 | 无需修改客户机内核,最佳兼容性 | 客户操作系统需要修改来支持 hypercakk,不支持 windows 兼容性差 | 无需修改客户机内核,最佳兼容性 |
| 性能 | 差 | 好,半虚拟化下的CPU性能开销几乎为0,虚拟机的性能接近于物理机 | CPU 需要在两种模式下切换,带来了性能开销,但是其性能在逐渐逼近半虚拟化 |
| 应用厂商 | VMware Workstation 、QEMU、Virtual PC | Xen | Vmware ESXi、Microsoft Hyper-V、Xen 3.0 、KVM |
图片出自论文《Residency-Aware Virtual Machine Communication Optimization: Design Choices and Techniques》)
内存虚拟化
CPU和内存是紧密结合的,因而内存虚拟化和CPU虚拟化是一起完成的。KVM 实现客户机内存的方式是利用 mmap 系统调用,在QEMU 主线程的虚拟地址空间中声明一段连续大小的空间用于客户机物理内存的映射。
VMM 内存虚拟化实现方式有两种:
- 软件方式:通过软件实现内存地址的翻译,比如 Shadow page tabe (影子页表)
- 硬件实现:基于CPU 的辅助虚拟化功能呢高,比如 AMD 的 NPT 和 Intel 的 EPT 技术。
在KVM 中,虚机的物理内存即为 qemu-kvm 进程所占用的内存空间,内存虚拟化也是需要用户态 qemu 和内核态的 KVM 共同完成,为了加速内存映射,需要借助硬件的 EPT 技术。
intel 的 EPT (Extent Page Table,扩展页表)在原有客户机页表对客户机虚拟地址到客户机物理地址映射的基础上,又引入了 EPT 页表来实现客户机物理地址到宿主机物理地址的另一次映射。
有了EPT,在客户机物理地址到宿主机物理地址的转换过程中,缺页会产生 EPT 缺页异常。KVM 首先根据引起异常的客户机物理地址,映射到对应宿主机的虚拟地址,然后为此虚拟地址分配新的物理页,最后KVM 再更新 EPT 页表,建立起客户机物理地址到宿主机地址之间的映射。
KVM 只需为每个客户机维护一套 EPT 页表,也大大减少了内存的开销。
在用户态的 qemu 中,有一个结构 AdressSpace address_space_memory 来表示虚拟机的系统内存,这个内存可能包含多个内存区域 struct MemoryRegion,组成树型结构,指向mmap 分配的虚拟内存。
和用户态 qemu 对应的内核 KVM,对于虚拟机有一个结构 struct kvm 表示该虚拟机,这个结构会指向一个数组的 struct kvm_memory_slot 表示虚拟机的多个内存条,kvm_memory_slot 中有起始页号,页面数目,表示这个虚拟机的物理内存空间。
虚拟机的物理内存空间里面的页面当然不是一开始就映射到物理页面的,只有当虚拟机的内存被访问的时候,也即 mmap 分配的虚拟内存空间被访问的时候,先查看 EPT 页表,是否已经映射过,如果已经映射过,则经过 四级 页表映射,就能访问到物理的页面。
如果没有映射过,则虚拟机会通过 VM-Exit 指令回到宿主机模式,通过 handle_ept_violation 补充页表映射,先是通过 handle_mm_fault 为虚拟机的物理内存空间分配真正的物理页面,然后通过 __direct_map 添加 EPT 页表映射。
存储虚拟化
在虚拟化技术的早期,不同的虚拟化技术会针对不同的硬盘设备和网络设备实现不同的驱动,虚拟机里面也要根据不同的虚拟化技术和物理存储和网络设备,选择加载不同的驱动。但是由于硬盘设备和网络设备太多了。后来形成了一定的接口标准,就是 virtio,就是 虚拟化 I/O 设备 的意思。
virtio 负责对虚拟机提供统一的接口,有点 VFS 的那种味道。
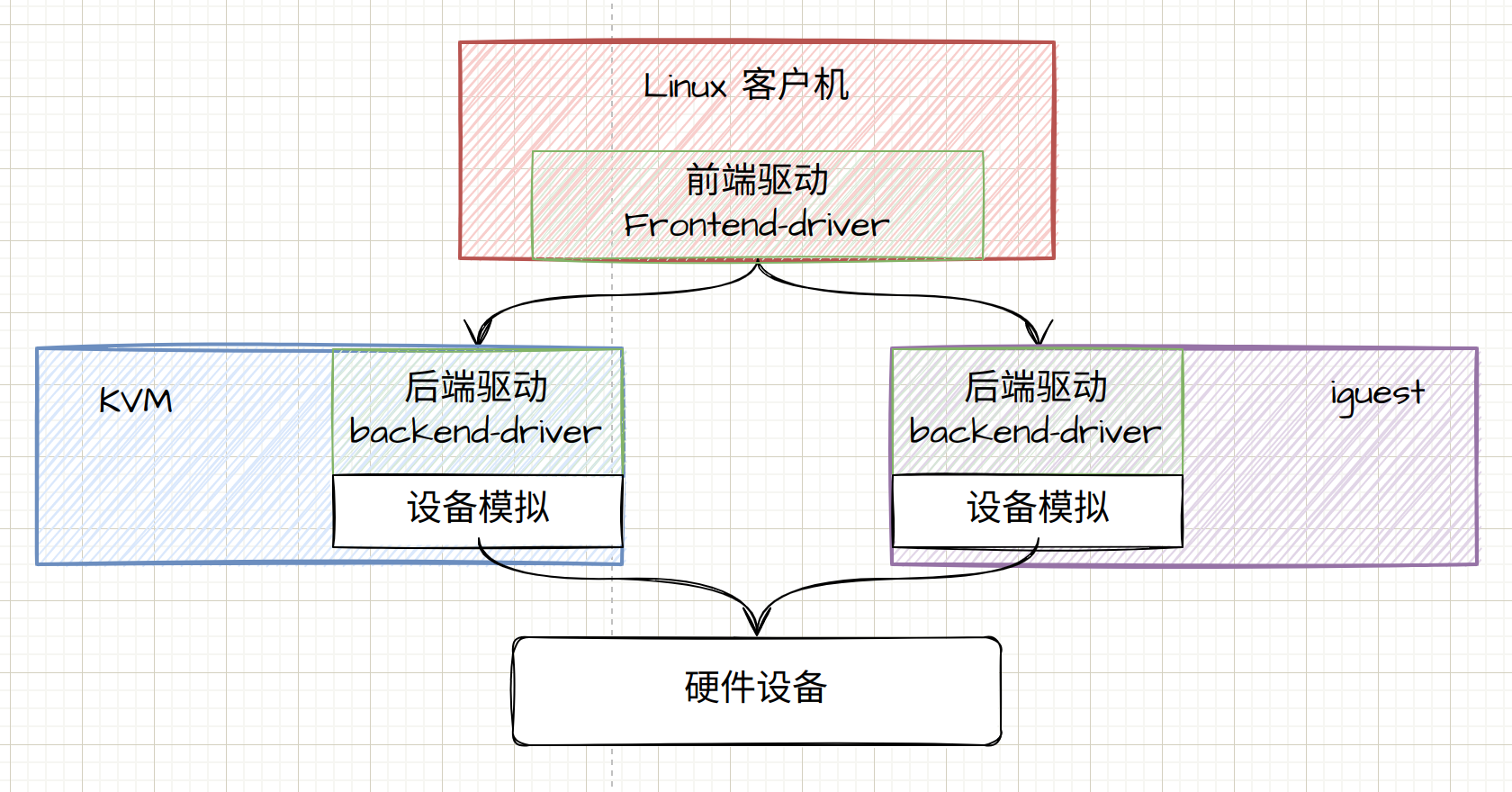
虚拟机外,可以实现不同的virtio 后端,来适配各种不同的物理硬件。
virtio 的结构分为四层。
- 在虚拟机里面的 virtio 前端,针对不同类型的设备有不同的驱动程序,但是接口都是统一的,例如,硬盘的 virtio_blk,网络就是 virtio_net。
- 在宿主机的 qemu 里面,实现 virtio 后端的逻辑,主要是操作硬件的设备,例如通过写一个物理机硬盘上的文件来完成虚拟机写入硬盘的操作,再如向内核协议栈发送一个网络包完成虚拟机对于网络的操作。
- 在 virtio 的前端和后端之间,有一个通信层,里面包含 virtio 层 和 virtio-ring 层。virtio 这一层实现的是虚拟队列接口,而 virtio-ring 层算是前后端通信的桥梁。
存储虚拟化的过程就被分为了前端、后端和中间队列。
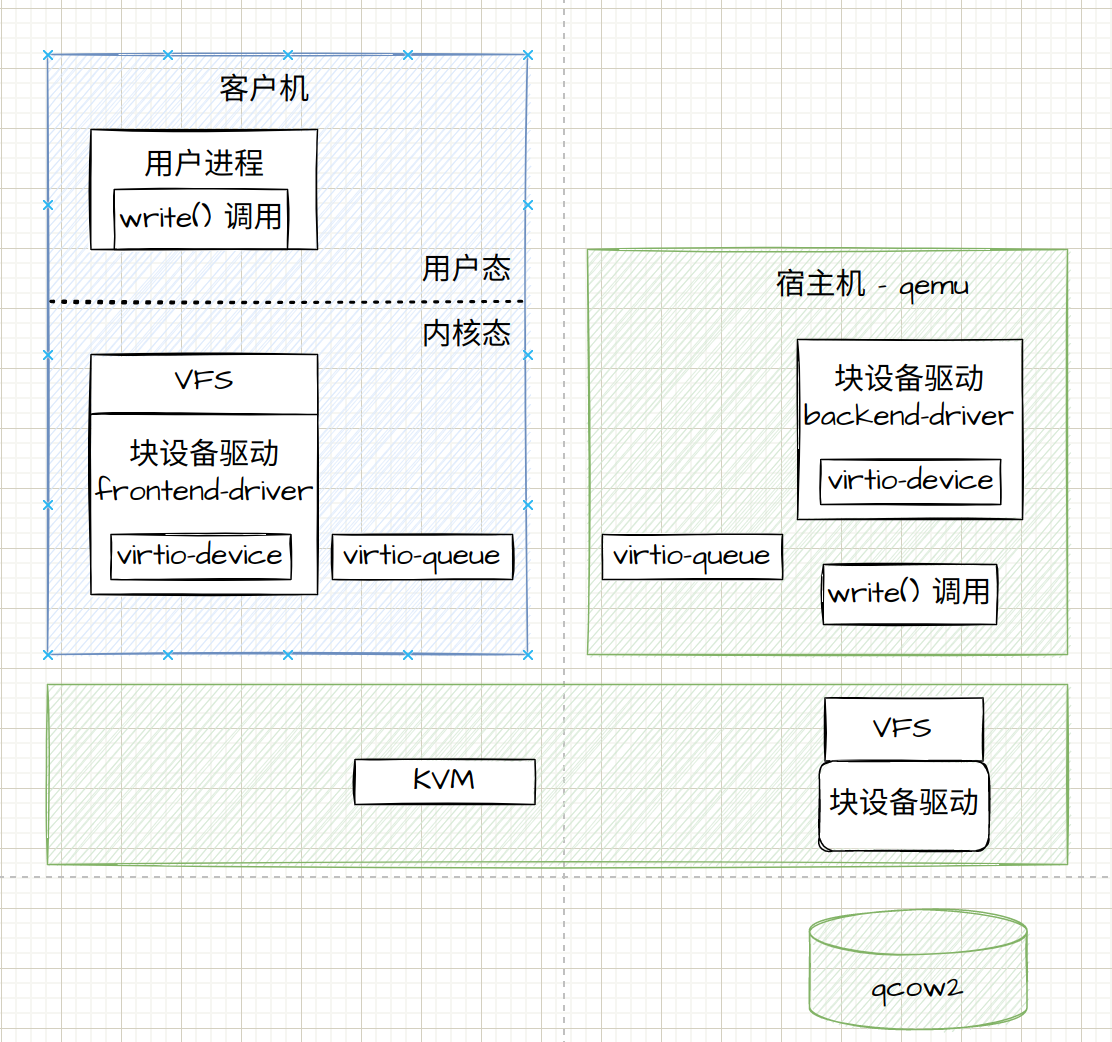
- 前端的块设备驱动 Front-end driver 在客户机的内核里面,它符合普通设备驱动的格式,对外通过 VFS 暴露系统接口给客户机里面的应用。
- 后端设备驱动 Back-end driver,在宿主机的 qemu 进程中,当受到客户机的写入请求时,调用文件系统的 write 函数,写入宿主机的 VFS 文件系统,最终写到物理硬盘设备的 qcow2 文件。
- 中间队列用于前端和后端之间的传输数据,有 virt-queue 管理这些队列。
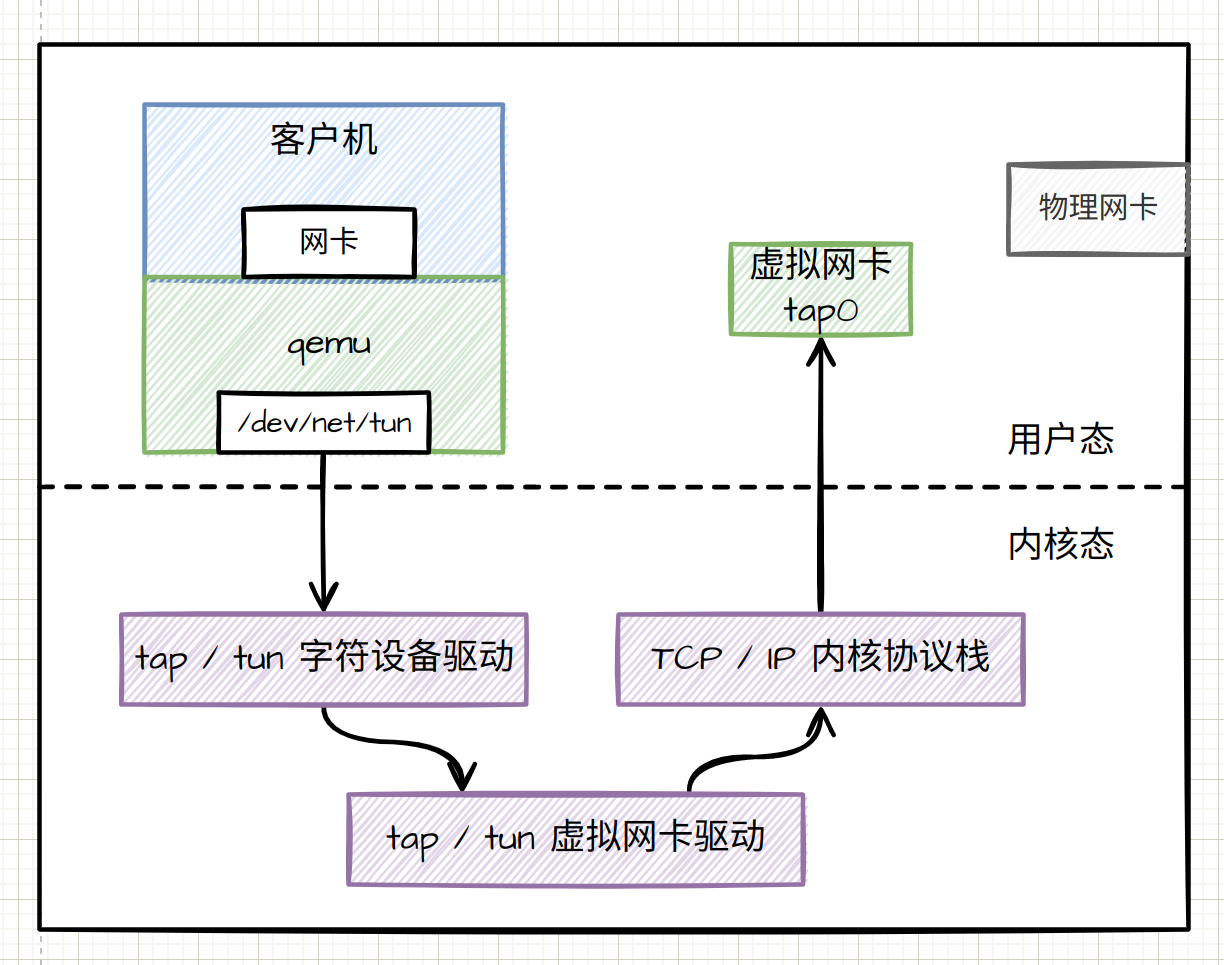
网络虚拟化
和磁盘虚拟化差不太多,网络虚拟化也是 write() 系统调用,只不过其写入的是socket 套接字中,在写入内容经过 VFS 、内核协议栈,达到虚拟机里面的内核网络驱动设备,也即 virtio_net。
一般我们在虚拟化网络使用的是 tap\tun 模式,本身是模拟了一对网卡,两张卡被一个虚拟的网线链接着。
在 tap_open 中,我们打开了一个文件 “/dev/net/tun”,然后通过 ioctl 操作这个文件,这是 Linux 内核的一项机制,和 KVM 机制很像,其实这就是一种打开这个字符设备文件,然后通过 ioctl 操作这个文件和内核打交道,来使用内核的能力。
创建一个虚拟机
Qemu / KVM 是目前最流行的虚拟化技术,它基于 Linux 内核提供的 kvm 模块,结构精简、性能损失小而且免费开源。
目前各大云厂商的虚拟化方案,新的服务器实例都是基于 KVM 技术。
CLI 命令行
- qemu-kvm:qemu 和 kvm 的结合,KVM 负责 CPU 虚拟化+内存虚拟化,qemu 负责模拟其他 I/O 设备。
- qemu-img:qemu 的磁盘管理工具
- virsh (属于libvirtd):虚拟机的管理工具包,支持 kvm、xen、vmware 等。有列出当前虚拟机、启动、关停、重启等多个功能。
- virt-image:用于从XML描述文件中创建出一个虚拟机。
- virt-convert:可以将OVF或VMX文件转换为 KVM 的支持格式。
- virt-clone:克隆一个虚拟机
- virt-install:安装一个虚拟机
- virt-viewer:最小化虚拟机图形界面展示工具,支持 VNC 和 SPICE 两种远程协议
- virt-manager:是一套虚拟机的桌面管理器,像VMware的vCenter和xenCenter差不多,工具提供了虚拟机管理的基本功能,如开机,挂起,重启,关机,强制关机/重启,迁移等。
libvirt 是目前使用最为广泛的针对KVM虚拟机进行管理的工具和API。Libvirtd是一个daemon进程,可以被本地和远程的virsh(命令行工具)调用,Libvirtd通过调用qemu-kvm操作管理虚拟机。libvirt 由应用程序编程接口 (API) 库、一个守护进程 (libvirtd),和默认命令行实用工具 (virsh)等部分组成。
准备环境
Ubuntu 20.04 、40G 硬盘、4G 内存
VMware WorkStation
磁盘镜像:cirros (下载地址 cirros-0.3.0-x86_64-disk.img)
nocloud 版本 cirros (下载地址 cirros-0.4.0-x86_64-nocloud.img)
cirros 是一个极简版的操作系统,特别适合在云环境运行,第一次启动时会从云上联网下载一堆东西,为了跳过这个过程,推荐使用 nocloud 版本。
安装工具
$ sudo apt-get install qemu-kvm
$ sudo apt-get install uml-utilities # tunctl 工具创建 tap/tun 网卡对
$ sudo apt-get install bridge-utils # brctl 工具创建网桥这里有两个比较重要的命令 qemu-system-x86_64 和 qemu-img 。
Vmware 和 虚拟机中再安装 ubuntu 这步就省了。
这里我使用的是 Vmware 安装的虚拟机,因为是虚拟机里再安装虚拟机,记得要开启虚拟嵌套。
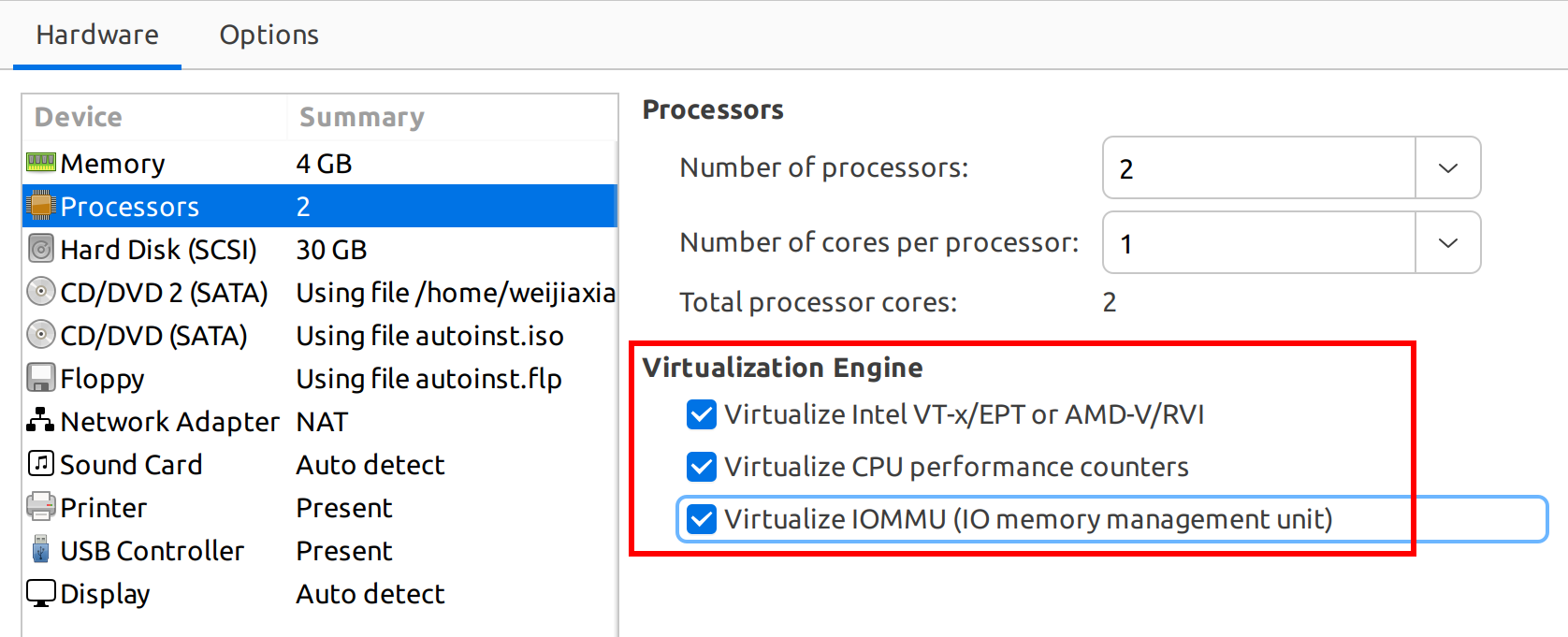
使用 grep -E --color '(vmx|vms)' /proc/cpuinfo 命令如果可以看到输出则表示开启了硬件支持虚拟化。
另外需要注意的是 kvm 内核模块需要加载成功。
$ lsmod|grep kvm
kvm_intel 282624 0
kvm 663552 1 kvm_intelqemu 模拟
- 模拟CPU
可以产看可以模拟的 CPU架构。
$ qemu-system-x86_64 -cpu ?
Available CPUs:
x86 486 (alias configured by machine type)
x86 486-v1
x86 Broadwell (alias configured by machine type)
x86 Broadwell-IBRS (alias of Broadwell-v3)
x86 Broadwell-noTSX (alias of Broadwell-v2)
x86 Broadwell-noTSX-IBRS (alias of Broadwell-v4)
...使用 -cpu 指定模拟的 cpu,如 -cpu core2duo。(Intel 酷睿2 45nm 工艺芯片)
注意:-smp 才是指定cpu的核数。
- 模拟 disk
使用 qemu-system-x86_64 的 drive 选项指定如 if=vritio,来支持高级的版虚拟化技术。(-hda 选项不能和高级的drive同时使用,hda很初级)
查看 磁盘镜像的格式:
$ qemu-img info cirros-0.3.0-x86_64-disk.img
image: cirros-0.3.0-x86_64-disk.img
file format: qcow2
virtual size: 39.2 MiB (41126400 bytes)
disk size: 10.1 MiB
cluster_size: 65536
Format specific information:
compat: 0.10
refcount bits: 16qcow2镜像是qemu的一种镜像格式,是’qemu copy on write’的简写。相比 raw 格式有很多高级功能支持。
qemu-system-x86_64 的其他选项
- -name name:指定虚拟机的名称
- -M machine:指定虚拟机的主机类型,如 standerd PC,ISA-only,PC 或者 intel-Mac 等。
- -m megs:指定虚拟机RAM大小
- -cpu :指定 cpu 的模拟类型
- -smp n:指定CPU的核心数以及CPU的socket 数目
- -numa opts:指定模拟多节点的 numa 设备
- -cdrom file:指定file 作为 CD-ROM 镜像
- -hda/-hdb/-hdc/-hdd :客户机指定块设备存储,指定客户机中的第一个 IDE 设备。
- -drive [file=file][,if=type][,bus=n][,unit=m][,media=d]:详细定义一个存储驱动器。
- -boot [order=drivers][,once=drives] :定义设备的引导次序,每种设备使用一个字符表示,a,b 表示软驱,c表示地一块硬盘,d表示第一个光驱,n-p表示网络适配器
- -net nic [,vlan=n][,netdev=nd][,macaddr=mac][,model=type][,name=str][,addr=str]:创建客户机的网卡
- -netdev tap[,id=str][ifname=name][,script=file][,downscript=dfile]:创建一个tap设备作为后端,这个tap设备可以连接到bridge、fd、vhost 等设备或者为虚拟机的网络接口创造数据包通路
- -nographic 禁止 vnc,直接在终端上打印
启动我的第一个虚拟机
$ qemu-system-x86_64 -m 128 -smp 2 -name test \
-hda cirros-0.4.0-x86_64-nocloud.img \
-nographic一段系统启动的加载之后,可以看到如下的输出(cirros的镜像是网上找的似乎某个教育机构的,登陆密码有写)
=== datasource: None None ===
=== cirros: current=0.4.0 latest=0.4.0 uptime=10.63 ===
____ ____ ____
/ __/ __ ____ ____ / __ \/ __/
/ /__ / // __// __// /_/ /\ \
\___//_//_/ /_/ \____/___/
http://cirros-cloud.net
login as 'root' user. default password: 'byte-edu.com'.
cirros login:这里用的是 nographic 模式,如果想要图形界面连上虚拟机,就需要安装一个 vncviewer,ubuntu 下可以使用 sudo apt install vncviewer
创建一个 Ubuntu 虚拟机
- 创建虚拟磁盘映像文件
# qemu-img create -o size=5G,preallocation=metadata -f qcow2 ubuntu-mini.qcow2
Formatting 'ubuntu-mini.qcow2', fmt=qcow2 size=5368709120 cluster_size=65536 preallocation=metadata lazy_refcounts=off refcount_bits=16
# ll -h
total 976K
drwxr-xr-x 2 root root 4.0K Aug 21 23:46 ./
drwx------ 7 root root 4.0K Aug 21 23:46 ../
-rw-r--r-- 1 root root 5.1G Aug 21 23:44 ubuntu-mini.qcow2
# du -sh ubuntu-mini.qcow2
968K ubuntu-mini.qcow2- 以创建好的磁盘映像启动虚拟机
$ qemu-system-x86_64 -m 1024 -smp 2 -name 'ubuntu-mini' -enable-kvm \
-drive file=/root/virtual_machine/ubuntu-mini.qcow2,if=virtio,media=disk,format=qcow2 \
-drive file=/root/images/ubuntu-20.04-live-server-amd64.iso,media=cdrom \
-boot order=dc,once=d \
--vnc 0.0.0.0:0- 在物理主机上使用 VNC 连上虚拟机
vncviewer 172.16.101.136:5900
- 为虚拟机加上网络功能
网络这块似乎有点问题,放到后面学 OVS 的时候再细看。
# 在 Host 机器上创建一个 bridge br0
brctl addbr br0
# 将br0 设为 up
ip link set br0 up
# 给 br0 设置一个IP
ifconfig br0 192.168.10.1/24
# 创建 tap device
tunctl -b
# 将tap0 设为 up
ip link set tap0 up
# 将tap0加入到br0
brctl addif br0 tap0
# 启动虚拟机,虚拟机连接 tap0,tap0 连接 br0
qemu-system-x86_64 -m 1024 -smp 2 -name 'ubuntu-mini' -enable-kvm \
-drive file=/root/virtual_machine/ubuntu-mini.qcow2,if=virtio,media=disk,format=qcow2 \
-net nic,model=virtio -net tap,ifname=tap0,script=no,downscript=no \
--vnc 0.0.0.0:0如下是一个 开源云平台软件 OpenStack 创建出来的 KVM 参数,如下所示:
qemu-system-x86_64
-enable-kvm
-name instance-00000024
-machine pc-i440fx-trusty,accel=kvm,usb=off
-cpu SandyBridge,+erms,+smep,+fsgsbase,+pdpe1gb,+rdrand,+f16c,+osxsave,+dca,+pcid,+pdcm,+xtpr,+tm2,+est,+smx,+vmx,+ds_cpl,+monitor,+dtes64,+pbe,+tm,+ht,+ss,+acpi,+ds,+vme
-m 2048
-smp 1,sockets=1,cores=1,threads=1
......
-rtc base=utc,driftfix=slew
-drive file=/var/lib/nova/instances/1f8e6f7e-5a70-4780-89c1-464dc0e7f308/disk,if=none,id=drive-virtio-disk0,format=qcow2,cache=none
-device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x4,drive=drive-virtio-disk0,id=virtio-disk0,bootindex=1
-netdev tap,fd=32,id=hostnet0,vhost=on,vhostfd=37
-device virtio-net-pci,netdev=hostnet0,id=net0,mac=fa:16:3e:d1:2d:99,bus=pci.0,addr=0x3
-chardev file,id=charserial0,path=/var/lib/nova/instances/1f8e6f7e-5a70-4780-89c1-464dc0e7f308/console.log
-vnc 0.0.0.0:12
-device cirrus-vga,id=video0,bus=pci.0,addr=0x2参考